GPU-Monitoring-Software kann aus einem vagen "meine GPU fühlt sich seltsam an" eine klare Aussage machen, wie etwa: "Hotspot-Temperatur gestiegen, Taktraten gedrosselt und VRAM voll."
In diesem Leitfaden zeige ich dir, welche Tools sich für KI-Jobs, Gaming-Overlays und lange Workstation-Sitzungen eignen, und erkläre, welche GPU-Metriken dir helfen, Verlangsamungen, Ruckler und Abstürze zu diagnostizieren.
Am Ende hast du ein GPU-Monitoring-Setup, das zu deiner Arbeitsweise passt. Außerdem bekommst du fertige Stacks für vier gängige Anwendungsfälle, damit du nicht jedes Mal neu suchen musst.
Kurzübersicht: Die besten GPU-Monitoring-Tools nach Anwendungsfall
Wenn du einfach eine kompakte Liste willst, die an der Praxis orientiert ist, fang hier an. In der Praxis ist der beste GPU-Monitoring-Stack meist eine Kombination: ein Tool für schnelle Checks, eines für Overlays oder Logs und eines für Verlaufsanalysen oder Benachrichtigungen.
Die Kurzübersicht:
| Anwendungsfall | Empfohlener Einstiegs-Stack | Was du bekommst |
| KI-Training, Inferenz, HPC-Jobs | nvidia-smi (NVIDIA) oder AMD SMI (AMD) + Logging/Exporter | Schnelle Checks, skriptfähige Logs, einfaches Alerting |
| Gaming auf Windows | MSI Afterburner + RTSS + ein Frametime-Capture-Tool | Overlay plus Nachweis für Ruckler vs. niedrige FPS |
| Gaming auf Linux | MangoHud + ein Terminal-Tool (nvtop) | Leichtes Overlay mit prozessspezifischen Integritätsprüfungen |
| Workstations (3D/Video/CAD) | HWiNFO-Protokollierung + ein einfacher Stresstest | Ausführliche Logs zum Teilen, reproduzierbare Fehlerbilder |
| Gemeinsam genutzte GPU-Maschinen | nvtop (Linux) + Exporter/Dashboard | Prozessspezifische VRAM-Übersicht |
Ab hier geht es hauptsächlich darum, die passende GPU-Monitoring-Software für die eigene Arbeitsweise zu finden: ob auf dem Bildschirm, in einem Log oder in einem Dashboard.
Für wen dieser Guide gedacht ist
Ich schreibe das so, wie jemand, der echte Maschinen debuggen musste. Aus Erfahrung weiß ich: Verschiedene Leser brauchen unterschiedliche GPU-Tools, auch wenn sie auf dieselbe GPU schauen.
Das sind die vier Szenarien, auf die ich eingehe:
- Der Model Builder (AI/ML): interessiert sich für VRAM-Reserven, anhaltende Taktraten, Throttling und die Frage: "Hat der Job die ganze Nacht durchgelaufen?"
- Der Competitive-Gamer/Streamer: interessiert sich für Frametimes, Overlay-Stabilität und Regressionen nach Treiberupdates.
- Der Workstation-Nutzer (3D/Video/CAD): interessiert sich für Logs, reproduzierbare Abstürze und die genaue Ursache: Hitze, Leistungsaufnahme oder Treiberverhalten.
- Der Admin mit GPU-Maschinen: interessiert sich für Alarme, Trendgraphen, Kapazitätsplanung und frühzeitiges Erkennen von Fehlern.
Wer weiß, in welche Kategorie er fällt, kann die passende GPU-Monitoring-Software schnell auswählen.
Die richtige GPU-Monitoring-Software auswählen
Viele Performance-Monitoring-Apps sehen ähnlich aus, bis man sie eine Woche lang im Einsatz hat. Der entscheidende Unterschied liegt meistens in der Ausgabe und der Zuverlässigkeit, nicht in den attraktiven "Features", mit denen jede App um sich wirbt.
Hier sind drei Fragen, die bei der schnellen Auswahl von GPU-Monitoring-Software helfen:
- Brauche ich ein Overlay, ein Log oder beides?
Gamer wollen ein Overlay. AI- und Workstation-Arbeit erfordert meist Logging. Admins brauchen Logs und Alarme. - Benötigen Sie Einblick in einzelne Prozesse?
Wenn du dir eine Maschine teilst (Labor, Studio, Remote-Server), ist der prozessspezifische VRAM oft das Erste, wonach du suchst. - Benötigen Sie Verlaufsdaten und Benachrichtigungen?
Wenn Jobs über Nacht laufen, reicht "Ich schau später rein" nicht aus. Du willst ein Diagramm und eine Benachrichtigung.
Um es praktisch zu halten, ist der Rest des Leitfadens nach GPU-Metriken gegliedert – zuerst die Metriken, dann die Tool-Stacks, die zum jeweiligen Anwendungsfall passen.
GPU Metriken, auf die es wirklich ankommt
Good GPU-Monitoring-Software liefert jede Menge Zahlen. Wirklich nützliche GPU-Monitoring-Software liefert dir genau die wenigen, die das Verhalten erklären. Ich gruppiere GPU-Metriken nach der Entscheidung, bei der sie helfen.
Temperatur- und Drosselungsmetriken
Das sind die GPU-Metriken, die erklären, warum es 10 Minuten lang schnell war und dann nicht mehr:
- GPU Temperatur
- Hotspot-Temperatur (oft das Erste, was in die Höhe schießt)
- Speichertemperatur/Übergangstemperatur (besonders relevant bei langen KI-Prozessen und aufwendigen Render-Jobs)
- Lüfterdrehzahl (hilft dabei, Laptop-Profile oder fehlerhafte Lüfterkurven zu erkennen)
Wenn du die Stabilität verbessern möchtest, protokolliere diese Werte – einzelne Momentaufnahmen liefern selten genug Informationen.
Leistung, Taktraten und Limits
Diese GPU-Metriken erklären das Downclocking und die inkonsistente Performance:
- Board-Leistungsaufnahme
- Kern- und Speichertakt
- Leistungslimit/Leistungszustand (falls dein Tool das anbietet)
Bei echtem Debugging zeigen dir Power- und Clock-Metriken oft mehr als eine bloße «GPU usage %».
VRAM und Speicherauslastung
Diese GPU-Metriken erklären Stottern, OOM-Fehler und die typischen "zufälligen" Langsamkeiten:
- VRAM verwendet vs. gesamt
- Speichercontroller-Aktivität (hilft dabei, Bandbreitenlimits zu erkennen)
- System RAM Druck (weil ein Überlauf bei VRAM das gesamte System zum Absturz bringen kann)
Für KI-Workloads ist VRAM oft das harte Limit. Bei Spielen macht sich VRAM-Druck zuerst als Frametime-Spikes bemerkbar.
Frametime- und Frame-Pacing-Metriken
Beim Gaming und Streaming kann die reine FPS-Zahl täuschen. Die entscheidende Kennzahl ist die Frametime – sie zeigt, wie gleichmäßig die Darstellung tatsächlich läuft:
- Frametime (ms)
- 1% Low / 0,1% Low (gut zum Vergleichen)
- GPU belegt vs. CPU belegt (hilft dabei, GPU-Engpässe von CPU-Engpässen zu unterscheiden)
Daher bieten auf Gaming ausgerichtete Performance-Monitoring-Apps oft eine Frametime-Erfassung an. Nachdem wir die grundlegenden Metriken geklärt haben, kommen wir zu den besten GPU-Monitoring-Software-Stacks für die jeweiligen Anwendungsfälle.
GPU Monitoring-Software für KI, Training und Server

KI-Monitoring lässt sich einfach einrichten: Ein paar Befehle im Terminal genügen, und für längere Läufe gibt es Logs und Alerts. Dafür eignet sich GPU-Monitoring-Software, die CLI-kompatibel ist und Metriken exportiert.
NVIDIA: nvidia-smi für schnelle Statusprüfungen und skriptfähige Logs
Auf NVIDIA-Systemen, nvidia-smi ist meist der erste Befehl, den man ausführt, weil er zusammen mit dem Treiber ausgeliefert wird und für das Monitoring und die Verwaltung über NVML ausgelegt ist.
Die offizielle Dokumentation findest du hier: NVIDIA-Systemverwaltungsschnittstelle (nvidia-smi).
Wenn du einen einfachen Ansatz bevorzugst – "Eintrag schreiben und später ansehen" – (und es ist überraschend oft, wie oft das das Problem löst), ist dieses Muster sehr zuverlässig:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
Dies ist das grundlegende Verhalten von GPU-Monitoring-Software: Zeitstempel, zentrale GPU-Metriken und eine Ausgabe, die sich gut mit Skripten verarbeiten lässt.
AMD: AMD SMI für ROCm- und HPC-Nodes
Auf AMD Linux Compute-Nodes ist AMD SMI die moderne Monitoring- und Management-Schnittstelle. AMD dokumentiert es als einheitliches Toolset für Monitoring und Steuerung in HPC-Umgebungen.
Die offizielle Dokumentation findest du hier: AMD SMI Dokumentation.
In AMD-lastigen Umgebungen bildet AMD SMI die Grundlage für GPU-Monitoring, auf der andere Tools typischerweise aufbauen.
Prozessbasierte Sichtbarkeit: nvtop für gemeinsam genutzte GPUs
Wer schon einmal einen gemeinsam genutzten Server hatte, auf dem VRAM "rätselhaft" voll blieb, weiß, wie viel Zeit prozessbasierte Sichtbarkeit spart. Auf Linux ist nvtop genau aus diesem Grund beliebt: Es macht sofort klar, wer gerade VRAM belegt. Auf AMD/Intel kann für prozessgenaue Statistiken ein aktueller Kernel erforderlich sein.
In gemischten Teams sehe ich häufig, dass Leute nvtop parallel mit nvidia-smi oder AMD SMI ausführen. Diese einfache Kombination vermeidet viel Raterei - ich empfehle sie ausdrücklich.
Hardware-Wahl nicht vernachlässigen!
Monitoring beseitigt kein VRAM-Limit, es macht das Limit nur sichtbar. Wenn du Workloads noch GPU-Tiers zuordnest, bietet unser Leitfaden zu Die besten GPUs für Machine Learning 2025 eine hilfreiche Ergänzung, da er VRAM und Bandbreite genauso aufschlüsselt, wie du sie später in Logs und Dashboards abliest.
Sobald das server-seitige GPU-Monitoring unter Kontrolle ist, folgt der nächste Schritt: Overlays und Frametimes. Denn interaktive Workloads verhalten sich anders.
GPU-Monitoring-Software für Gaming und Streaming

Beim Gaming haben die meisten die stärksten Meinungen zu GPU-Tools - vor allem, weil Overlays genau dann versagen, wenn man sie am meisten braucht. Für Gaming brauchst du einfache Overlays und reproduzierbare Frametime-Aufzeichnungen.
MSI Afterburner + RTSS für Overlays auf Windows
Diese Kombination ist weit verbreitet, weil du ein übersichtliches Overlay mit genau den GPU-Metriken aufbauen kannst, die dich interessieren - etwa Auslastung, Taktfrequenz, VRAM, Temperaturen, Frametime und optional Lüfterdrehzahl.
In Community-Threads taucht immer wieder eine ernste Warnung auf: gefälschte Download-Seiten. MSIs eigene Afterburner-Seite weist darauf hin, dass legitime Downloads von msi.com und Guru3Dstammen sollten. Dort ist auch die aktuelle Release-Version aufgeführt (4.6.6 final, veröffentlicht Oktober 2025).
Overlay-Probleme sind ein weiterer Fallstrick. RTSS funktioniert beispielsweise in manchen Spielen und versagt in anderen - besonders bei modernen Render-Pfaden. Nutzer berichten von Fällen, in denen das Overlay erscheint in Vulkan, aber nicht in DX12 beim gleichen Titel, oder verschwindet nach Updates.
Das liegt jedoch nicht an einem Fehler Ihrerseits, sondern daran, dass Overlays sich in sich ständig ändernde Spiel- und Treiber-Stacks einhängen.
Für ein stabiles Basis-Overlay gilt: weniger ist mehr:
- Frametime
- GPU-Auslastung
- RAM verwendet
- GPU Temperatur
Füge Power und Clocks nur hinzu, wenn du aktiv Throttling debuggst.
Frametime-Aufzeichnung bei Rucklern
Hier helfen Performance-Monitoring-Apps, die Frametime-Graphen aufzeichnen können, wirklich weiter. Die durchschnittliche FPS kann gut aussehen, während sich das Frame-Pacing furchtbar anfühlt. Frametime-Graphen lösen diese Unklarheit schnell.
Viele Gaming-Benchmark-Workflows nutzen im Hintergrund PresentMon, und NVIDIA dokumentiert dass seine FrameView-Analyse PresentMon für die Erfassung von Framerate und Frametime verwendet.
Sie müssen nicht jedes Spiel benchmarken. Frametime-Aufzeichnungen sind vor allem für Vergleiche nützlich: vor und nach einem Treiber-Update, vor und nach dem Ändern eines Limiters, vor und nach dem Anpassen von Einstellungen und so weiter.
MangoHud für Linux-Overlays
Unter Linux wird MangoHud häufig empfohlen, weil es leichtgewichtig ist und sich sauber in Steam/Proton-Setups integriert. Die häufigsten Kritikpunkte betreffen fehlende Sensoren oder seltsame Messwerte bei Hybrid-Laptop-Konfigurationen.
In der Praxis lässt sich MangoHud problemlos mit einem Terminal-Tool wie nvtopkombinieren. Das ist auch ein gutes Beispiel dafür, wie GPU-Monitoring-Software als kleiner, fokussierter Stack deutlich besser funktioniert als eine einzige riesige Monolith-App.
Von Gaming aus ist der nächste logische Schritt das Workstation-Monitoring, denn dort sind Logs und reproduzierbare Fehleranalyse die eigentlichen Prioritäten.
Hosten Sie laggfreie Gameserver mit Hochgeschwindigkeits-NVMe-VPS-Hosting.
VPS für Gaming
GPU-Monitoring-Software für Workstations und professionelle Anwendungen
Workstation-Monitoring ist weit weniger eine Frage der Live-Überwachung wie bei einem Sicherheitsdienst, sondern geht eher darum, die Frage zu beantworten: Was ist im Laufe der Zeit passiert, und lässt es sich reproduzieren?
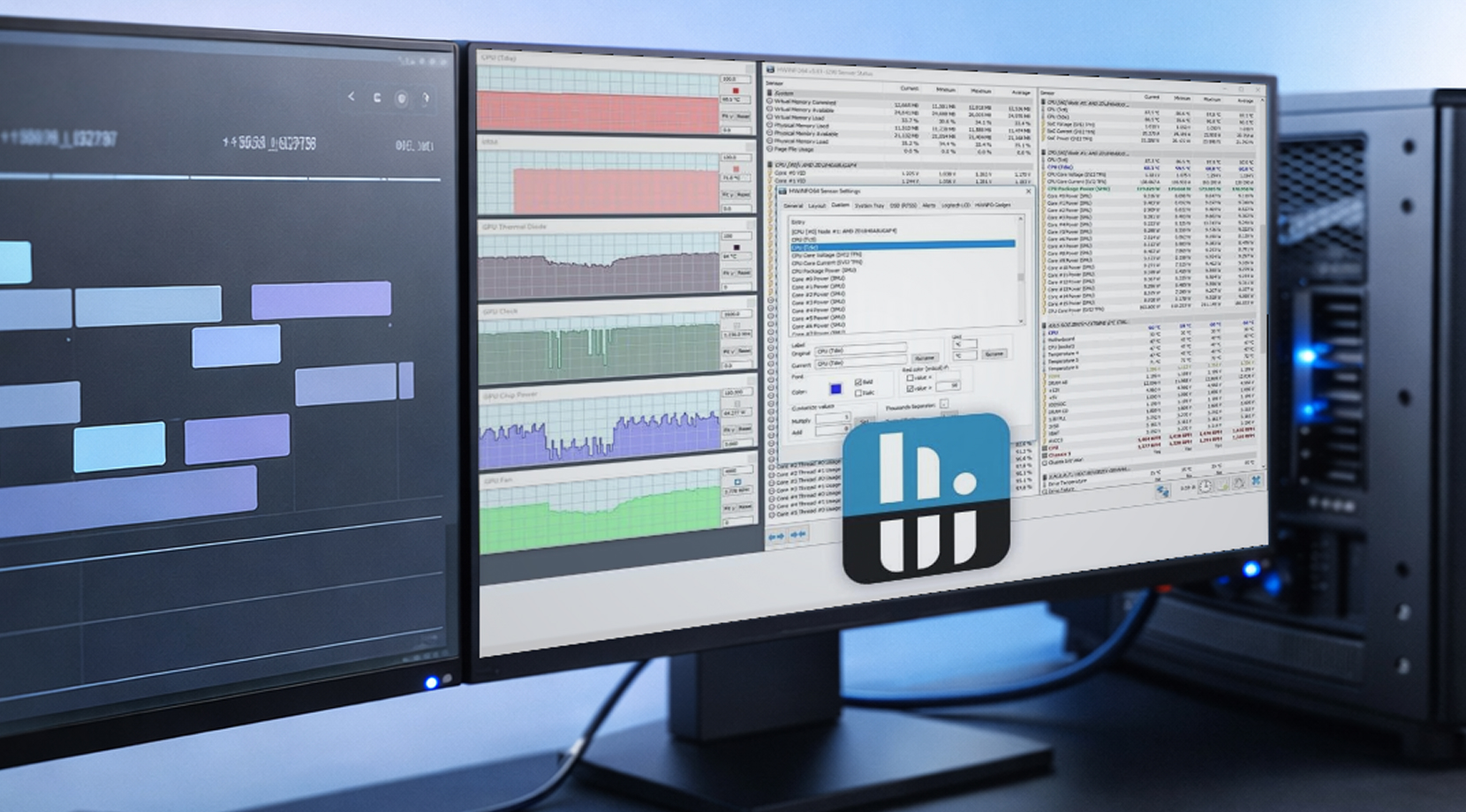
HWiNFO für die Protokollierung auf Windows
HWiNFO ist in Workstation-Kreisen beliebt, weil es eine umfangreiche Sensorabdeckung und einfach teilbare Logs bietet. Ein schlichtes CSV-Log mit Zeitstempeln kann aus einem vagen Fehlerbericht etwas machen, mit dem sich Probleme gezielt beheben lassen.
Wenn Sie ein Workstation-Log zur GPU-Stabilitätsanalyse aufbauen, beginnen Sie mit diesen GPU-Metriken:
- GPU Temperatur und Hotspot
- RAM verwendet
- Board-Leistung
- Kerntakt
- CPU Paketleistung (denn Plattform-Leistungslimits können sich rächen)
Das sind genau die Daten, die zur Erklärung nötig sind. Würde man jeden Sensor mitloggen, wäre die Datei nur schwerer lesbar.
GPU-Z für schnelle "Welche GPU ist das?"-Überprüfungen
GPU-Z bleibt praktisch, weil es schnell und auf das Wesentliche fokussiert ist. In Teams mit unterschiedlicher Hardware ist es der einfachste Weg, das GPU-Modell, grundlegende Treiberdaten und aktive Sensoren zu prüfen, ohne sich durch Menüs zu klicken.
Stresstesting: Nur sinnvoll mit Logging
Stresstests können einen Absturz reproduzieren, aber nur wenn deine GPU-Monitoring-Software dabei mitloggt. Ohne diese Logs bleibt dir nur "schon wieder abgestürzt" – ohne jeden Zeitstempel.
An diesem Punkt stoßen die meisten auf dieselben Probleme: Overlays, die nicht angezeigt werden, fehlerhafte Leistungswerte und unlesbare Logs. Gehen wir diese direkt an.
Häufige Probleme mit GPU-Monitoring-Software und schnelle Lösungen

Die meisten Probleme folgen bekannten Mustern. Diese Lösungen probiere ich zuerst – sie beseitigen die häufigen Ursachen schnell und unkompliziert.
Overlay fehlt im Spiel
Wenn ein Overlay in einem aktuellen Spiel verschwindet, liegt es oft an einem spielspezifischen Hook-Problem oder einem Konflikt mit Anti-Cheat- oder Anti-Tamper-Schichten.
Was oft hilft:
- RTSS aktualisieren und das spielspezifische Profil zurücksetzen
- Legen Sie eine höhere "application detection level" für das Spielprofil fest
- Versuche es mit einer anderen API, falls das Spiel dies unterstützt
- Auf eingebaute Overlays zurückfallen, wenn ein Titel Drittanbieter-Overlays blockiert
Nicht jedes Spiel lässt sich problemlos einrichten – manche Titel fressen mehr Zeit, als sie wert sind.
Merkwürdige Leistungswerte (0W, Flatline, fehlende Sensoren)
Das tritt häufig bei Laptops und Hybrid-Setups auf, wo sich die aktive GPU ändern kann. Zur Sicherheit empfiehlt sich in solchen Fällen eine Überprüfung mit einem zweiten Tool, zum Beispiel nvidia-smi (NVIDIA) oder AMD SMI (AMD) eignen sich gut, um zu prüfen, ob die GPU tatsächlich aktiv ist.
Zu viele Log-Einträge
Überabtastung ist meistens der Grund. Für die meisten Diagnosen reichen 1 bis 5 Sekunden aus. Bei langen AI-Jobs sind 5 Sekunden völlig ausreichend. Kürzere Intervalle lassen die Dateigröße schnell anwachsen und erschweren das Lesen der Diagramme.
Sobald diese Grundlagen abgedeckt sind, ist Remote-Monitoring der nächste logische Schritt, da viele GPU-Workflows inzwischen außerhalb des lokalen Rechners laufen.
Remote-GPU-Monitoring und eine praktische Cloud-Option
Beim Remote-Arbeiten verändert sich, was "gute GPU-Monitoring-Software" bedeutet. Man sitzt nicht immer direkt vor dem Rechner, also braucht man Prüfungen, die sich schnell ausführen lassen, und einen Verlauf, den man später einsehen kann.
Ein sauberes Remote-Setup sieht typischerweise so aus:
- CLI-Prüfungen (nvidia-smi oder AMD SMI)
- eine Log-Datei, die man später abrufen kann
- ein Exporter/Dashboard, wenn Benachrichtigungen benötigt werden
Wenn lokale Hardware den Fortschritt bremst, sei es durch VRAM-Limits, das Teilen einer einzelnen GPU oder den Bedarf nach einer sauberen Umgebung pro Projekt, ist das Auslagern von Workloads auf eine GPU VPS oft der einfachste Weg, weiterzumachen.
Cloudzy GPU VPS

Wer remote GPU-Zeit für AI-, Gaming- und Rendering-Workflows sucht, findet in unserem Cloudzy GPU VPS NVIDIA-Optionen wie RTX 5090, A100 und RTX 4090, dazu NVMe-Speicher, vollständigen Root-Zugriff, bis zu 40 Gbps Anbindung, DDoS-Schutz und ein angestrebtes Uptime-Ziel von 99,95 %.
Aus Monitoring-Sicht verhält sich das wie ein normaler Rechner: Man kann GPU-Monitoring-Software über SSH betreiben, GPU-Metriken für lange Jobs protokollieren und bei Bedarf Dashboards für Verlauf und Benachrichtigungen einrichten.
Wer noch zwischen einer GPU-Instanz und einem reinen CPU-Setup abwägt, findet in unseren Artikeln zu Was ist ein GPU-VPS? und GPU vs. CPU VPS eine praxisnahe Gegenüberstellung nach Workload-Typ.
Nachdem Remote-Monitoring behandelt wurde, geht es im letzten Schritt darum, alles zu kopierbaren Stacks zusammenzuführen.
Kopierbare Stacks für jeden Anwendungsfall
Hier sind einfach umsetzbare Stacks, die sich ohne großen Umbau des bestehenden Workflows übernehmen lassen. Sie dienen als solider Ausgangspunkt und lassen sich später an die eigenen Anforderungen anpassen.
- Modell-Generator (AI/ML): GPU-Monitoring-Software per nvidia-smi oder AMD SMI, dazu ein einfaches CSV-Log und ein Exporter/Dashboard für unbeaufsichtigt laufende Jobs.
- Competitive-Gamer/Streamer: GPU-Monitoring-Software als Overlay per Afterburner + RTSS, dazu ein Frametime-Capture-Tool für Vergleiche und ein minimales On-Screen-Metrik-Set.
- Workstation-Nutzer: GPU-Monitoring-Software per HWiNFO-Logging, dazu GPU-Z für schnelle Identitätsprüfungen und einen Stresstest, wann immer der Durchlauf protokolliert werden kann.
- Admin läuft auf GPU-Maschinen: GPU Monitoring-Software als Service: Exporter, Dashboards und Alerts – plus prozessgenaue Sichtbarkeit (nvtop) für geteilte Server.
Wenn Sie nur eine Sache aus diesem Leitfaden mitnehmen, dann diese: Wählen Sie GPU-Monitoring-Software danach aus, wo Sie die Daten benötigen (Overlay, Log, Dashboard) – und halten Sie Ihre Metriken überschaubar genug, damit Sie sie auch wirklich nutzen.