
Вибір GPU для хмари може здатися складним, коли ви розглядаєте таблиці характеристик, сповнені чисел. Кількість ядер стрибає від 2560 до 21760, але що це означає?
CUDA ядро — це одиниця паралельної обробки всередину GPU NVIDIA, яка виконує тисячі обчислень одночасно, забезпечуючи все від навчання AI до 3D-рендерингу. У цьому посібнику розібрано, як вони працюють, чим відрізняються від ядер типу X86 та Tensor, і які кількості ядер відповідають вашим потребам без переплати.
Що таке ядра CUDA?

CUDA ядра — це окремі одиниці обробки всередину GPU NVIDIA, які виконують інструкції паралельно. Що лежить в основі технології CUDA ядер? Уявіть ці одиниці як малих робітників, які одночасно виконують частини однієї роботи.
NVIDIA представила CUDA (Compute Unified Device Architecture) у 2006 році, щоб використовувати потужність GPU для загальних обчислень поза графікою. офіційна документація CUDA містить детальні технічні деталі. Кожна одиниця виконує базові арифметичні операції з числами з плаваючою крапкою, ідеальні для повторювальних обчислень.
Сучасні GPU NVIDIA містять тисячі цих ядер в одному чипі. Споживчі GPU останнього покоління мають понад 21000 ядер, тоді як GPU центрів обробки даних на базі архітектури Hopper мають до 16896. Ці одиниці працюють разом через Потокові Мультипроцесори (SMs).
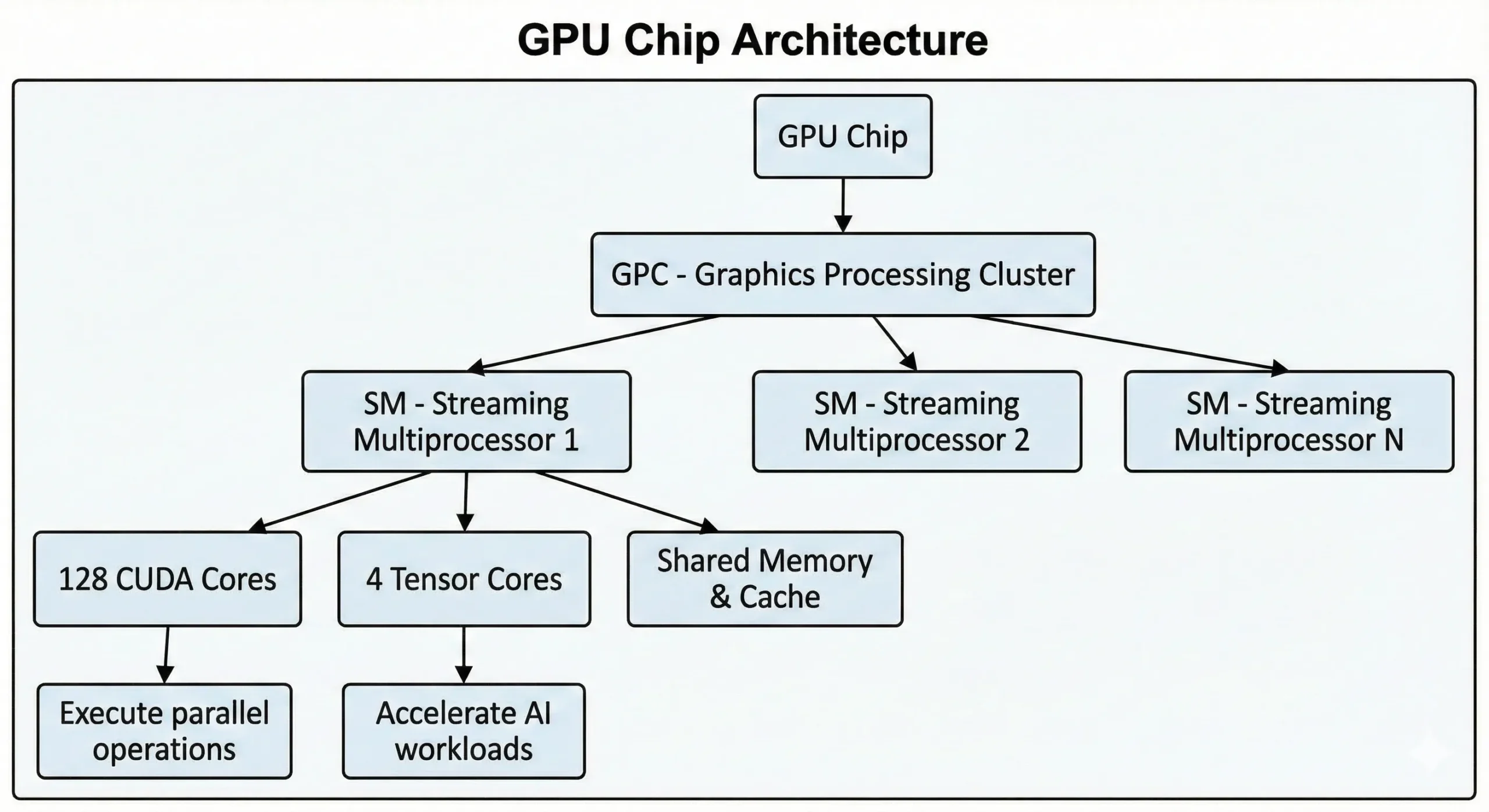
Ці модулі виконують операції SIMT (Single Instruction, Multiple Threads) за допомогою методів паралельних обчислень. Одна інструкція виконується для багатьох точок даних одночасно. При навчанні нейронних мереж або рендерингу 3D-сцен одночасно відбуваються тисячі подібних операцій. Вони розподіляють цю роботу на паралельні потоки, виконуючи її одночасно замість послідовно.
CUDA Cores проти CPU Cores: у чому різниця?

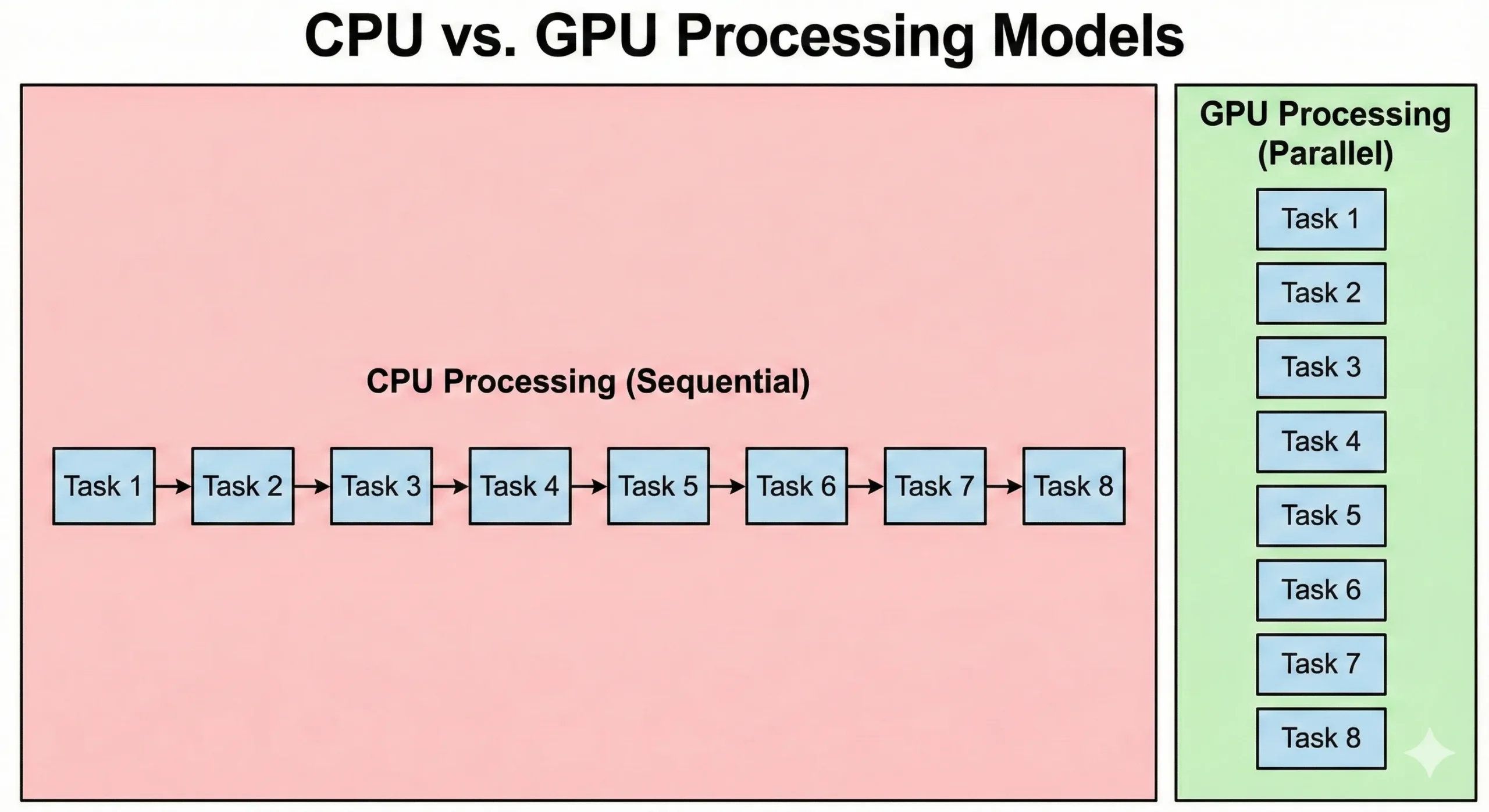
CPU та GPU розв'язують проблеми принципово різними способами. Сучасний серверний CPU може мати 8-128+ ядер, що працюють на високих тактових частотах. Ці процесори досконалі для послідовних операцій, де кожен крок залежить від попереднього результату. Вони ефективно обробляють складну логіку та розгалуження.
GPU використовують протилежний підхід. Вони містять тисячі простіших CUDA cores, що працюють на нижчих тактових частотах. Ці модулі компенсують нижчі швидкості за рахунок паралелізму. Коли 16 000 працюють разом, загальна пропускна спроможність перевищує можливості стандартного CPU.
CPU виконує код операційної системи та складну логіку застосунків. Поки GPU пріоритизують пропускну спроможність, накладні витрати на ініціалізацію задач та синхронізацію призводять до вищої затримки. Паралельна графічна обробка пріоритизує передачу даних. Хоча їм потрібно більше часу на запуск, вони обробляють великі набори даних швидше, ніж CPU.
| Функція | Ядра CPU | CUDA ядра |
| Кількість на чіпі | 4-128+ ядер | 2 560–21 760 ядер |
| Тактова частота | 3,0-5,5 ГГц | 1,4-2,5 ГГц |
| Стиль обробки | Послідовні, складні інструкції | Паралельні, прості інструкції |
| Найкраще для | Операційні системи, однопотокові задачі | Матрична математика, паралельна обробка даних |
| Затримка | Низька (мікросекунди) | Вища (накладні витрати на запуск) |
| Архітектура | Загального призначення | Спеціалізовані на повторюваних розрахунках |
Технології Virtual GPU (vGPU) та Multi-Instance GPU (MIG) керують розподілом ресурсів та планування для розподілу процесорів між кількома користувачами. Таке налаштування дозволяє командам максимізувати утилізацію обладнання через часовий поділ або виділені екземпляри обладнання в залежності від конфігурації.
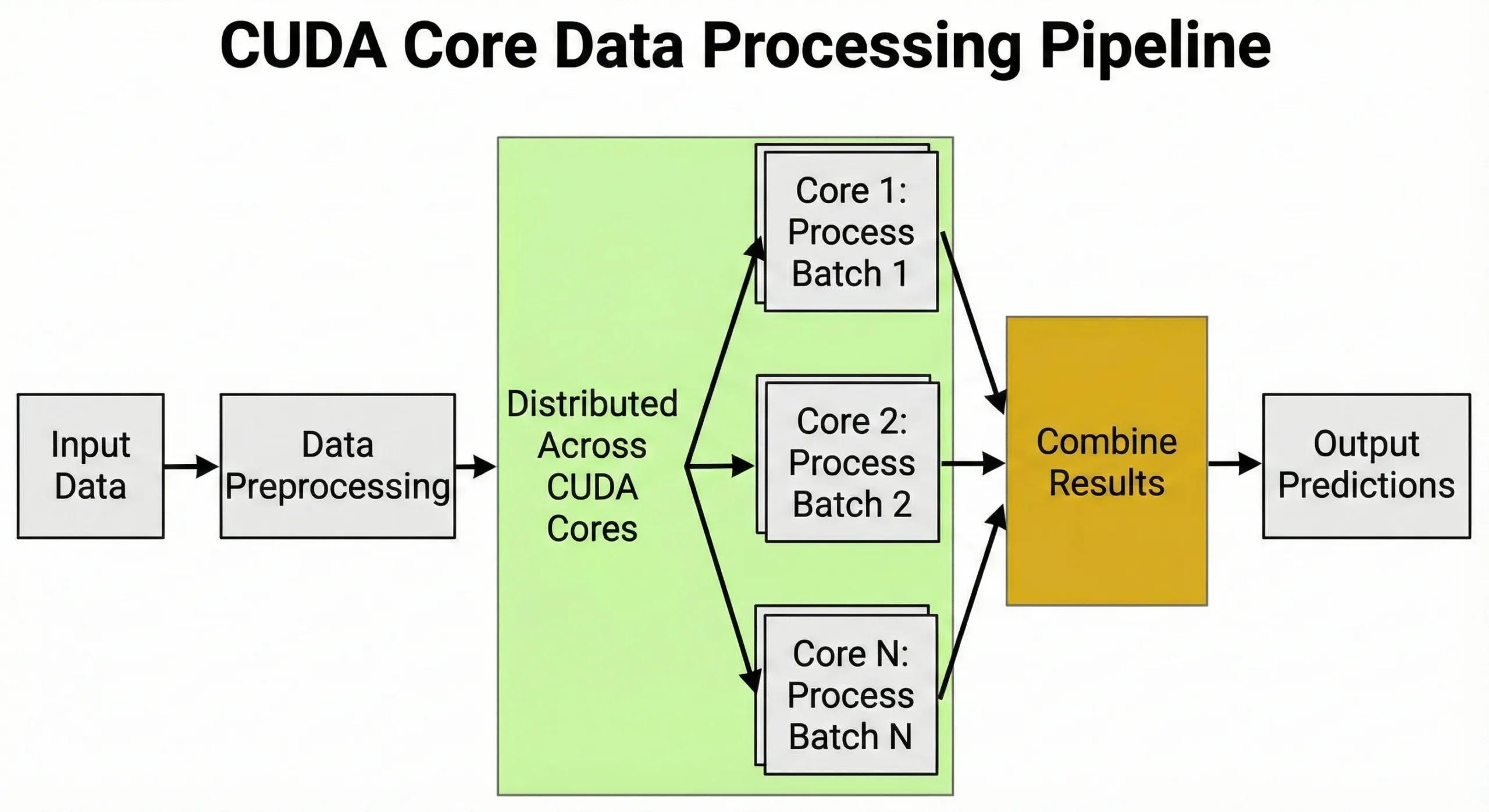
Навчання нейронних мереж передбачає мільярди матричних множень. GPU з 10 000 модулів не просто виконує 10 000 операцій одночасно; замість того він керує тисячами паралельних потоків, згрупованих у «warps» для максимізації пропускної спроможності. Цей масивний паралелізм — ось чому ці модулі критично важливі для розробників AI.
CUDA Cores проти Tensor Cores: розуміння різниці

NVIDIA GPU містять два спеціалізовані типи модулів, які працюють разом: стандартні CUDA cores та Tensor cores. Вони не конкуруючі технології; вони адресують різні частини робочого навантаження.
Стандартні модулі — це універсальні паралельні процесори, що обробляють обчислення FP32 та FP64, цілочислену математику та трансформації координат. Ця базова технологія CUDA формує основу GPU обчислень, запускаючи всі види симуляцій фізики та попередньої обробки даних без спеціалізованого прискорення.
Tensor cores — це спеціалізовані модулі, розроблені виключно для матричного множення та AI задач. Представлені в архітектурі NVIDIA Volta (2017), вони досконалі в обчисленнях з точністю FP16 та TF32. Останнє покоління підтримує FP8 для ще швидшого виведення AI.
| Функція | CUDA ядра | Тензорні ядра |
| Мета | Загальні паралельні обчислення | Матричне множення для AI |
| Точність | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Швидкість для AI | 1x базовий рівень | 2-10x швидше, ніж CUDA cores |
| Сценарії використання | Попередня обробка даних, традиційне машинне навчання | Навчання та інференція глибоких нейронних мереж |
| Наявність | Всі NVIDIA GPUs | RTX 20 серії та новіші, центрові GPUs |
Сучасні GPUs поєднують обидва типи. RTX 5090 має 21,760 стандартних ядер плюс 680 ядер Tensor п'ятого покоління. H100 поєднує 16,896 стандартних ядер з 528 ядрами Tensor четвертого покоління для прискорення глибокого навчання.
Під час навчання нейронних мереж ядра Tensor виконують основну роботу на прямих і зворотних проходах через модель. Стандартні ядра керують завантаженням даних, попередньою обробкою, розрахунками функції втрати та оновленнями оптимізатора. Обидва типи працюють разом, з ядрами Tensor прискорюючи обчислювально складні операції.
Для традиційних алгоритмів машинного навчання, таких як випадкові ліси чи градієнтний бустинг, стандартні ядра керують роботою, оскільки ці алгоритми не використовують паттерни матричного множення, які прискорюють ядра Tensor. Але для моделей трансформерів і згорткових нейронних мереж ядра Tensor забезпечують значне прискорення.
Для чого потрібні ядра CUDA?

Ядра CUDA використовуються для завдань, які потребують великої кількості однакових обчислень, виконаних одночасно. Будь-яка робота, що включає матричні операції або повторювані числові обчислення, отримує переваги від їхної архітектури.
Застосування штучного інтелекту та машинного навчання
Глибоке навчання полягає на матричних множеннях під час навчання та інференції. Під час навчання нейронних мереж кожен прямий прохід потребує мільйонів операцій множення-додавання в матрицях ваг. Зворотне поширення додає мільйони операцій на зворотному проході.
Ядра керують попередньою обробкою даних, перетворенням зображень на тензори, нормалізацією значень і застосуванням трансформацій збільшення. Здатність обробляти тисячі завдань одночасно — саме тому GPUs важливі для ШІ.
Під час навчання вони контролюють розклади швидкості навчання, розрахунки градієнтів та оновлення стану оптимізатора.
Для VPS для операцій інференції ШІ, що запускають рекомендаційні системи або чат-боти, вони обробляють запити одночасно, виконуючи сотні передбачень одночасно. Наш посібник про найкращий GPU для ШІ 2025 охоплює конфігурації, які підходять для різних розмірів моделей.
16,896 ядер H100 разом із ядрами Tensor навчають модель із 7 мільярдами параметрів за тижні замість місяців. Інференція в реальному часі для чат-ботів, що обслуговують тисячі користувачів, потребує подібної потужності для паралельного виконання.
Наукові обчислення та дослідження
Дослідники використовують ці процесори для симуляцій молекулярної динаміки, моделювання клімату та аналізу геномів. Кожне обчислення є незалежним, що робить їх ідеальними для паралельного виконання. Фінансові установи запускають симуляції Монте-Карло з мільйонами сценаріїв одночасно.
3D-рендеринг та відеопродакшн
Трасування променів обчислює відбивання світла у 3D-сценах шляхом трасування незалежних променів через кожен піксель. Хоча спеціалізовані ядра RT керують обходом, стандартні ядра керують вибіркою текстур і освітленням. Цей розподіл визначає швидкість сцен з мільйонами променів.
NVENC обробляє кодування для H.264 та H.265, а найновіші архітектури (Ada Lovelace та Hopper) вводять апаратну підтримку AV1. CUDA допомагає з ефектами, фільтрами, масштабуванням, шумозменшенням, трансформаціями кольору та завдяннями конвеєра. Це дозволяє механізму кодування працювати поряд із паралельними процесорами для швидшої відеопродакшену.
3D-рендеринг у Blender або Maya розподіляє мільярди розрахунків шейдера поверхні между доступними ядрами. Системи частинок мають переваги, оскільки вони моделюють тисячі частинок, що взаємодіють одночасно. Ці можливості є ключовими для високоякісної цифрової творчості.
Як CUDA ядра впливають на продуктивність GPU

Кількість ядер дає загальне уявлення про можливість одночасного виконання, але CUDA ядра потребують розгляду поза цифрами. Тактова частота, пропускна спроможність пам'яті, ефективність архітектури та оптимізація програмного забезпечення грають великі ролі.
GPU з 10 000 ядер, що працює на 2,0 ГГц, дає інші результати, ніж один з 10 000 на 1,5 ГГц. Вища тактова частота означає, що кожне ядро виконує більше обчислень за секунду. Новіші архітектури виконують більше роботи за цикл завдяки кращому плануванню інструкцій.
Перевірте, чи ви тримаєте пристрій задіяним, але пам'ятайте, що nvidia-smi використання — це грубий показник. Він вимірює відсоток часу активності ядра, а не скільки ядер виконують роботу.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderПриклад виведення: 85%, 92% (85% часу активна робота, 92% активність контролера пам'яті)
Якщо ваш GPU показує 60-70% використання, у вас, ймовірно, є вузькі місця в попередніх етапах, такі як завантаження даних CPU або малі розміри пакетів. Однак навіть 100% використання може вводити в оману, якщо ваші ядра обмежені пам'яттю або однопотокові. Щоб отримати справжню картину насичення ядер, використовуйте профайлери, як Nsight Systems, для відстеження метрик SM Efficiency або SM Active.
Пропускна спроможність пам'яті часто стає вузьким місцем, перш ніж вичерпуються можливості обчислень. Якщо ваш GPU обробляє дані швидше, ніж їх поставляє пам'ять, ядра простоюють. Модель H100 SXM5 використовує пропускну спроможність 3,35 ТБ/с щоб живити його 16 896 ядер. Версія PCIe, однак, знижує це до 2 ТБ/с.
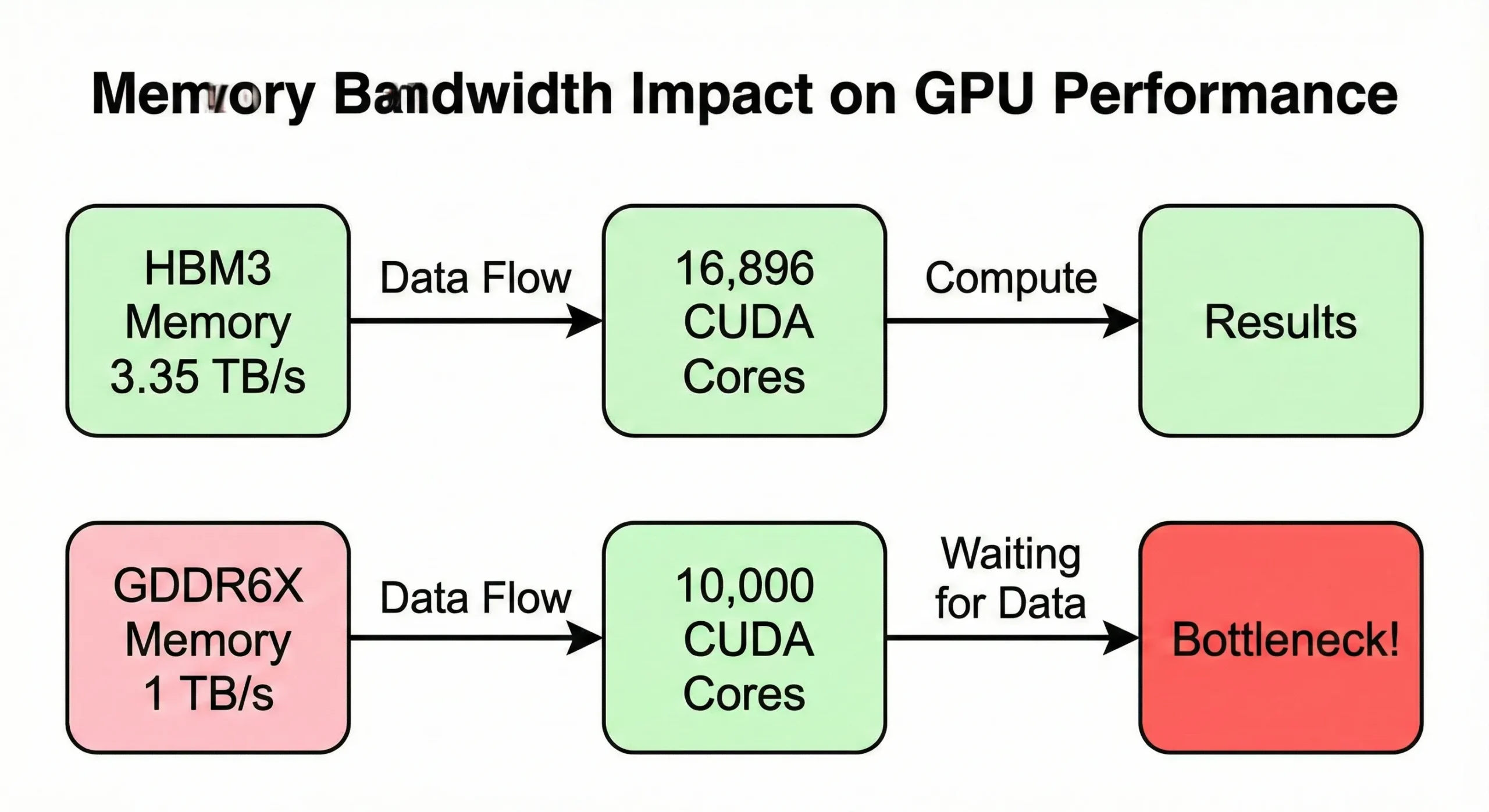
Споживацькі GPU з подібною кількістю ядер, але нижчою пропускною спроможністю (близько 1 ТБ/с), показують зменшену реальну швидкість при операціях, інтенсивних до пам'яті.
Обсяг VRAM визначає розмір ваших завдань. Будь то FP16 ваги для Модель 70B, повне навчання потребує більше пам'яті. Ви повинні врахувати градієнти та стани оптимізатора. Ці стани часто потроюють розмір, якщо ви не використовуєте стратегії розвантаження
A100 80GB спрямований на високопродуктивне висновування та тонке налаштування. Тим часом RTX 4090 24GB, часто цитований для моделей 7B, може дивовижно запускати моделі з параметрами 30B+, якщо ви використовуєте сучасні методи квантування, як INT4. Однак вичерпання VRAM змушує передавання даних CPU-GPU, що знищує пропускну спроможність.
Оптимізація програмного забезпечення визначає, чи ваш код насправді використовує всі ті ядра. Погано написані ядра можуть залучити лише частину доступних ресурсів. Бібліотеки, як cuDNN для глибокого навчання та RAPIDS для науки про дані, глибоко налаштовані для максимізації використання.
Більше CUDA ядер не завжди означає кращу продуктивність

Купівля GPU з найвищою кількістю ядер здається логічною, але ви витрачаєте гроші, якщо ядра випереджають інші компоненти системи або ваше завдання не масштабується з кількістю ядер.
Пропускна спроможність пам'яті створює першу межу. 21 760 ядер RTX 5090 живляються 1 792 ГБ/с пропускної спроможності пам'яті. Старіші GPU з меншою кількістю ядер можуть мати пропорційно вищу пропускну спроможність на одне ядро.
Різниці архітектури мають значення. Новіший GPU з 14 000 ядер на 2,2 ГГц перевершує старіший GPU з 16 000 на 1,8 ГГц завдяки кращим інструкціям за цикл. Ваш код потребує належної паралелізації, щоб ефективно використовувати 20 000 ядер.
Чому CUDA ядра мають значення при виборі GPU VPS

Вибір правильної конфігурації GPU з CUDA ядрами для вашого VPS запобігає витраті грошей на невикористані ресурси або зіткненню з вузькими місцями під час проекту.
H100 з 80GB пам'яті справляється з інференцією для моделей з 70B параметрів, використовуючи 4-бітне квантування. Для повного навчання 80GB часто недостатньо навіть для моделі з 34B, якщо врахувати градієнти та стани оптимізатора. При FP16 навчанні обсяг пам'яті значно зростає, часто потребуючи шардування на кілька GPU.
Інфернційні операції для реал-тайм передбачень потребують менше ядер, але виграють від низької затримки. Розробка й прототипування добре працюють на середньовартісних GPU для тестування алгоритмів та налагодження коду.
RTX 4060 Ti з 4352 ядрами дозволяє тестувати без переплати за надмірну потужність. Як тільки ви перевірите свій підхід, масштабуйте до промислових GPU для повних циклів навчання.
Рендеринг та відеоробота масштабуються з кількістю ядер до певної точки. Renderer Cycles у Blender ефективно використовує всі доступні ресурси. GPU з 8000-10000 ядрами рендерить сцени в 2-3 рази швидше, ніж той, що має 4000.
У Cloudzy ми пропонуємо високопродуктивний GPU VPS хостинг для серйозних завдань. Оберіть RTX 5090 або RTX 4090 для швидкого рендерингу та економічної AI-інференції, або масштабуйте до A100 для великих завдань глибокого навчання. Всі тарифи працюють на 40 Gbps мережі з політикою приватності на першому місці та можливістю оплати криптовалютою, що дає вам чисту потужність без корпоративного навантаження.
Навчання AI-моделей, рендеринг 3D-сцен чи запуск наукових симуляцій — ви обираєте кількість ядер відповідно до своїх потреб.
Бюджет має значення. A100 з 6912 ядрами коштує значно дешевше, ніж H100 з 16896. Для багатьох операцій два A100 дають кращий коефіцієнт ціни до швидкості, ніж один H100. Точка беззбитковості залежить від того, як ваш код масштабується на кілька GPU.
Як обрати правильну кількість CUDA ядер
Узгоджуйте свої потреби з характеристиками реального навантаження, а не гонітеся за максимальними цифрами на ринку.
Почніть з профілювання вашої поточної роботи. Якщо ви навчаєте моделі на локальному обладнанні або хмарних інстансах, перевірте метрики використання GPU. Якщо ваш поточний GPU показує 60-70% використання послідовно, ви не максимізуєте ядра.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Цей простий бенчмарк показує, чи видають ваші GPU ядра очікувану пропускну здатність. Порівняйте результати з опублікованими бенчмарками для вашої моделі GPU.
Оновлення не допоможе. Спочатку потрібно усунути вузькі місця, такі як пам'ять, пропускна здатність або затримки CPU. Далі оцініть вимоги до пам'яті, розрахувавши розмір моделі в байтах плюс пам'ять активацій.
Додайте розмір батча помножений на вихідні дані шару та включіть стани оптимізатора. Цей обсяг має поміститися в VRAM. Як тільки ви знаєте необхідну пам'ять, перевірте, які GPU відповідають цьому порогу.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Врахуйте ваші строки. Якщо вам потрібні результати за години, платіть за більше ядер. Цикли навчання, які можуть тривати дні, добре працюють на менших GPU з пропорційно довшим часом завершення.
Вартість за годину помножена на потрібні години дає загальну вартість, іноді робячи повільніші GPU дешевшими загалом. Тестуйте масштабовану ефективність за допомогою багатьох фреймворків, які пропонують інструменти для бенчмаркування з показами змін пропускної здатності.
Якщо подвоєння ядер дає лише 1.5x прискорення, ці додаткові ядра не вартують своєї вартості. Шукайте оптимальні точки, де коефіцієнт ціни до швидкості піком.
| Тип навантаження | Рекомендовані ядра | Приклади GPU | Примітки |
| Розробка й налагодження моделі | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Швидка ітерація, нижчі витрати |
| Навчання AI з малим масштабом (<7B параметрів) | 6,000-10,000 | RTX 4090, L40S | Підходить для споживачів та малих підприємств |
| Навчання AI з великим масштабом (7B-70B параметрів) | 14,000+ | A100, H100 | Потребує GPU дата-центру |
| Реал-тайм інференція (висока пропускна здатність) | 10,000-16,000 | RTX 5080, L40 | Балансуйте вартість та продуктивність |
| 3D-рендеринг та кодування відео | 8,000-12,000 | RTX 4080, RTX 4090 | Масштабується зі зростанням складності |
| Наукові обчислення та HPC | 10,000+ | A100, H100 | Потребує підтримку FP64 |
Популярні моделі VPS та GPU та їхня кількість CUDA ядер

Різні рівні GPU обслуговують різні групи користувачів. Що таке GPUaaS? Це GPU-як-Сервіс, коли провайдери на кшталт Cloudzy пропонують доступ на вимогу до цих потужних NVIDIA GPU без необхідності купувати та утримувати фізичне обладнання самостійно.
| Модель GPU | CUDA ядра | VRAM | Пропускна здатність пам'яті | Архітектура | Найкраще для |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1 792 ГБ/с | Blackwell | Прапорштокова робоча станція, 8K рендеринг |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 ГБ/с | Ада Лавлейс | Потужний ШІ, 4K рендеринг |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3,350 ГБ/с | Hopper | Масштабне навчання ШІ |
| H100 PCIe | 14,592 | 80GB HBM2e | 2 000 ГБ/с | Hopper | Корпоративний ШІ, економічний дата-центр |
| A100 | 6,912 | 40/80ГБ HBM2e | 1,555–2,039 ГБ/с | Ampere | Середній рівень ШІ, перевірена надійність |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ада Лавлейс | Ігри, ШІ середнього рівня |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ада Лавлейс | Багатофункціональний дата-центр |
Споживацькі карти RTX (4070, 4080, 4090, 5080, 5090) орієнтовані на творців та геймерів, але добре працюють для розробки ШІ. Вони забезпечують сильну однокарткову продуктивність за нижчою ціною, ніж дата-центрові карти.
Провайдери VPS часто мають ці карти в наявності для користувачів, чутливих до вартості. Дата-центрові карти (A100, H100, L40) віддають пріоритет надійності, пам'яті з коректуванням помилок та масштабуванню на кілька карток. Вони розраховані на роботу 24/7 та підтримують передові функції.
Multi-Instance GPU (MIG) дозволяє розділити одну GPU на кілька ізольованих екземплярів. A100 залишається популярною, незважаючи на новіші варіанти, завдяки збалансованим характеристикам.
Баланс між NVIDIA ядрами, пам'яттю та ціною робить її безпечним вибором для більшості промислових операцій ШІ. H100 пропонує в 2,4 рази більше ядер, але коштує значно дорожче.
Висновок
Паралельні процесори роблять можливими сучасні ШІ, рендеринг та наукові обчислення. Розуміння того, як вони працюють та взаємодіють з пам'яттю, частотою та програмним забезпеченням, допомагає вибрати конфігурацію GPU та VPS.
Більше ядер допомагає, коли ваша робота ефективно розпаралелюється, а компоненти на кшталт пропускної здатності пам'яті не створюють вузьких місць. Але сліпий збір максимальної кількості ядер марнує гроші, якщо ваші проблеми розташовані в інших місцях.
Почніть з профілювання ваших реальних операцій, визначення того, де витрачається час, і відповідності характеристик GPU цим вимогам без перевишення непотрібної потужності.
Для більшості робіт з розробки ШІ 6000-10000 ядер — це оптимальне співвідношення між вартістю та можливостями. Промислові операції з навчанням великих моделей або обслуговуванням висока пропускна здатність висновків виграють від GPU з 14000+ ядрами, як H100.
Рендеринг та видеоробота ефективно масштабуються з ядрами до приблизно 16000, після чого пропускна здатність пам'яті стає обмежуючим фактором.


