Понад 178 000 користувачів GitHub поставили зірку одному markdown-файлу. Файл просто пояснює AI, як поводитися.
Чотири правила: спершу думай, потім кодуй. Простота передусім. Хірургічні зміни. Виконання, орієнтоване на ціль. Ось і все. Жодної бібліотеки. Жодного фреймворку. Жодного інсталятора. Forrest Chang упакував спостереження Andrej Karpathy щодо режимів помилок LLM при кодуванні в один файл CLAUDE.md, і спільнота розробників у наступні місяці підняла його понад 178 000 зірок на GitHub.
Якщо придивитися до того, що там сталося, це дуже схоже на те, до чого кожна інженерна організація рано чи пізно доходила після достатнього болю: спільний набір обмежень щодо того, як пишеться код. Шар правил. Те, що раніше жило в чек-листі рев'ю коду, або в посібнику зі стилю, або в інституційній пам'яті старшого інженера. Спільнота vibe-кодингу знайшла набагато легшу версію тієї самої дисципліни: запиши правила в markdown і дай агенту прочитати їх, перш ніж він напише код.
Це не разовий випадок. Це патерн.
TL;DR
- Екосистема інструкцій для агентів (CLAUDE.md, AGENTS.md, спільні бібліотеки скілів і агенти доступності) стає розподіленим шаром забезпечення якості для кодування з допомогою AI.
- Розрив у якості, на який вона реагує, реальний: Snyk просканував 3984 скіли з ClawHub і skills.sh і виявив, що 1467, або 36,82%, мали щонайменше один недолік безпеки; 534, або 13,4%, мали щонайменше одну проблему критичного рівня.
- Відповіддю спільноти стало будувати більше правил, а не відмовлятися від підходу, і тепер залучені інституції від Vercel до OWASP та Linux Foundation.
Розрив у якості реальний, і спільнота це знає

13,4% файлів скілів спільноти містять критичні недоліки безпеки. Це з звіту ToxicSkills від Snyk, опублікованого в лютому 2026 року після сканування 3984 скілів з ClawHub і skills.sh. 36,82% мали щонайменше одну вразливість безпеки. 76 були відверто шкідливими, причому 91% з них використовували prompt injection як механізм доставки.
Ширша картина якості AI-коду схожа. Згідно з аналізом даних рев'ю коду від CodeRabbit, код, написаний із допомогою AI, у середньому має 10,83 проблеми на pull request проти 6,45 для коду, написаного людиною, — приблизно в 1,7 раза більше проблем. Щорічне дослідження коду від GitClear повідомило про те, що вони називають «4-кратним зростанням» клонування коду: підвищення з 8,3% до 12,3% змінених рядків між 2021 і 2024 роками.
Це цифри від вендорів, тож ставтеся до точності з належним скепсисом. Утім, вони корисні з погляду напряму: кодування з допомогою AI створює достатній тиск на якість, щоб розробники будували навколо нього нові запобіжники.
Важливо те, що спільнота зробила з цією інформацією. Відповіддю було не «файли скілів небезпечні, припиніть ними користуватися». Вона була такою: OWASP запустив Agentic Skills Top 10 (AST10), еквівалент Web Application Security Top 10 для екосистеми скілів. Більше правил. Більше структури. Формальний фреймворк безпеки для неформальної екосистеми.
Це класична інженерна відповідь, навіть від спільноти, яка часто намагається уникати важких процесів.
Екосистема, що з'явилася

Протягом першої половини 2026 року це стало схоже менше на жменю ізольованих markdown-файлів і більше на багаторівневу екосистему.
Почнімо з шару поведінки. Натхненний Karpathy файл CLAUDE.md упаковує версію Forrest Chang спостережень Andrej Karpathy щодо режимів помилок LLM при кодуванні в один файл інструкцій, і тепер він має понад 178 000 зірок на GitHub, один із найзірковіших репозиторіїв в історії GitHub, для файлу, побудованого навколо чотирьох простих правил. Те, якими є ці правила, менш цікаве, ніж те, що вони репрезентують: спробу закодувати судження, які старший інженер застосовував би під час рев'ю коду.
Над цим розташований шар агрегації спільноти. Antigravity Awesome Skills перетнув позначку в 1595+ агентних скілів, збираючи багаторазові плейбуки для Claude Code, Cursor, Codex CLI, Gemini CLI, Antigravity та інших AI-асистентів кодування. Він функціонує як швидкоплинна спільна бібліотека для цієї сфери: те, що міг би видати комітет зі стандартизації, якби рухався через GitHub, а не через PDF.
Потім з'явилися фреймворки. Vercel зробив vercel-labs/agent-skills офіційним репозиторієм організації, тепер із 28 000 зірок. Лише скіл React Best Practices містить 40+ правил у восьми категоріях, орієнтованих на продуктивність, зокрема waterfalls, розмір бандла, продуктивність на стороні сервера, отримання даних на стороні клієнта, оптимізацію повторного рендерингу, продуктивність рендерингу та мікрооптимізації JavaScript. Коли компанія, що володіє вашою платформою для розгортання, постачає офіційні правила якості для AI-агентів, екосистема перейшла від експерименту спільноти до продакшн-інфраструктури.
А на самій вершині — шар стандартів. OpenAI передала специфікацію AGENTS.md Agentic AI Foundation (AAIF) при Linux Foundation поряд з MCP (Anthropic) і Goose (Block): кросінструментальну, кросагентну, на шляху до стандарту. Напрям — до портативності: AGENTS.md дає командам спільне місце для проєктно-специфічних вказівок агентам, навіть якщо окремі інструменти все ще можуть відрізнятися в тому, як вони завантажують і застосовують ці інструкції.
Ці частини з'явилися не як єдиний централізовано спланований стек. Вони збіглися, бо попит був реальним.
Вимір, про який ніхто не говорить
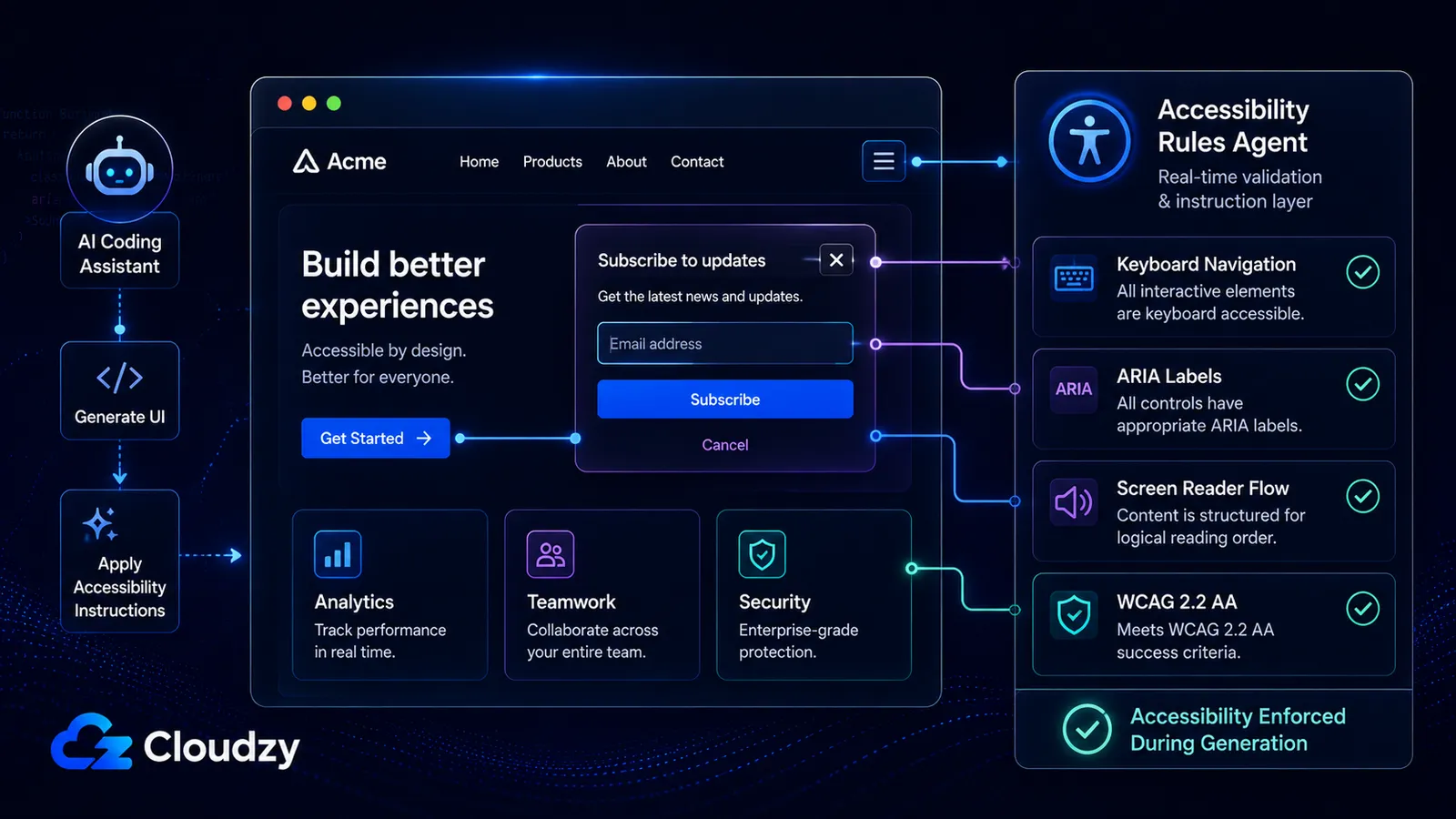
Дані щодо безпеки та якості коду висвітлюються. Вимір доступності — майже ніколи.
Community-Access/accessibility-agents стартував 21 лютого 2026 року з шістьма агентами. Станом на червень 2026 року: 79 спеціалізованих агентів у восьми командах, 18 багаторазових скілів доступності, націлювання на WCAG 2.2 AA і підтримка на п'яти платформах: Claude Code, GitHub Copilot, Gemini CLI, Codex CLI та MCP Server, який може обслуговувати MCP-сумісних клієнтів.
Що це за проєкт, простими словами: спільнота розробників вирішила, що AI-інструменти кодування за замовчуванням генерують недоступний код (вони пропускають правила ARIA, ігнорують навігацію з клавіатури, створюють модальні вікна, що ловлять у пастку зчитувачі екрана), і збудувала 79 спеціалізованих агентів, щоб забезпечити дотримання правил, які AI постійно забуває.
Це визначна річ. Фронтенд-інженери історично недопрацьовували з доступністю. Це перше, що ріжуть під тиском дедлайнів. Проєкт accessibility-agents — це vibe-кодери, які пишуть правила, для забезпечення яких їм інакше потрібен був би старший інженер, і роблять це публічно, безкоштовно, через п'ять підтримуваних інтеграцій.
На мій погляд, проєкт надзвичайно ретельний для волонтерського зусилля з доступності, особливо тому, що він перетворює доступність з пізньої турботи QA на багаторазові інструкції для агентів, що працюють під час генерації коду.
Чому це було неминуче
Аргумент, що «файли скілів — це просто README для AI», справедливий, якщо дивитися на якийсь один файл. Він перестає триматися, коли дивишся на те, як OWASP запускає фреймворк безпеки для екосистеми, Vercel постачає офіційну бібліотеку якості, а волонтерський проєкт із доступності виростає у 79 спеціалізованих агентів.
Ось що насправді відбувається: забезпечення якості не зникає, коли ви прибираєте процес. Воно з'являється знову в іншій формі, бо відсутність якості швидко породжує біль, а людина, найближча до цього болю, виправляє його біля джерела.
Традиційна інженерна дисципліна (рев'ю коду, посібники зі стилю, бар'єри QA, архітектурне врядування) існує, щоб ловити те, що окремі розробники пропускають під тиском часу. Вона працює, коли у вас є команда і процес. У vibe-кодерів за задумом часто немає ні того, ні іншого. Тож вони наперед закодували рев'ю в інструкціях агента.
CLAUDE.md — це наперед закодоване рев'ю коду. Awesome Skills — це розподілений посібник зі стилю. AGENTS.md — це стандарт урядування. Слова змінилися. Функція — ні.
Цікаво не те, що обмеження з'явилися знову, — це було неминуче. Цікаво те, що вони з'явилися знову швидше, ніж першого разу, і публічніше, і на рівні якості, який присоромлює деякі інженерні організації зі зрілими процесами.
Спільнота vibe-кодингу не винайшла інженерну дисципліну заново знехотя, під тиском менеджменту. Вона збудувала її, бо вперлася в стіну, а інструменти для її подолання були на відстані одного markdown-файлу.
Часті запитання
Що входить до файлу CLAUDE.md?
Поведінкові обмеження для AI: чого уникати, що пріоритизувати, архітектурні правила, червоні прапорці безпеки та проєктно-специфічні угоди. Орієнтоване на якість використання виходить за межі скорочень робочого процесу: правила на кшталт «ніколи не прибирай обробку помилок, щоб тести пройшли» сусідять із «завжди використовуй TypeScript». Щодо реальних, перевірених прикладів почніть із агрегації спільноти Awesome Skills. agent-skills від Vercel — ще одна сильна довідка.
Що таке AGENTS.md і чим він відрізняється від CLAUDE.md?
AGENTS.md — це універсальний стандарт для проєктно-специфічних вказівок агентам, випущений OpenAI і переданий Agentic AI Foundation при Linux Foundation у грудні 2025 року. CLAUDE.md — це файл проєктних вказівок Claude Code. Вони перетинаються за призначенням, але це не ідентичні формати в кожному інструменті. Практичний висновок: команди дедалі більше можуть написати інструкції для агентів один раз і адаптувати їх між інструментами на кшталт Codex, Cursor, Copilot, Gemini CLI і Claude Code.
Чи безпечно використовувати файли скілів?
Скіли зі спільноти слід прочитати перед імпортом. звіту ToxicSkills від Snyk виявив, що 36% просканованих скілів спільноти мали щонайменше один недолік безпеки, а 13,4% мали недоліки критичного рівня, причому prompt injection був основним механізмом атаки. OWASP Agentic Skills Top 10 — це довідковий фреймворк для розуміння поверхні атаки. Файли скілів з офіційних репозиторіїв чи усталених проєктів з відкритим кодом загалом несуть нижчий ризик ланцюжка постачання, ніж анонімні внески спільноти, але їх усе одно слід переглянути перед імпортом.
Що таке OWASP Agentic Skills Top 10 (AST10)?
Фреймворк безпеки OWASP 2026 року для екосистеми скілів, аналогічний OWASP Web Application Security Top 10, але такий, що спеціально розглядає поверхню атаки, створену файлами інструкцій для AI-агентів. Він охоплює десять найкритичніших ризиків безпеки на платформах, зокрема Claude Code, Cursor/Codex і VS Code. Фреймворк перебуває в активній розробці станом на 2026 рік, а реліз v1.0 заплановано на Q4 2026 року.
Чи потрібні мені файли скілів, якщо я будую особистий проєкт?
Лише якщо ви хочете послідовної поведінки AI. Без обмежень AI-інструменти кодування оптимізують під завершення завдання, а не якість коду, що чудово працює, доки не починає видавати дубльовану логіку, відсутню обробку помилок чи недоступні UI-компоненти. Накладні витрати низькі: один файл на проєкт, що супроводжується в міру того, як ви з'ясовуєте, що AI постійно робить не так. Натхненні Karpathy правила — розумна відправна точка; бібліотеки скілів спільноти дають змогу підтягувати доменно-специфічні правила (безпека, доступність, ідіоми мов) без того, щоб писати їх з нуля.