
Einer der wichtigsten, wenn nicht sogar der wichtigste Aspekt des maschinellen Lernens ist das Erzielen genauer und zuverlässiger Vorhersagen. Ein innovativer Ansatz, der dabei zunehmend an Bedeutung gewonnen hat, ist das Bootstrap Aggregating, besser bekannt als Bagging im maschinellen Lernen. Dieser Artikel erklärt Bagging im maschinellen Lernen, vergleicht Bagging und Boosting, zeigt ein Beispiel eines Bagging-Klassifikators, erläutert die Funktionsweise von Bagging und beleuchtet die Vor- und Nachteile von Bagging im maschinellen Lernen.
Was ist Bagging im maschinellen Lernen?
Dies sind die einzigen relevanten Bilder aus populären Artikeln. Eines oder beide können verwendet werden (eines hier, das andere an anderer Stelle), sofern das Design-Team Cloudzy-Versionen davon erstellt.
Was ist Bagging?
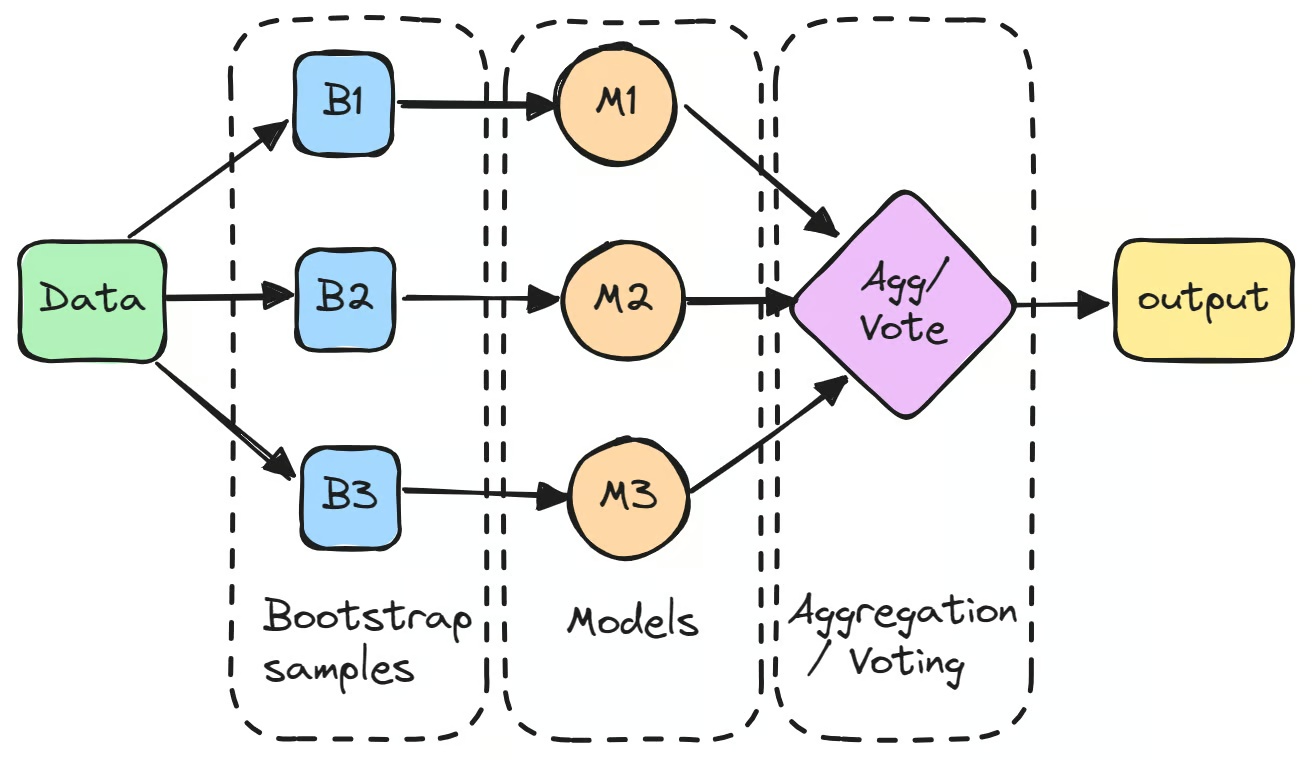
Stell dir vor, du möchtest das Gewicht eines Gegenstands schätzen und fragst dafür mehrere Personen. Jede Schätzung für sich kann stark abweichen – doch wenn du alle Werte mittelst, kommst du zu einem verlässlicheren Ergebnis. Genau das ist das Prinzip des Bagging: Mehrere Modelle liefern ihre Vorhersagen, und ihre kombinierten Ausgaben ergeben eine genauere, stabilere Prognose.
Der Prozess beginnt damit, durch Bootstrapping – also zufälliges Sampling mit Zurücklegen – mehrere Teilmengen des ursprünglichen Datensatzes zu erstellen. Jede Teilmenge wird verwendet, um ein separates Modell unabhängig zu trainieren.
Diese einzelnen Modelle, oft "schwache Lerner" genannt, performen einzeln möglicherweise nicht besonders gut aufgrund hoher Varianz. Aber wenn ihre Vorhersagen aggregiert werden, üblicherweise durch Durchschnittsbildung bei Regressionsaufgaben oder Mehrheitsabstimmung bei Klassifikationsaufgaben, übersteigt das kombinierte Ergebnis oft die Performance eines einzelnen Modells.
Ein bekanntes Beispiel für einen Bagging-Klassifikator ist der Random-Forest-Algorithmus, der ein Ensemble aus Entscheidungsbäumen aufbaut, um die Vorhersagegenauigkeit zu verbessern. Dabei sollte Bagging nicht mit Boosting im Machine Learning verwechselt werden: Während Boosting Modelle sequenziell trainiert, um den Bias zu reduzieren, trainiert Bagging Modelle parallel, um die Varianz zu verringern.
Bagging und Boosting verfolgen im Machine Learning dasselbe Ziel – bessere Modelle –, gehen dabei aber unterschiedliche Wege.
Warum ist Bagging nützlich?
Einer der größten Vorteile von Bagging im Machine Learning ist die Fähigkeit, die Varianz zu reduzieren – wodurch Modelle besser auf unbekannte Daten generalisieren. Bagging ist besonders nützlich bei Algorithmen, die empfindlich auf Schwankungen in den Trainingsdaten reagieren, wie etwa Entscheidungsbäume.
Durch die Verhinderung von Overfitting sorgt es für ein stabileres und zuverlässigeres Modell. Beim Vergleich von Bagging und Boosting im Machine Learning konzentriert sich Bagging darauf, die Varianz zu reduzieren, indem mehrere Modelle parallel trainiert werden, während Boosting darauf abzielt, den Bias zu verringern, indem Modelle sequenziell trainiert werden.
Ein praktisches Beispiel für Bagging im Machine Learning findet sich in der Finanzrisikovorhersage: Mehrere Entscheidungsbäume werden auf unterschiedlichen Teilmengen historischer Marktdaten trainiert. Durch die Aggregation ihrer Vorhersagen entsteht ein zuverlässigeres Prognosemodell, das die Auswirkungen einzelner Modellfehler reduziert.
Im Kern nutzt Bagging im maschinellen Lernen die kombinierte Stärke mehrerer Modelle, um Vorhersagen zu liefern, die genauer und zuverlässiger sind als die einzelner Modelle allein.
Wie Bagging im Machine Learning funktioniert: Schritt für Schritt
Um zu verstehen, wie Bagging die Modellleistung verbessert, schauen wir uns den Prozess Schritt für Schritt an.
Mehrere Bootstrap-Stichproben aus dem Datensatz ziehen
Der erste Schritt beim Bagging im maschinellen Lernen besteht darin, mehrere neue Teilmengen des ursprünglichen Datensatzes durch Bootstrapping zu erstellen. Bei dieser Technik werden die Daten zufällig mit Zurücklegen gesampelt, sodass einige Datenpunkte in derselben Teilmenge mehrfach vorkommen können, während andere möglicherweise gar nicht erscheinen. Dieser Prozess stellt sicher, dass jedes Modell mit einer leicht abweichenden Version der Daten trainiert wird.
Für jede Stichprobe ein eigenes Modell trainieren
Jedes Bootstrap-Sample wird verwendet, um ein separates Modell zu trainieren, in der Regel vom gleichen Typ, etwa Entscheidungsbäume. Diese Modelle, häufig als "Basislerner" oder "schwache Lerner" bezeichnet, werden unabhängig voneinander auf ihren jeweiligen Teilmengen trainiert. Ein klassisches Beispiel für einen Bagging-Klassifikator ist der Entscheidungsbaum im Random-Forest-Algorithmus, der die Grundlage vieler Bagging-Modelle bildet. Auch wenn jedes einzelne Modell für sich genommen keine hohe Genauigkeit erreicht, liefert jedes auf Basis seiner Trainingsdaten eigene, spezifische Erkenntnisse.
Vorhersagen zusammenführen
Nach dem Training der Modelle werden ihre Vorhersagen zusammengeführt, um das finale Ergebnis zu bilden.
- Bei Regressionsaufgaben werden die Vorhersagen gemittelt, wodurch die Varianz des Modells reduziert wird.
- Bei Klassifikationsaufgaben wird die endgültige Vorhersage per Mehrheitsentscheid getroffen: Die Klasse, die von den meisten Modellen vorhergesagt wird, gewinnt. Dieses Verfahren liefert stabilere Ergebnisse als ein einzelnes Modell.
Endvorhersage
Durch die Kombination der Vorhersagen mehrerer Modelle reduziert Bagging den Einfluss von Fehlern einzelner Modelle und verbessert so die Gesamtgenauigkeit. Dieser Aggregationsprozess macht Bagging zu einer besonders wirkungsvollen Technik im Bereich ML – insbesondere wenn Modelle mit hoher Varianz wie Entscheidungsbäume zum Einsatz kommen. Inkonsistenzen in den Vorhersagen einzelner Modelle werden dadurch ausgeglichen, was zu einem stärkeren Gesamtmodell führt.
Bagging stabilisiert Vorhersagen zuverlässig, aber einige Punkte sollten beachtet werden: Sind die Basismodelle zu komplex, besteht trotz des eigentlichen Ziels von Bagging – Overfitting zu reduzieren – weiterhin das Risiko, dass es auftritt.
Das Verfahren ist außerdem rechenintensiv. Es kann helfen, die Anzahl der Basis-Lerner anzupassen oder effizientere Ensemble-Methoden in Betracht zu ziehen, und Die richtige GPU für ML und DL auswählen ist immer wichtig.
Sorge für ausreichend Modellvielfalt unter den Basis-Lernern, um bessere Ergebnisse zu erzielen. Bei unausgewogenen Daten können Techniken wie SMOTE vor dem Anwenden von Bagging hilfreich sein, um schlechte Leistung bei Minderheitsklassen zu vermeiden.
Anwendungsfälle von Bagging
Nachdem wir uns angesehen haben, wie Bagging funktioniert, schauen wir uns an, wo es in der Praxis eingesetzt wird. Bagging hat in verschiedenen Branchen Einzug gehalten und verbessert dort die Genauigkeit und Stabilität von Vorhersagen in komplexen Szenarien. Hier sind einige der wichtigsten Anwendungsbereiche:
- Klassifikation und Regression: Bagging wird häufig eingesetzt, um die Leistung von Klassifikatoren und Regressoren zu verbessern, indem es die Varianz reduziert und Overfitting verhindert. Random Forests beispielsweise nutzen Bagging und erzielen gute Ergebnisse bei Aufgaben wie Bildklassifikation und Vorhersagemodellierung.
- Anomalieerkennung: In Bereichen wie Betrugserkennung und Netzwerkeinbruchserkennung liefern Bagging-Algorithmen starke Ergebnisse, indem sie Ausreißer und Anomalien in Daten zuverlässig identifizieren.
- Finanzielle Risikobewertung: Im Bankwesen werden Bagging-Techniken eingesetzt, um Kreditbewertungsmodelle zu verbessern und die Genauigkeit bei Kreditentscheidungen sowie Risikoanalysen zu erhöhen.
- Medizinische Diagnostik: Im Gesundheitswesen wird Bagging zur Erkennung neurokognitiver Erkrankungen wie Alzheimer eingesetzt, indem MRI-Datensätze analysiert werden. Das unterstützt die Frühdiagnose und Therapieplanung.
- Verarbeitung natürlicher Sprache (NLP): Bagging verbessert Aufgaben wie Textklassifikation und Stimmungsanalyse, indem es Vorhersagen mehrerer Modelle zusammenführt und so zu einem besseren Sprachverständnis führt.
Vor- und Nachteile von Bagging
Wie jede Machine-Learning-Technik hat Bagging seine eigenen Stärken und Schwächen. Wer diese kennt, kann besser einschätzen, wann und wie Bagging sinnvoll eingesetzt werden sollte.
Vorteile von Bagging:
- Reduziert Varianz und Overfitting: Einer der größten Vorteile von Bagging im Machine Learning ist die Fähigkeit, die Varianz zu reduzieren und damit Overfitting zu verhindern. Indem mehrere Modelle auf unterschiedlichen Teilmengen der Daten trainiert werden, wird sichergestellt, dass das Modell nicht zu empfindlich auf Schwankungen in den Trainingsdaten reagiert. Das Ergebnis ist ein Modell, das besser generalisiert und stabiler arbeitet.
- Besonders effektiv bei Modellen mit hoher Varianz: Bagging ist besonders dann wirkungsvoll, wenn es mit Modellen mit hoher Varianz wie Entscheidungsbäumen kombiniert wird. Diese Modelle neigen dazu, die Daten zu overfitten, aber Bagging wirkt dem entgegen, indem es Vorhersagen über mehrere Modelle hinweg mittelt oder per Abstimmung kombiniert. Das macht Vorhersagen zuverlässiger und weniger anfällig für Rauschen in den Daten.
- Verbessert Modellstabilität und Leistung: Die Kombination mehrerer Modelle, die auf unterschiedlichen Datenteilmengen trainiert wurden, führt häufig zu besserer Gesamtleistung. Bagging erhöht die Vorhersagegenauigkeit und reduziert gleichzeitig die Empfindlichkeit des Modells gegenüber kleinen Änderungen im Datensatz, was das Modell insgesamt verlässlicher macht.
Nachteile von Bagging:
- Höherer Rechenaufwand: Da Bagging das Training mehrerer Modelle erfordert, steigt der Rechenaufwand entsprechend. Das Trainieren und Zusammenführen der Vorhersagen vieler Modelle kann zeitaufwändig sein, besonders bei großen Datensätzen oder komplexen Modellen wie Entscheidungsbäumen.
- Wenig Nutzen bei Modellen mit geringer Varianz: Während Bagging bei Modellen mit hoher Varianz sehr effektiv ist, bringt es bei Modellen mit geringer Varianz wie der linearen Regression kaum Vorteile. In diesen Fällen haben die einzelnen Modelle bereits niedrige Fehlerraten, sodass das Aggregieren der Vorhersagen die Ergebnisse kaum verbessert.
- Eingeschränkte Interpretierbarkeit: Durch die Kombination mehrerer Modelle kann Bagging die Interpretierbarkeit des endgültigen Modells verringern. Im Random Forest beispielsweise basiert die Entscheidungsfindung auf vielen Entscheidungsbäumen, was es schwieriger macht, die Grundlage einer bestimmten Vorhersage nachzuvollziehen.
Wann sollte ich Bagging einsetzen?
Den richtigen Zeitpunkt für den Einsatz von Bagging in Machine-Learning-Projekten zu kennen, ist entscheidend für gute Ergebnisse. Die Methode funktioniert in bestimmten Situationen gut, ist aber nicht für jedes Problem die beste Wahl.
Wenn dein Modell zu Overfitting neigt
Bagging bietet sich vor allem an, wenn dein Modell zu Overfitting neigt, insbesondere bei Modellen mit hoher Varianz wie Entscheidungsbäumen. Diese Modelle können auf Trainingsdaten gut abschneiden, verallgemeinern aber oft schlecht auf unbekannte Daten, weil sie sich zu stark an die spezifischen Muster des Trainingssets anpassen.
Bagging wirkt dem entgegen, indem mehrere Modelle auf verschiedenen Teilmengen der Daten trainiert und ihre Vorhersagen gemittelt oder per Mehrheitsvotum zusammengeführt werden. Das verringert die Overfitting-Gefahr und macht das Modell besser im Umgang mit neuen, unbekannten Daten.
Wenn du Stabilität und Genauigkeit verbessern möchtest
Wer die Stabilität und Genauigkeit seines Modells verbessern möchte, ohne dabei zu viel Interpretierbarkeit einzubüßen, trifft mit Bagging eine gute Wahl. Die Aggregation der Vorhersagen mehrerer Modelle macht das Endergebnis zuverlässiger, was besonders bei verrauschten Daten von Vorteil ist.
Ob Klassifikationsaufgaben oder Regressionsprobleme: Bagging liefert konsistentere Ergebnisse und steigert die Genauigkeit, ohne die Effizienz wesentlich zu beeinträchtigen.
Wenn ausreichend Rechenressourcen vorhanden sind
Ein weiterer wichtiger Faktor bei der Entscheidung für Bagging ist die Verfügbarkeit von Rechenressourcen. Da Bagging mehrere Modelle gleichzeitig trainiert, kann der Rechenaufwand erheblich sein, besonders bei großen Datensätzen oder komplexen Modellen.
Stehen die nötigen Ressourcen zur Verfügung, überwiegen die Vorteile von Bagging klar die Kosten. Bei begrenzten Ressourcen kann es sinnvoll sein, alternative Methoden zu prüfen oder die Anzahl der Modelle im Ensemble zu reduzieren.
Wenn du mit Modellen hoher Varianz arbeitest
Bagging ist besonders nützlich bei Modellen mit hoher Varianz, die empfindlich auf Schwankungen in den Trainingsdaten reagieren. Entscheidungsbäume werden zum Beispiel häufig in Form von Random Forests mit Bagging kombiniert, weil ihre Leistung stark von den Trainingsdaten abhängen kann.
Indem mehrere Modelle auf verschiedenen Datenteilmengen trainiert und ihre Vorhersagen kombiniert werden, glättet Bagging die Varianz und führt zu einem zuverlässigeren Modell.
Wenn du einen stabilen Klassifikator benötigst
Wer an Klassifikationsproblemen arbeitet und einen stabilen Klassifikator braucht, kann mit Bagging die Vorhersagequalität deutlich verbessern. Ein Random Forest, der ein klassisches Beispiel für einen Bagging-Klassifikator ist, liefert genauere Vorhersagen, indem er die Ergebnisse vieler einzelner Entscheidungsbäume zusammenführt.
Dieser Ansatz funktioniert gut, wenn einzelne Modelle schwach sind, ihre kombinierte Stärke aber zu einem insgesamt leistungsfähigen Modell führt.
Wenn du außerdem nach der richtigen Plattform suchst, um Bagging-Techniken effizient einzusetzen, bieten Tools wie Databricks und Snowflake bieten eine einheitliche Analyseplattform, die sich gut für die Verwaltung großer Datensätze und die Ausführung von Ensemble-Methoden wie Bagging eignet.
Wer einen weniger technischen Einstieg in Machine Learning sucht, No-Code-KI-Tools können ebenfalls eine Option sein. Auch wenn sie nicht direkt auf fortgeschrittene Techniken wie Bagging ausgerichtet sind, ermöglichen viele No-Code-Plattformen das Experimentieren mit Ensemble-Lernmethoden, einschließlich Bagging, ohne umfangreiche Programmierkenntnisse.
So lassen sich anspruchsvollere Techniken einsetzen und dennoch präzise Vorhersagen erzielen, während der Fokus auf der Modellleistung liegt, nicht auf dem zugrunde liegenden Code.
Fazit
Bagging ist eine leistungsstarke Technik im Machine Learning, die die Modellleistung verbessert, indem sie die Varianz reduziert und die Stabilität erhöht. Durch die Aggregation der Vorhersagen mehrerer Modelle, die auf verschiedenen Datenteilmengen trainiert wurden, liefert Bagging genauere und zuverlässigere Ergebnisse. Besonders wirksam ist es bei Modellen mit hoher Varianz wie Entscheidungsbäumen, da es Overfitting verhindert und die Generalisierung auf unbekannte Daten verbessert.
Bagging bietet klare Vorteile wie die Reduzierung von Overfitting und höhere Genauigkeit, bringt aber auch Kompromisse mit sich. Das Training mehrerer Modelle erhöht den Rechenaufwand, und die Interpretierbarkeit kann darunter leiden. Trotz dieser Nachteile ist Bagging dank seiner Leistungsverbesserungen eine wertvolle Technik im Ensemble Learning, gleichwertig zu anderen Methoden wie Boosting und Stacking.
Haben Sie Bagging bereits in Machine-Learning-Projekten eingesetzt? Teilen Sie Ihre Erfahrungen und berichten Sie, wie es für Sie funktioniert hat!


