
Anda membuka halaman GGUF sebuah model populer di Hugging Face dan ada lima belas file yang menatap balik: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, plus folder terpisah untuk GPTQ, AWQ, dan EXL2 dengan setengah lusin pengaturan bit. Anda melakukan hitungan kasar untuk file "4-bit": 4 bit × 8 miliar parameter ÷ 8 = 4 GB. Tapi file itu menyebut 4,6 GB. Dan setelah dimuat, model menggunakan memori lebih banyak dari itu.
Nama file bukan sekadar noise. Mereka mengkodekan informasi nyata dan bisa dipelajari tentang lebar bit, runtime yang memuatnya, dan perangkat keras yang dibutuhkan. Tabel ukuran yang pernah Anda baca memberi tahu Anda bahwa model 70B membutuhkan sekitar 40 GB, berguna, tetapi mereka tidak pernah menguraikan format itu sendiri atau menjelaskan mengapa model yang berjalan membutuhkan memori lebih banyak daripada file di disk.
Jadi inilah rencananya: menguraikan konvensi penamaan GGUF (dengan lebar bit yang sebenarnya, bukan yang nominal), memilah format mana dari keempatnya yang benar-benar dapat dijalankan perangkat keras Anda, dan memperhitungkan satu biaya memori yang tidak terlihat di setiap ukuran file, yaitu KV cache. Pada akhirnya Anda akan bisa membaca repo model dan memprediksi perilakunya saat dimuat.
TL;DR
- Level kuantisasi GGUF adalah lebar bit efektif, bukan angka pasti dalam namanya. Q4_K_M sekitar 4,89 bit per bobot, itulah sebabnya file 8B "4-bit" berukuran sekitar 4,6 GiB, bukan estimasi 4-bit yang naif.
- GGUF adalah opsi paling portabel karena llama.cpp dapat menjalankannya di CPU, GPU, atau setup hybrid. GPTQ, AWQ, dan EXL2 lebih spesifik terhadap GPU dan runtime, dengan EXL2 khususnya terikat pada alur kerja NVIDIA/CUDA.
- KV cache terpisah dari bobot model, dan tumbuh seiring panjang konteks. Inilah alasan mengapa model yang dimuat dengan bersih tetap bisa crash karena kehabisan memori begitu percakapan menjadi panjang.
- Di atas rentang 5-bit, penurunan kualitas biasanya kecil. Sekitar Q4, trade-off-nya masih praktis untuk banyak kasus penggunaan lokal. Di bawah 4-bit, biaya kualitas menjadi jauh lebih terasa. Q4_K_M tetap menjadi default komunitas yang umum, sementara Q5_K_M dan Q6_K lebih aman ketika Anda punya memori berlebih.
Apa Arti Q4_K_M dalam Nama File GGUF?

Nama kuantisasi GGUF mengikuti pola Q[bit]_[K]_[S/M/L]. Angkanya adalah target bit per bobot, K berarti ini adalah "K-quant" yang menyimpan faktor penskalaan per blok kecil bobot, dan S, M, atau L di akhir adalah tingkat ukuran/kualitas (kecil, sedang, besar). Karena K-quant menyimpan skala dan nilai minimum untuk setiap blok bersama bobotnya, efektif lebar bit lebih tinggi daripada angka yang tertera di judul. Q4_K_M berada di sekitar 4,89 bit per bobot, bukan 4.
Selisih itulah jawaban lengkap untuk pertanyaan "kenapa file 4-bit saya 4,6 GB?" Estimasi naif mengasumsikan setiap bobot berbiaya tepat 4 bit. Pada kenyataannya, K-quant menghabiskan bit ekstra per blok untuk metadata yang membuat kuantisasi bit-rendah akurat, yaitu skala dan nilai minimum per blok yang memungkinkan runtime merekonstruksi setiap bobot. Kalikan 4,89 bit dengan 8 miliar bobot dan Anda mendapatkan sekitar 4,58 GiB, itulah bobot sebenarnya dari file tersebut.
Berikut adalah lebar bit efektif dan ukuran file yang terukur, diambil dari llama.cpp quantize documentation untuk Llama 3.1 8B sebagai model referensi, beserta biaya perplexity setiap level yang diukur dalam paper evaluasi kuantisasi llama.cpp (arXiv:2601.14277) pada Llama-3.1-8B-Instruct:
| Level GGUF | BPW Efektif | ~Ukuran file (8B) | Perplexity vs F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | dasar |
*Angka perplexity ini spesifik untuk Llama-3.1-8B-Instruct dari arXiv:2601.14277. Kolom BPW/ukuran file dan kolom perplexity berasal dari dua sumber berbeda yang diukur secara terpisah, jadi bacalah tabel ini sebagai referensi praktis berdampingan, bukan satu hasil benchmark tunggal. Penurunan yang spesifik terhadap tugas bervariasi, penalaran matematika cenderung lebih terdampak dibanding penalaran commonsense pada lebar bit rendah, tetapi pola umumnya tetap berlaku: 5-bit ke atas biasanya lebih aman, Q4 adalah zona kompresi praktis, dan 3-bit adalah titik di mana penurunan kualitas menjadi jauh lebih sulit diabaikan.
Secara praktis: Q4_K_M adalah default yang sebaiknya dipilih kebanyakan orang, Q5_K_M dan Q6_K adalah pilihan yang mengutamakan kualitas saat Anda punya memori berlebih, dan apa pun di level Q3_K_S atau di bawahnya adalah pilihan terakhir untuk perangkat keras yang benar-benar tidak bisa menampung lebih banyak.
Format Kuantisasi Mana yang Harus Anda Unduh: GGUF, GPTQ, AWQ, atau EXL2?

GGUF adalah yang paling portabel dari keempatnya: ia berjalan di CPU, GPU, atau kombinasi hybrid keduanya melalui llama.cpp, sehingga menjadi pilihan paling aman ketika Anda tidak yakin apa yang bisa didukung perangkat keras Anda. GPTQ, AWQ, dan EXL2 lebih spesifik terhadap GPU dan runtime. Dalam praktiknya, mereka paling umum di setup NVIDIA/CUDA, tetapi dukungan GPTQ dan AWQ dapat bervariasi menurut loader dan serving stack; vLLM, misalnya, memisahkan dukungan kuantisasi berdasarkan perangkat keras dan implementasi. Jika Anda menjalankan secara lokal di Mac, kartu AMD, atau mesin khusus CPU, GGUF tetap jawaban paling aman. Jika Anda memiliki GPU NVIDIA dan ingin token secepat mungkin, ketiga format lainnya berperan.
| Format | Perangkat keras/runtime | Kecepatan (relatif) | VRAM dibanding format sejenis | Terbaik untuk |
|---|---|---|---|---|
| GGUF Q4_K_M | Paling luas, CPU, GPU, atau hybrid melalui llama.cpp | Sedang | Terendah | Perangkat keras apa pun; default lokal |
| GPTQ 4-bit | Biasanya mengutamakan CUDA/GPU; bergantung pada runtime | Cepat (ExLlama) | Menengah | Mengutamakan GPU, tooling lama |
| AWQ 4-bit | Biasanya mengutamakan CUDA/GPU; bergantung pada runtime | Cepat | Tertinggi | Serving vLLM/TGI, pemuatan cepat |
| EXL2 ~4,9 bpw | Mengutamakan NVIDIA/CUDA | Tercepat | Rendah-Sedang | Kecepatan maksimum di NVIDIA |
Catatan tentang tabel itu: peringkat kecepatan dan VRAM berasal dari benchmark oobabooga, yang dijalankan pada perangkat keras era 2023/2024. Perlakukan urutan relatif urutan itu sebagai sesuatu yang bertahan lama. EXL2 dibangun untuk kecepatan, AWQ menukar VRAM dengan pemuatan cepat, GGUF tetap ringan dan portabel, tetapi jangan baca angka token-per-detik absolut aslinya sebagai hal yang masih berlaku sekarang. GPU tahun 2026 akan menunjukkan throughput mentah yang sangat berbeda; urutan peringkatnyalah yang tetap berlaku.
Jadi aturan keputusan yang muncul dari sini: jika Anda punya kartu NVIDIA dan paling mementingkan kecepatan, pilih EXL2; jika Anda ingin default lokal paling aman di berbagai perangkat keras, pilih GGUF. AWQ dan GPTQ sebagian besar penting ketika serving stack tertentu (vLLM, TGI) atau tooling yang sudah ada mendorong Anda ke arah itu.
Mengapa LLM Lokal Menggunakan Memori Lebih Banyak daripada Filenya?
Ukuran file hanyalah bobot model. Pada saat runtime Anda juga membayar untuk KV cache (state attention untuk setiap token di jendela konteks Anda), aktivasi (perhitungan matematis perantara dari satu forward pass), dan overhead framework serta driver. Bagian-bagian non-bobot ini secara rutin menambah 10 hingga 20% di atas bobot untuk setup satu pengguna, dan KV cache saja bisa mengalahkan segalanya begitu konteks menjadi panjang. File berukuran 4,6 GB bisa membutuhkan memori jauh lebih dari 4,6 GB untuk berjalan.
Anggap memori runtime sebagai empat komponen yang bertumpuk satu sama lain:
- Bobot model. File yang Anda unduh. Ini satu-satunya bagian yang terlihat sebelum Anda memuatnya.
- KV cache. State attention untuk jendela konteks. Kecil pada konteks pendek, sangat besar pada konteks panjang. Ini adalah bagian berikutnya, karena inilah yang mengejutkan orang.
- Aktivasi. Memori kerja dari satu forward pass. Untuk inferensi lokal single-stream (ukuran batch 1), ini kecil, biasanya beberapa ratus megabyte.
- Overhead framework. Jejak runtime itu sendiri ditambah konteks driver GPU. Untuk runtime lokal yang ringan, ini bisa kecil dibandingkan bobot model dan KV cache; framework serving yang lebih berat dapat mencadangkan jauh lebih banyak. Cadangan memori sistem operasi Anda sendiri berada di luar ini dan terpisah lagi.
Bobot dan overhead framework dapat diprediksi. KV cache adalah variabel yang mengubah model yang "muat" menjadi model yang crash, jadi ada gunanya menjabarkan perhitungan yang sebenarnya.
Berapa Banyak Memori yang Digunakan KV Cache?
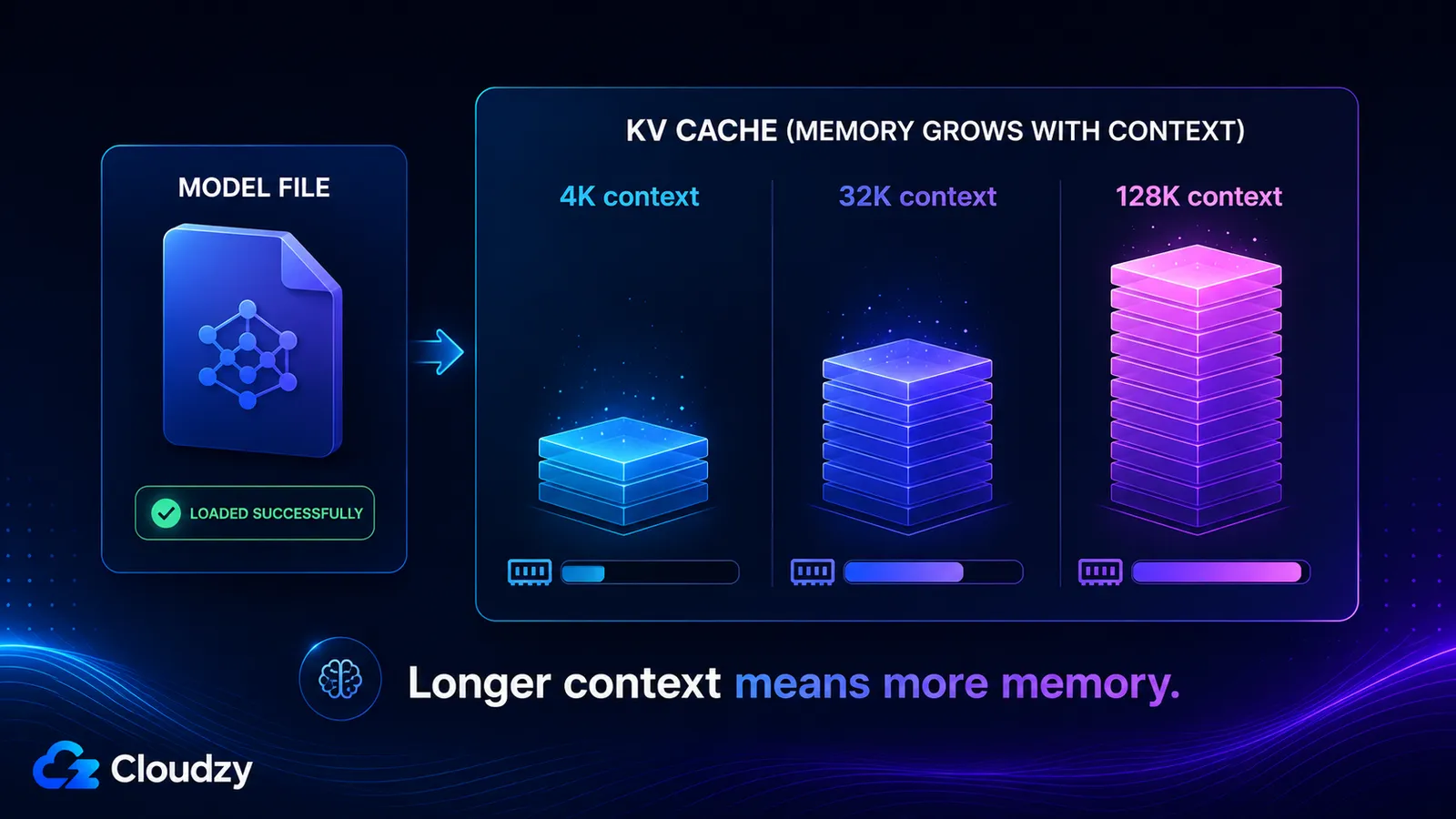
KV cache menyimpan vektor key dan value untuk setiap token di jendela konteks Anda, sehingga tumbuh kurang lebih linear dengan panjang konteks dan sepenuhnya terpisah dari bobot model. Ukurannya ditentukan oleh jumlah layer model, jumlah KV head-nya, dimensi head, panjang konteks, dan presisi cache. Aktifkan konteks panjang dan Anda bisa menambahkan puluhan gigabyte yang tidak pernah diperingatkan oleh model yang dimuat dengan baik-baik saja.
Rumusnya cukup singkat untuk diingat:
KV cache bytes = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
Angka 2 di depan mewakili dua tensor yang disimpan per token, satu untuk key, satu untuk value. bytes_per_element bernilai 2 untuk cache FP16. Sisanya adalah konstanta arsitektur yang bisa Anda baca dari kartu model.
Hitung untuk Llama 3.1 8B, yang memiliki 32 layer, 8 KV head, dan dimensi head 128. Pada konteks 4.096 token, ukuran batch 1, cache FP16:
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
Perbesar konteks dan angkanya ikut membesar, karena setiap suku kecuali context_tokens bersifat tetap:
- Konteks 4K: ~536 MB
- Konteks 32K: ~4,3 GB
- Konteks 128K: ~17 GB
Dua angka terakhir itulah alasan mengapa sebuah model bisa mengklaim jendela konteks 128K, dimuat dengan lancar, lalu kehabisan memori begitu Anda benar-benar menggunakan jendela itu. KV cache pada konteks penuh lebih besar daripada bobot terkuantisasi itu sendiri.
Inilah bagian yang membuat model konteks panjang modern mungkin terjadi sama sekali: Llama 3.1 8B menggunakan Grouped Query Attention (GQA). Model ini punya 32 query head tetapi hanya 8 KV head, cache-nya menyimpan vektor key/value untuk 8 head, bukan 32. Jalankan rumus yang sama dengan 32 KV head (desain Multi-Head Attention yang lebih lama, di mana KV head sama dengan query head) dan setiap angka di atas dikalikan 4. 17 GB pada 128K itu menjadi 68 GB. GQA adalah alasan arsitektural mengapa perhitungannya tetap bisa ditangani seiring bertambah besarnya jendela konteks.
Ukuran file bukan anggaran memori Anda. Ketika bobot atau KV cache tidak lagi muat di jalur memori cepat dan runtime harus jatuh kembali ke RAM sistem lewat PCIe, throughput tidak menurun secara bertahap. Ia jatuh drastis begitu Anda memindahkan data lewat PCIe setiap token. Anggarkan memori sehingga bobot dan KV cache pada panjang konteks nyata Anda sama-sama muat, bukan hanya bobotnya saja.
Bagaimana Cara Memilih Kuantisasi untuk GPU atau Mac Anda?
Mulailah dari perangkat keras dan runtime Anda. Pemilik GPU NVIDIA memiliki menu paling luas dan sebaiknya mempertimbangkan EXL2 untuk kecepatan mentah atau GGUF untuk portabilitas. Jika Anda menggunakan AMD, Apple Silicon, perangkat keras khusus CPU, atau setup campuran, GGUF melalui llama.cpp biasanya titik awal paling aman. Dari situ, pilih level kuantisasi tertinggi yang muat setelah Anda menganggarkan KV cache pada panjang konteks yang benar-benar Anda gunakan, bukan maksimum model.
Satu jebakan Apple Silicon yang perlu diketahui: GPU tidak mendapatkan seluruh unified memory Anda (lihat artikel pendamping kami tentang apa sebenarnya unified memory itu untuk gambaran lengkap tentang cara kerja pool bersama itu). Komunitas self-hosting telah mendokumentasikan batas sekitar 75% dari total unified memory yang tersedia untuk GPU (ini tidak dikonfirmasi secara resmi oleh Apple dan dapat berubah seiring pembaruan macOS). Jadi "Mac 64 GB" secara realistis hanya ~48 GB untuk model ditambah KV cache-nya, rencanakan berdasarkan angka yang lebih kecil itu.
Artikel ini membahas cara membaca format dan memprediksi perilaku runtime-nya: menguraikan nama kuantisasi, memilih format yang didukung perangkat keras Anda, dan menganggarkan KV cache secara terpisah dari bobot. Mencocokkan model tertentu dengan jumlah memori tertentu, tabel pencarian ukuran-ke-memori, adalah pertanyaan terkait namun terpisah yang akan kami bahas dalam artikel pendamping di masa depan.
Membaca Repo
Anda sekarang bisa melihat halaman model dan membacanya, bukan menebak-nebak. Uraikan nama kuantisasi menjadi lebar bit efektifnya, kenali bahwa GGUF adalah format lokal paling luas sementara GPTQ, AWQ, dan EXL2 lebih spesifik terhadap runtime, dan ingat bahwa ukuran file hanyalah batas bawah, KV cache menumpuk di atasnya dan tumbuh seiring konteks Anda. Buka file untuk model yang Anda inginkan, pilih format yang bisa dijalankan perangkat keras Anda, pilih level kuantisasi tertinggi yang muat setelah Anda menyisakan ruang untuk KV cache pada panjang konteks nyata Anda, dan Anda akan terhindar dari crash kehabisan memori yang memicu seluruh pertanyaan ini.
Pertanyaan yang Sering Diajukan
Apa Arti Q4_K_M?
Q4_K_M adalah level kuantisasi GGUF: kira-kira 4 bit per bobot (Q4), menggunakan penskalaan K-quant per blok (K), pada tingkat ukuran/kualitas sedang (M). efektif lebar bitnya sekitar 4,89 bit per bobot, bukan tepat 4, karena K-quant menyimpan skala dan nilai minimum untuk setiap blok bobot. Itulah sebabnya file model 8B "4-bit" berukuran sekitar 4,6 GB, bukan 3,5 GB.
Apakah Kuantisasi Mengurangi Kualitas LLM?
Ya, tetapi biayanya sangat bergantung pada seberapa jauh Anda mendorongnya. Pada Llama-3.1-8B-Instruct yang diukur dalam arXiv:2601.14277, perplexity hanya naik sekitar 0,4% pada Q6_K dan tetap di sekitar 1% sepanjang rentang Q5. Turun ke Q4, kenaikannya masih moderat (beberapa persen); di bawah Q3_K_M kenaikannya melonjak tajam, mencapai +22% pada Q3_K_S. Untuk sebagian besar penggunaan, Q4_K_M ke atas secara efektif lossless; penalti tajam terjadi pada 3 bit ke bawah.
Apa Perbedaan Antara GGUF, GPTQ, AWQ, dan EXL2?
GGUF (dijalankan oleh llama.cpp) adalah format portabel, ia bekerja di CPU, GPU, atau setup hybrid di berbagai perangkat keras. GPTQ, AWQ, dan EXL2 lebih spesifik terhadap GPU dan runtime. Pada 4-bit, keempatnya bisa berada dalam rentang kualitas yang sempit, sehingga perbedaan praktisnya terletak pada perangkat keras, dukungan loader, kecepatan, dan penggunaan VRAM: EXL2 adalah pilihan NVIDIA/CUDA yang fokus pada kecepatan, AWQ umum di serving stack, GPTQ cocok dengan tooling GPU dan repo model yang lebih lama, dan GGUF tetap menjadi opsi lokal paling portabel.
Mengapa LLM Lokal Saya Menggunakan Memori Lebih Banyak daripada File-nya?
Ukuran file hanyalah bobot model. Pada saat runtime Anda juga membayar untuk KV cache (state attention untuk setiap token di jendela konteks), aktivasi, dan overhead framework plus driver. KV cache biasanya menjadi penyebab utama saat selisihnya besar, karena ia tumbuh seiring panjang konteks dan dialokasikan terpisah dari bobot, model yang file-nya hanya beberapa gigabyte bisa membutuhkan memori jauh lebih banyak begitu Anda mengatur konteks panjang.
Bagaimana Panjang Konteks Memengaruhi Penggunaan Memori?
KV cache tumbuh kurang lebih linear seiring panjang konteks, jadi menggandakan konteks Anda kira-kira menggandakan cache-nya. Untuk Llama 3.1 8B, cache-nya sekitar 536 MB pada 4K token, ~4,3 GB pada 32K, dan ~17 GB pada 128K (FP16, single stream). Pertumbuhan itu sepenuhnya terpisah dari bobot model, itulah sebabnya mengklaim jendela konteks panjang dapat mendorong model ke kondisi kehabisan memori meskipun model itu dimuat dengan baik-baik saja.


