
Цикл відпрацював чисто сорок разів у тестуванні. На сорок першому запуску в продакшні він викликав той самий SQL-інструмент з тим самим зламаним запитом знову і знову, допоки не витратив весь денний бюджет API - і тільки сповіщення про виставлення рахунку нарешті когось розбудило. Ніхто не написав поганої моделі. Ніхто не змінював промпт. Агент просто так і не вирішив, що закінчив.
Це та сама картина, яку я постійно бачу в командах, що переводять агента з прототипу на цілодобове навантаження. Цикли AI-агентів часто відмовляють у продакшні не тому, що модель раптово погіршилась, а через те, що рівень виконання позбавлений дисципліни завершення, верифікованих контрактів інструментів, обмеженого контексту та стійкого стану. Цикл агента - це стохастична система, що приймає одне послідовне рішення за іншим. Без кількох конкретних захисних механізмів рідкісна відмова перетворюється на гарантовану, якщо запускати цикл достатньо довго. Керовані платформи агентів (Vertex AI Agent Builder, Bedrock Agents, Azure AI Foundry) вбудовують частину цих захисних механізмів; цей посібник - для тих, хто обрав самостійне розгортання і контролює цикл власноруч.
Ставки досить реальні: Gartner прогнозує, що понад 40% проектів з агентним AI буде скасовано до кінця 2027 року, посилаючись на зростаючі витрати і нечітку цінність. Далі розглянуто шість конкретних способів, якими цикли ламаються в продакшні, механізм кожного з них і шаблон обв'язки, що виправляє проблему, з деталями для LangGraph та n8n, а також те, що потрібно для реального цілодобового запуску.
Коротко
- Нескінченні цикли: Агент так і не вирішує, що закінчив. Поєднайте жорсткий ліміт кроків (LangGraph's
recursion_limit, типово 25) з виявленням відсутності прогресу, яке зупиняє повторні виклики одного й того самого інструменту з тими самими аргументами. - Переповнення контексту: Цикл заповнює власне вікно контексту накопиченою історією, поки виклики не почнуть обрізатися або падати. Підсумовуйте історію через фіксовані інтервали, щоб робочий контекст залишався обмеженим.
- Тихі збої інструментів: Інструмент повертає порожній рядок, модель читає це як коректну операцію без дій, і агент "успішно" нічого не робить. Перевіряйте кожен результат інструменту до того, як модель його побачить.
- Деградація логіки: Якість погіршується зі зростанням контексту, навіть нижче жорсткого ліміту. Стискайте контекст посередині циклу, але захищайте закріплені інструкції безпеки при цьому.
- Втрата стану при перезапуску: Збій означає початок з нуля. Зберігайте контрольні точки в Postgres (LangGraph
PostgresSaver), а не в SQLite, для продакшну. - Шторми повторних запитів: Десять агентів, кожен з яких робить десять повторних спроб, відправляють сто запитів до недоступного сервісу. Додайте експоненційне відкладення з джиттером і глобальний автоматичний вимикач.
Що цей посібник не охоплює
Це посібник з обв'язки, зосереджений на інженерному рівні навколо циклу, а не на моделі всередині нього. Кілька суміжних тем залишені поза межами навмисно:
- Збої координації між агентами (застарілі зчитування, осиротілий стан між агентами): окрема проблема, що заслуговує власного опису.
- Безпека агентів (ін'єкція промпту, отруєння інструментів): окрема категорія відмов зі своєю власною моделлю загроз.
- Вибір моделі та дообучання. Цей посібник передбачає, що ви вже обрали модель і налагоджуєте систему навколо неї.
- Керовані сервіси агентів, згадані вище; шаблони тут призначені для шляху самостійного розгортання.
Нескінченні цикли: коли агент так і не вирішує, що закінчив

Агент циклиться нескінченно, коли в нього немає ні жорсткого ліміту кроків, ні способу виявити, що він перестав просуватись. Виправлення складається з двох частин: жорсткий ліміт як страховий бар'єр витрат і виявлення відсутності прогресу, яке хешує кожен виклик інструменту з аргументами та завершує роботу, коли бачить повторення. У LangGraph цей ліміт - recursion_limit, типово 25 кроків; перевищте його - і граф підніме виняток. GraphRecursionError.
LangGraph's docs описують цей ліміт як досягнення "максимальної кількості кроків до настання умови зупинки", і ось де є пастка: recursion_limit - це не захист від циклів. Це страховий бар'єр, який спрацьовує після після того, як цикл вже витратив двадцять п'ять кроків і відповідний бюджет API. Власна вивчена логіка завершення агента повинна зупинити його набагато раніше, і ця логіка може відмовити незалежно. Один задокументований випадок у LangGraph показує агента text-to-SQL, що циклився до досягнення ліміту recursion_limit, попри чіткі умови зупинки в промпті. Він продовжував викликати той самий інструмент запитів з тим самим SQL, що не виконувався, а задача була закрита як "not planned". Я розцінюю це як чіткий сигнал: не вважайте ліміт умовою зупинки. Це ваш ремінь безпеки, а не гальма.
Підняти ліміт просто: передайте його через конфіг під час виклику графа:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)Те, що насправді зупиняє застряглий цикл, - це виявлення прогресу. Механізм простий: хешуйте ім'я інструменту плюс його аргументи на кожному кроці, зберігайте коротке вікно останніх хешів і зупиняйтесь, коли бачите повторення.
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)Це ловить агента, який технічно "працює" (викликає інструменти, генерує токени), але циклиться на тій самій дії, що не вдається. Названий режим відмови тут відповідає тому, що таксономія MAST (IBM Research та UC Berkeley) називає Невідомість про умови завершення (FM-1.5), один із режимів відмов, які їхній аналіз пов'язує з повним провалом завдання.
Ліміт кроків зупиняє неконтрольовані витрати. Виявлення відсутності прогресу зупиняє цикл, який технічно "просувається", але повторює себе. Продакшн потребує обох.
Переповнення вікна контексту: коли цикл забиває власний контекст сміттям
Тривалий цикл накопичує всі виходи інструментів, всі проміжні думки і всі повідомлення, що він виробив, а потім запихає все це назад у вікно контексту на кожному ході. Зрештою вікно заповнюється, і виклики або тихо обрізаються, або падають зовсім. Виправлення - це підсумування контексту через фіксовані інтервали: кожні N кроків стискайте накопичену історію у поточне резюме, щоб робочий контекст залишався обмеженим.
Уявіть дослідницького агента, що працює вже годину. До кроку 60 він несе повний текст кожної сторінки, яку отримав, кожного результату пошуку, кожного сліду логіки. Жодна з цих необроблених даних не допомагає йому на кроці 61, але всі вони враховуються у вікні, і модель витрачає бюджет уваги на токени, які їй більше не потрібні. Коли вікно заповнюється, провайдер обрізає з одного кінця, і агент тихо втрачає інструкцію, з якої починав.
Поріг спрацювання - це параметр налаштування, і для нього є зручна точка відліку. Опис реальної продакшн-системи від Mem0 зазначає, що компресор агента Hermes "за замовчуванням спрацьовує при 50% вікна контексту моделі", з додатковою страховою сіткою на 85% для сесій, що роздуваються між ходами. П'ятдесят відсотків - розумна відправна точка: стискайте достатньо рано, щоб один великий вихід інструменту не міг перевищити ліміт до наступного запланованого стиснення.
Примітка: Overflow і деградація міркувань — це різні проблеми, і наступний розділ присвячений другій із них. Overflow — це жорстке обмеження: у вас закінчуються tokens. Деградація є поступовою: модель працює дедалі гірше. до досягнення стіни. Потрібно обробляти обидві, і наведений поріг захищає від жорсткої стіни.
Обмежений контекст - відповідальність обв'язки, а не функція моделі. Підсумовуйте за інтервалом до того, як вікно змусить до тихого обрізання.
Тихі збої викликів інструментів: коли агент "успішно" нічого не робить
Виклик інструменту повертає порожній рядок або м'яке повідомлення "результатів не знайдено", модель інтерпретує це як коректний результат, і агент продовжує роботу, ніби крок спрацював, видаючи успіх, хоча нічого не зробив. Виправлення - шлюз валідації на кожному поверненні інструменту: перевіряйте вихід за схемою або базовою логікою до того, як модель його побачить, і замість порожнього успіху видавайте реальну помилку, з якою цикл повинен впоратись.
Це підступно, бо нічого не падає. Розробник, що описував тихі режими відмов у продакшн-агентах , висловився прямо: моделі інтерпретують загальні порожні рядки як коректні операції без дій і продовжують виконання, не усвідомлюючи відмови. Запит до бази даних, що повернув нуль рядків через розрив з'єднання, виглядає для моделі ідентично запиту, що законно нічого не знайшов. Тому агент звітує "відповідних записів не знайдено" і рухається далі, а ви дізнаєтесь через тиждень, що третина його запусків була тихо зламана.
Шлюз валідації розташований між інструментом і моделлю:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the modelСправа не в конкретних перевірках; ваші залежатимуть від того, що кожен інструмент законно повертає. Суть у тому, що неперевірене значення, що повертається, - це рішення, яке ви передали стохастичній моделі, а типова поведінка моделі - продовжувати роботу.
Неперевірене повернення інструменту - це тихий збій, що чекає свого часу. Перевіряйте вихід, не довіряйте виклику.
Деградація логіки на довгих контекстах: коли агент погіршується з часом
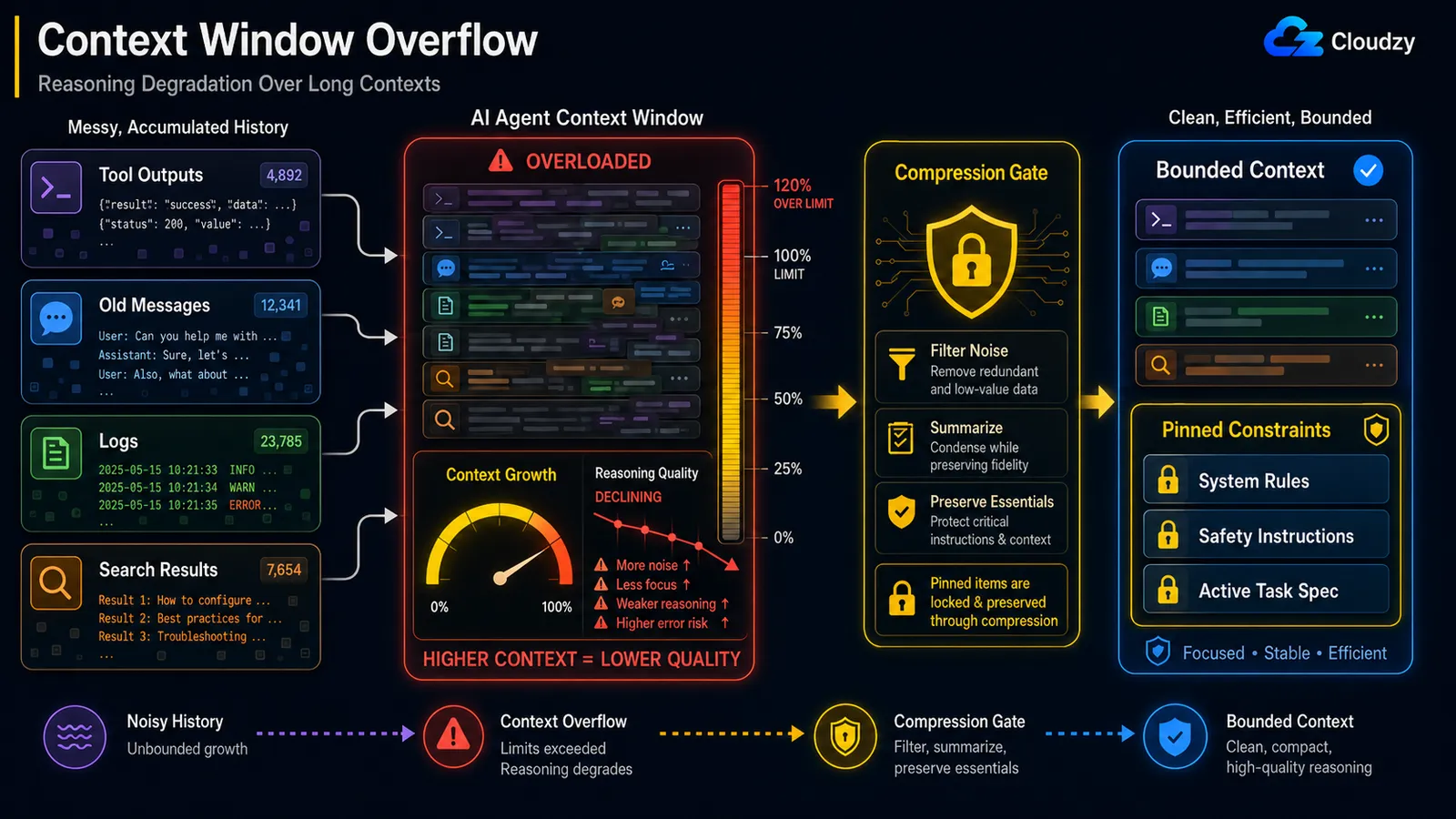
Навіть якщо ви залишаєтесь в межах жорсткого ліміту контексту, якість логіки погіршується зі зростанням контексту. Це ефект «загублено посередині»: модель надійно звертає увагу на початок і кінець довгого контексту, але втрачає середину. Виправлення - стиснення посередині циклу із збереженням закріплених обмежень: стискайте шум, захищайте несучі інструкції.
Механізм має назву. Інженерний блог Anthropic посилається на нього як на «деградацію контексту»: : "зі збільшенням кількості токенів у вікні контексту здатність моделі точно відтворювати інформацію з цього контексту знижується." Оскільки "кожен токен звертає увагу на кожен інший токен," ви отримуєте n² попарних зв'язків для n токенів, і увага моделі розтягується тонше з кожним кроком.
Цей уточнювальний момент, захищати несучі інструкції, - це вся суть гри, і є задокументований інцидент, який показує чому. В одному задокументованому випадку, агент OpenClaw масово видалив вхідні повідомлення користувача під час стиснення контексту, бо інструкція безпеки, яку йому дали ("не вживай дій, поки я не скажу"), була вилучена з активного контексту під час стиснення історії. Обмеження, яке мало залишитись останнім, було сприйняте як звичайна історія і підсумоване геть.
Тому наївне "підсумовувати все старше N ходів" небезпечне. Стиснення повинне знати, що воно ніколи не може відкинути:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intactЦе відрізняється від проблеми переповнення з попереднього розділу. Переповнення - це вичерпання місця; деградація - це погіршення роботи моделі, поки місце ще є. Ви можете знаходитись на 60% вашого вікна і вже мати погану логіку.
Примітка: Стиснення, що відкидає обмеження безпеки, - це клас помилок гірший, ніж стиснення, що втрачає застарілий результат пошуку. Позначайте обмеження, специфікацію завдання і будь-які інструкції «не роби X» як закріплені, і повністю виключайте їх із підсумовувача.
Стиснення, що відкидає інструкцію безпеки, гірше за відсутність стиснення. Захищайте закріплені обмеження при стисненні.
Втрата стану при перезапуску: коли збій означає початок з нуля
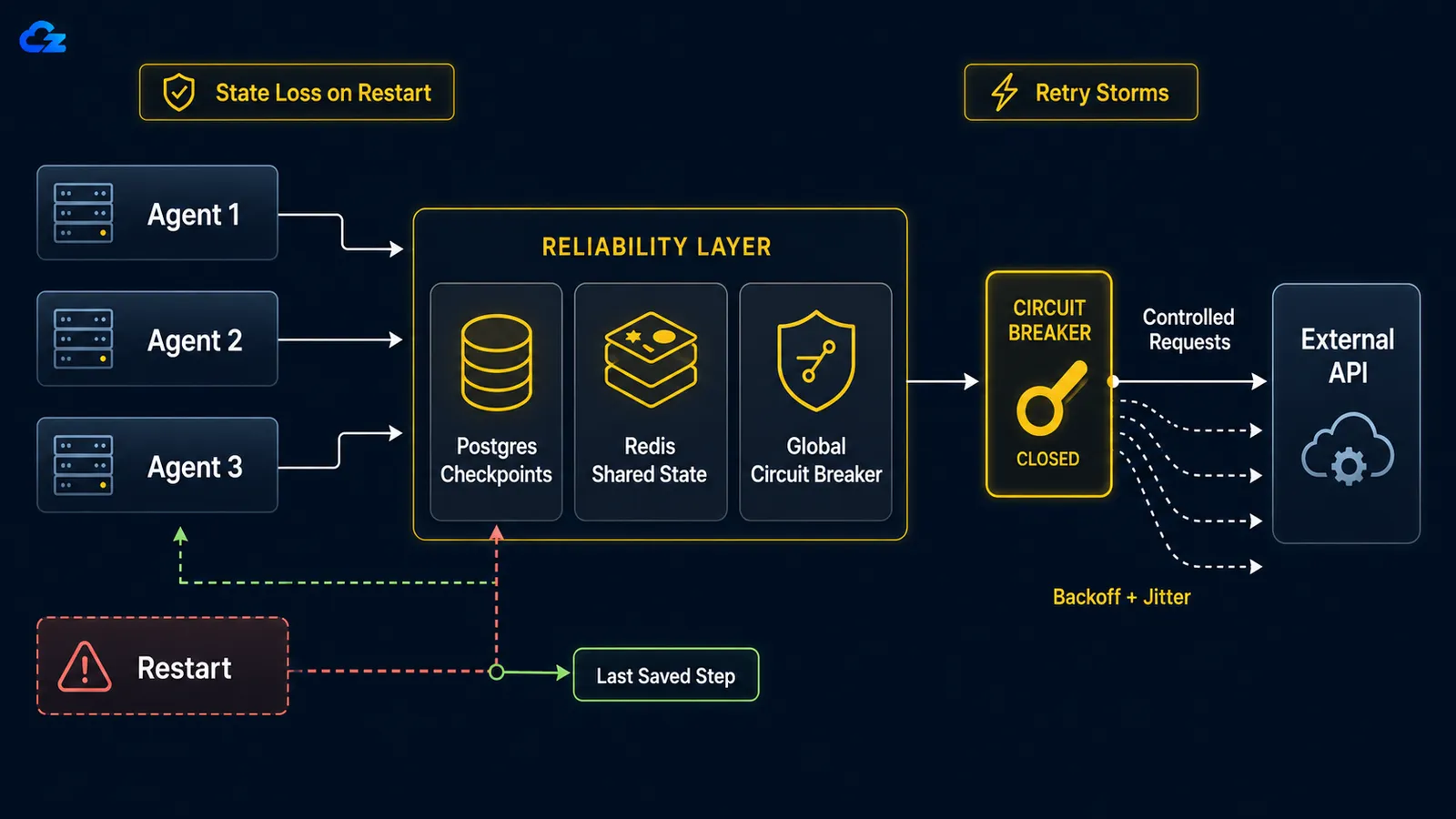
Коли тривалий агент падає - через перезавантаження, OOM kill або обрив з'єднання - за замовчуванням немає відновлення з контрольної точки. Цикл починається з нуля: повторює вже виконану роботу і, що гірше, може повторно виконати вже здійснені дії - наприклад, надіслати той самий електронний лист двічі або повторно запустити платний виклик API. Виправлення - збереження контрольних точок: записуйте стан циклу після кожного кроку, щоб перезапуск відновлював роботу з місця зупинки, а не з нуля.
У LangGraph вибір бекенду для контрольних точок - це вибір між розробкою і продакшном. Документація LangGraph щодо збереження стану описує SqliteSaver як «ідеальне для експериментів і локальних робочих процесів» та PostgresSaver як «ідеальне для використання в продакшні», і саме останнє є тим, на чому працює LangSmith. Обидва навмисно паралельні у коді, що робить контраст легко помітним:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaverДві деталі, що кусають людей. По-перше, пакети контрольних точок встановлюються окремо від ядра LangGraph (langgraph-checkpoint-sqlite та langgraph-checkpoint-postgres є їхніми власними залежностями), тому свіжа машина не матиме Postgres saver, поки ви не додасте його. По-друге, кожній операції з контрольними точками потрібен thread_id у конфігурації. Цей ID прив'язує конкретний запуск до його збереженого стану, і перезапуск без правильного thread_id не відновить нічого.
Порада: Пакети контрольних точок LangGraph встановлюються окремо.
langgraph-checkpoint-postgresне підтягується базовим пакетомlanggraph, тому зафіксуйте його у вашому продакшн-файлі залежностей, перш ніж дізнатись про це під час інциденту.
У n8n є таке ж розділення між розробкою і продакшном, просто під іншими назвами. Його вбудована опція пам'яті також називається Simple Memory (або Buffer Window Memory), а продакшн-шлях - це вузол Postgres Chat Memory для стану, що має пережити перезапуск. Вбудована пам'ять зберігає розмову в процесі, що виконується - це нормально для тестування і ризиковано для цілодобового навантаження. Практики, що запускають агенти n8n у живому середовищі, повідомляють, що їм доводилось мігрувати до сховища на базі Postgres після того, як оперативна пам'ять зростала до тих пір, поки не укладала разом із собою весь інстанс. Якщо ви на n8n і вашому агенту потрібно щось пам'ятати після перезапуску - підключайте Postgres Chat Memory з самого початку.
Контрольні точки SQLite - це зручність для розробки. Виживання після перезапуску в продакшні означає Postgres (LangGraph) або сховище на базі Postgres (n8n).
Шторми повторних запитів: коли ваші власні агенти влаштовують DDoS мертвому сервісу
Коли нижчестоящий сервіс падає, наївні повторні спроби на рівні кожного виконання перетворюють ваш парк агентів на самозавдану відмову в обслуговуванні. Виправлення має дві складові: експоненційне відкладення з джиттером для кожного агента, щоб розподілити повторні спроби у часі, і глобальний автоматичний вимикач, що спрацьовує після досягнення спільного порогу відмов і зупиняє весь стад від атаки на сервіс, що явно недоступний.
Математика невблаганна. Як зазначає стаття про патерни повторних спроб , при десяти паралельних агентах, кожен з яких робить десять повторних спроб, ви відправляєте сто запитів до сервісу, що вже лежить на підлозі, бо відкладення кожного агента відбувається на рівні виконання, а не глобально. Відкладення на рівні одного агента само по собі не вирішує проблему. Десять агентів, що відступають ввічливо, все одно відступають синхронно, якщо всі почали одночасно, - тому вони повторюють спроби синхронізованими хвилями. Джиттер розриває синхронізацію, рандомізуючи час очікування кожного агента; автоматичний вимикач розриває стад, розділяючи один стан відмови між ними всіма.
Половина з відкладенням - вирішена проблема в Python; бібліотека tenacity обробляє експоненційне відкладення з джиттером чисто:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)Автоматичний вимикач - це та половина, яка повинна бути глобальною: спільною для всіх агентів, а не перестворюваною при кожному виконанні. Коли відмови перевищують поріг, вимикач відкривається, кожен агент швидко провалюється замість виклику, а після охолодження пропускає один пробний запит, щоб перевірити, чи сервіс повернувся. Вимикач, що живе всередині власного процесу кожного агента, нічого не захищає, бо нічого не ділиться; мертвий сервіс все одно отримує всі сто запитів.
Відкладення на рівні виконання все одно дозволяє десяти агентам атакувати мертвий сервіс синхронно. Автоматичний вимикач повинен бути глобальним, щоб зупинити стад.
Шість режимів відмов з одного погляду
До частини про інфраструктуру - ось весь каталог в одному місці: відмова, механізм, що її спричиняє, виправлення в обв'язці і де знаходиться відповідний параметр у кожному фреймворку.
| Режим відмови | Механізм | Виправлення в обв'язці | Параметр фреймворку |
|---|---|---|---|
| Нескінченний цикл | Немає ліміту кроків або перевірки прогресу | Жорсткий ліміт + виявлення відсутності прогресу | LangGraph recursion_limit (25) / n8n Max Iterations |
| Переповнення контексту | Історія зростає до заповнення вікна | Підсумування через інтервал | На рівні застосунку (стискати при ~50% вікна) |
| Тихий збій інструменту | Порожні/м'які повернення читаються як коректні операції без дій | Шлюз валідації на кожному результаті інструменту | Обгортка інструменту на рівні застосунку |
| Деградація логіки | Увага спадає зі зростанням контексту («деградація контексту») | Стиснення посередині циклу із захистом закріплених обмежень | На рівні застосунку, з урахуванням обмежень |
| Втрата стану при перезапуску | Немає контрольної точки; цикл починається з нуля | Постійне збереження контрольних точок | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| Шторм повторних запитів | Повторні спроби на рівні виконання каскадують на мертвому сервісі | Відкладення + джиттер + глобальний автоматичний вимикач | tenacity + спільний стан вимикача |
Примітка для читачів на CrewAI, AutoGen, Dify або власноруч написаному циклі Python: параметри фреймворку змінюються, але шість патернів - ні. Дедуплікація, інтервальне підсумування, валідація схеми, стиснення з урахуванням обмежень, збереження контрольних точок і глобальний автоматичний вимикач - це фреймворк-агностичні концепції. Деталі LangGraph і n8n тут - це конкретні точки опори, а не межі застосування патернів.
Розмір продакшн-розгортання агентів
Кожен патерн вище передбачає, що ви контролюєте менеджер процесів, базу даних і поведінку при перезапуску. Контрольні точки нічого не дадуть, якщо впавший цикл ніколи не піднімається, а глобальному автоматичному вимикачу потрібне місце для зберігання спільного стану. Саме цей контроль дає вам самостійне розгортання, і чого позбавлена керована чорна скринька - тому останнє рішення - це розмір машини, що запускає все це цілодобово.
Для більшості розгортань з одним агентом (один агент, виклики LLM до зовнішнього API, базове збереження контрольних точок у Postgres) достатньо невеликого інстансу: приблизно 2 GB RAM, 1 vCPU, and 60 GB of NVMe storage. Важкі обчислення знаходяться на стороні провайдера моделі; ваша машина оркеструє, зберігає контрольні точки і утримує стан, а не виконує інференс. Переходьте приблизно до 4 GB RAM, 2 vCPU, and 120 GB NVMe коли агент має стан і виконує кілька кроків із контрольними точками Postgres плюс Redis для гідратації сесій, або коли ви запускаєте паралельні робочі процеси, що ділять хост.
Причина, через яку тут потрібен VPS під власним управлінням, а не обмежена платформа, та сама, що й причина, через яку виправлення взагалі працюють: їм потрібен root. Власний Postgres для контрольних точок, власний Redis для стану сесій і реальний менеджер процесів, наприклад, systemd or pm2, щоб коли цикл падає, супервайзер перезапускав його і він відновлював роботу з останньої контрольної точки замість перезапуску завдання з початку. Вся ця история з відновленням залежить від того, що ви контролюєте lifecycle процесів.
Оскільки ми запускаємо n8n як додаток в один клік у нашому власному маркетплейсі, ця частина налаштування у нас найкоротша: ви можете розгорнути n8n на Cloudzy VPS з конфігурацією на базі Postgres, яка потрібна продакшн-шляху, на інстансі з root-доступом для додавання власних Redis і процесного нагляду. Це та сама самостійна інфраструктура, описана вище, де ви контролюєте базу даних і поведінку при перезапуску, що і робить контрольні точки та автовідновлення справді робочими.
Патерни обв'язки надійні рівно настільки, наскільки надійна машина, на якій вони запущені. Контрольні точки нічого не дадуть, якщо процес ніколи не перезапускається.
Часті запитання
Як зупинити нескінченний цикл агента LangGraph?
Використовуйте два механізми разом. Встановіть recursion_limit як жорсткий ліміт кроків (типово 25), щоб цикл, що вийшов з-під контролю, не міг витратити необмежений бюджет, і додайте виявлення відсутності прогресу, яке хешує кожен виклик інструменту з аргументами та зупиняється, коли той самий виклик повторюється у нещодавньому вікні. Ліміт сам по собі - це страховий бар'єр, що спрацьовує після того, як витрати вже відбулись, а не реальний захист від циклів. Виявлення прогресу - ось що насправді зупиняє застряглий цикл.
Яке правильне значення recursion_limit для LangGraph у продакшні?
Немає універсального числа. Встановлюйте його рівним максимальній кількості законних кроків, що ваш агент коли-небудь може потребувати, плюс запас, і ставтесь до нього суворо як до страхового бар'єру. Підняття ліміту не змушує агент, що циклиться, зійтися. Якщо ваш агент досягає високого ліміту, виправлення - виявлення прогресу, а не вищий ліміт.
Чому мій AI-агент n8n продовжує досягати Max Iterations?
Досягнення ліміту Max Iterations означає, що агент не сходиться: він виконує більше кроків, ніж дозволяє ліміт, не досягаючи зупинки. Підвищуйте ліміт тільки якщо завдання законно потребує більше кроків; інакше сприймайте це як сигнал, що агент застряг. Зверніть увагу на одну конкретну пастку: GitHub issue #22771 повідомляє, що коли ліміт ітерацій досягнуто при встановленому «On Error: Continue», виконання може направитись до виходу Success замість Error, тому обмежений, невдалий запуск може виглядати успішним у вашому робочому процесі.
Як зберегти стан агента між перезапусками?
У LangGraph використовуйте збереження контрольних точок з PostgresSaver замість SqliteSaver, що призначений для локальної розробки. У n8n використовуйте вузол Postgres Chat Memory замість вбудованої оперативної пам'яті. Обидва потребують постійної бази даних, і в LangGraph кожна операція з контрольними точками потребує thread_id , що прив'язує конкретний запуск до його збереженого стану.
Що спричиняє деградацію логіки при тривалих запусках агентів?
Якість логіки падає зі зростанням контексту, навіть до досягнення жорсткого ліміту токенів. Це ефект «загублено посередині»: модель звертає увагу на початок і кінець довгого контексту, але втрачає середину. Інженерний блог Anthropic посилається на базовий механізм як на «деградацію контексту»: оскільки кожен токен звертає увагу на кожен інший токен, ви отримуєте n² попарних зв'язків, і увага моделі розтягується тонше зі зростанням контексту. Виправлення - стиснення посередині циклу, що підсумовує застарілу історію, зберігаючи при цьому закріплені обмеження та інструкції безпеки незайманими.


