
Memilih GPU VPS bisa terasa membingungkan ketika kamu dihadapkan pada lembar spesifikasi yang penuh angka. Jumlah core bervariasi dari 2.560 hingga 21.760, tapi apa artinya itu?
CUDA core adalah unit pemrosesan paralel di dalam GPU NVIDIA yang menjalankan ribuan kalkulasi secara bersamaan, mendukung berbagai kebutuhan mulai dari pelatihan AI hingga rendering 3D. Panduan ini menjelaskan cara kerjanya, perbedaannya dengan core CPU dan Tensor core, serta berapa jumlah core yang sesuai dengan kebutuhanmu tanpa harus bayar lebih.
Apa itu CUDA Cores?

CUDA core adalah unit pemrosesan individual di dalam GPU NVIDIA yang menjalankan instruksi secara paralel. Pada dasarnya, apa itu teknologi CUDA core? Bayangkan unit-unit ini sebagai pekerja kecil yang mengerjakan bagian-bagian dari satu pekerjaan yang sama secara bersamaan.
NVIDIA memperkenalkan CUDA (Compute Unified Device Architecture) pada tahun 2006 untuk memanfaatkan kekuatan GPU bagi komputasi umum di luar grafis. Dokumentasi dokumentasi CUDA resmi menyediakan detail teknis yang lengkap. Setiap unit menjalankan operasi aritmatika dasar pada bilangan floating-point, yang sangat cocok untuk kalkulasi berulang.
GPU NVIDIA modern memadatkan ribuan unit ini ke dalam satu chip. GPU konsumer dari generasi terbaru memiliki lebih dari 21.000 core, sementara GPU pusat data berbasis arsitektur Hopper memiliki hingga 16.896 core. Unit-unit ini bekerja bersama melalui Streaming Multiprocessors (SM).
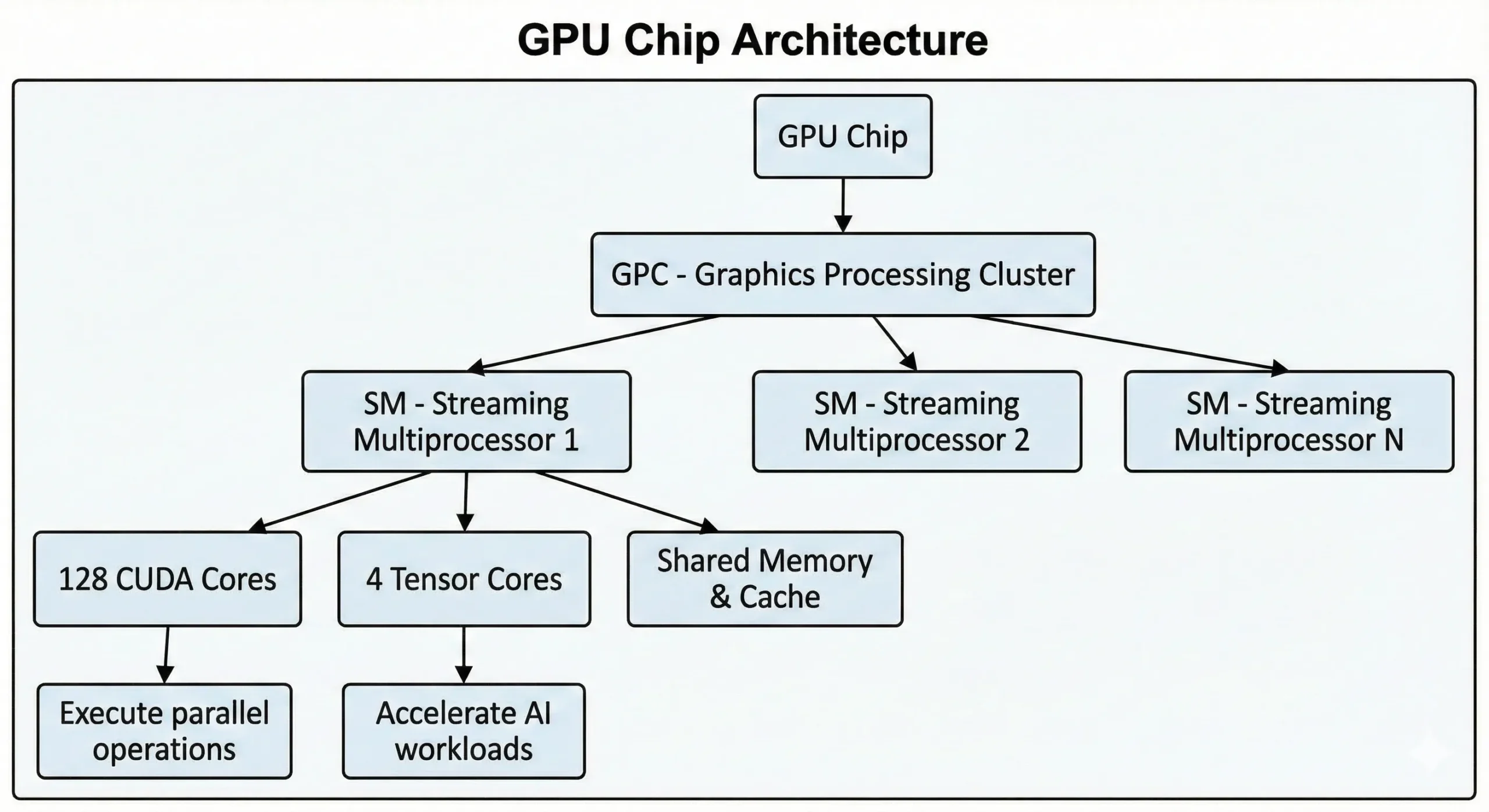
Unit-unit ini menjalankan operasi SIMT (Single Instruction, Multiple Threads) melalui metode komputasi paralel. Satu instruksi dieksekusi pada banyak titik data sekaligus. Saat melatih jaringan neural atau merender scene 3D, ribuan operasi serupa terjadi bersamaan. Pekerjaan tersebut dibagi menjadi aliran bersamaan dan dieksekusi secara simultan, bukan satu per satu.
CUDA Core vs Core CPU: Apa Bedanya?

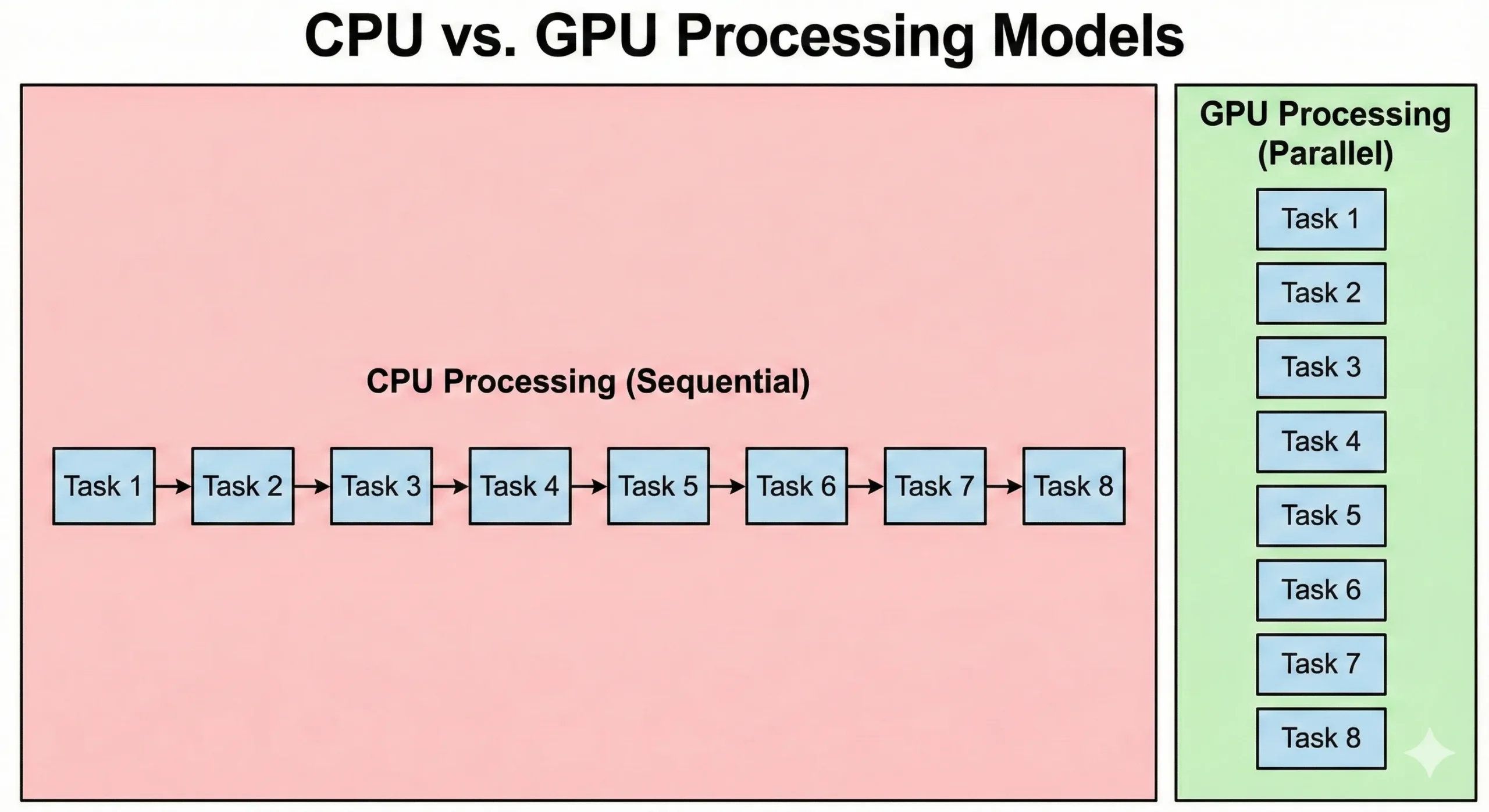
CPU dan GPU menyelesaikan masalah dengan cara yang sangat berbeda. CPU server modern mungkin memiliki 8 hingga 128+ core yang berjalan pada kecepatan clock tinggi. Prosesor ini unggul dalam operasi sekuensial di mana setiap langkah bergantung pada hasil sebelumnya. Mereka menangani logika kompleks dan percabangan dengan efisien.
GPU mengambil pendekatan yang berbeda. Mereka memadatkan ribuan CUDA core yang lebih sederhana dengan kecepatan clock lebih rendah. Unit-unit ini mengimbangi kecepatan yang lebih rendah melalui paralelisme. Ketika 16.000 unit bekerja bersama, total throughput melampaui kemampuan CPU standar.
CPU menjalankan kode sistem operasi dan logika aplikasi yang kompleks. Meskipun GPU mengutamakan throughput, overhead dari inisiasi tugas dan sinkronisasi menghasilkan latensi yang lebih tinggi. Pemrosesan grafis paralel mengutamakan pergerakan data. Meskipun membutuhkan waktu lebih lama untuk memulai, mereka memproses kumpulan data besar lebih cepat daripada CPU.
| Fitur | Inti CPU | Inti CUDA |
| Jumlah per chip | 4-128+ inti | 2.560-21.760 inti |
| Kecepatan Clock | 3.0-5.5 GHz | 1,4-2,5 GHz |
| Gaya pemrosesan | Instruksi berurutan dan kompleks | Instruksi paralel dan sederhana |
| Terbaik untuk | Sistem operasi, tugas single-threaded | Komputasi matriks, pemrosesan data paralel |
| Latensi | Rendah (mikrodetik) | Lebih tinggi (overhead saat peluncuran) |
| Arsitektur | Tujuan umum | Dioptimalkan untuk kalkulasi berulang |
Teknologi Virtual GPU (vGPU) dan Multi-Instance GPU (MIG) menangani pembagian resource dan penjadwalan untuk mendistribusikan prosesor ke banyak pengguna. Konfigurasi ini memungkinkan tim memaksimalkan utilisasi hardware melalui time-sliced sharing atau dedicated hardware instance, tergantung konfigurasi yang digunakan.
Pelatihan neural network melibatkan miliaran perkalian matriks. GPU dengan 10.000 unit tidak langsung menjalankan 10.000 operasi secara bersamaan, melainkan mengelola ribuan thread paralel yang dikelompokkan dalam "warp" untuk memaksimalkan throughput. Paralelisme masif inilah yang membuat unit-unit ini wajib dipahami oleh developer AI.
CUDA Cores vs Tensor Cores: Memahami Perbedaannya

NVIDIA GPU mengandung dua jenis unit khusus yang bekerja bersama: CUDA core standar dan Tensor core. Keduanya bukan teknologi yang bersaing, melainkan menangani bagian beban kerja yang berbeda.
Unit standar adalah prosesor paralel serbaguna yang menangani kalkulasi FP32 dan FP64, operasi bilangan bulat, dan transformasi koordinat. Teknologi inti CUDA ini menjadi fondasi komputasi GPU, menjalankan segalanya mulai dari simulasi fisika hingga preprocessing data tanpa akselerasi khusus.
Tensor core adalah unit khusus yang dirancang eksklusif untuk perkalian matriks dan tugas AI. Diperkenalkan di arsitektur Volta NVIDIA (2017), unit ini unggul dalam komputasi presisi FP16 dan TF32. Generasi terbaru mendukung FP8 untuk inferensi AI yang lebih cepat.
| Fitur | Inti CUDA | Tensor Cores |
| Tujuan | Komputasi paralel umum | Perkalian matriks untuk AI |
| Presisi | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Kecepatan untuk AI | 1x dasar | 2-10x lebih cepat dari CUDA core |
| Kasus penggunaan | Preprocessing data, ML tradisional | Pelatihan/inferensi deep learning |
| Ketersediaan | Semua NVIDIA GPU | RTX seri 20 ke atas, GPU datacenter |
GPU modern menggabungkan keduanya. RTX 5090 memiliki 21.760 unit standar ditambah 680 Tensor core generasi kelima. H100 memadukan 16.896 unit standar dengan 528 Tensor core generasi keempat untuk akselerasi deep learning.
Saat melatih neural network, Tensor core menangani beban berat selama forward pass dan backward pass melalui model. Unit standar mengelola pemuatan data, preprocessing, kalkulasi loss, dan pembaruan optimizer. Kedua jenis ini bekerja bersama, dengan Tensor core mempercepat operasi yang paling intensif secara komputasi.
Untuk algoritma machine learning tradisional seperti random forest atau gradient boosting, unit standar yang mengelola pekerjaan karena algoritma ini tidak menggunakan pola perkalian matriks yang diakselerasi Tensor core. Namun untuk model transformer dan convolutional neural network, Tensor core memberikan percepatan yang signifikan.
Apa Kegunaan CUDA Core?

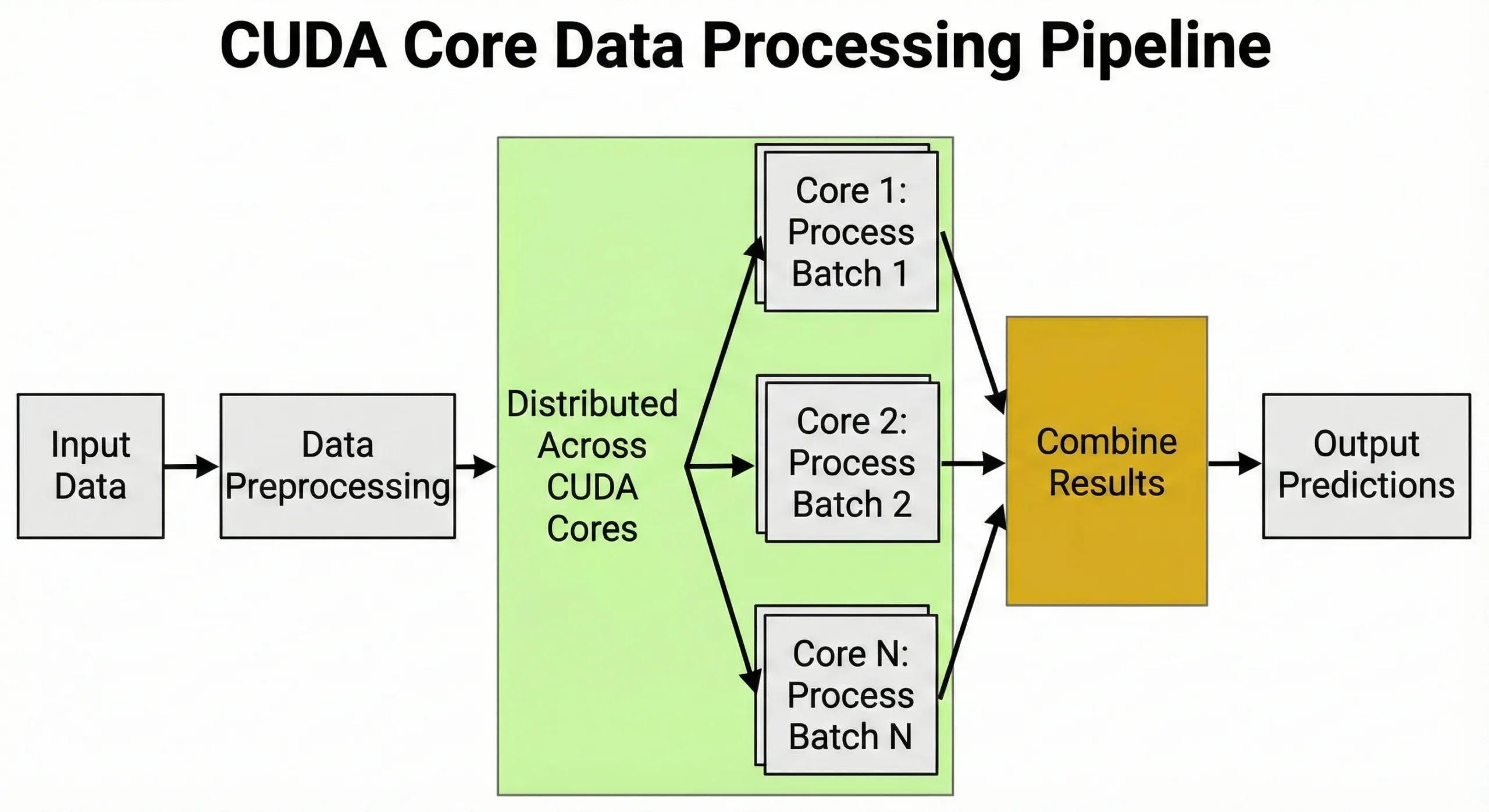
CUDA core dirancang untuk menjalankan banyak komputasi identik secara bersamaan. Setiap pekerjaan yang melibatkan operasi matriks atau komputasi numerik berulang akan mendapat manfaat dari arsitektur ini.
Aplikasi AI dan Machine Learning
Deep learning bergantung pada perkalian matriks selama proses pelatihan dan inferensi. Saat melatih neural network, setiap forward pass membutuhkan jutaan operasi multiply-add pada weight matrix. Backpropagation menambahkan jutaan operasi lagi selama backward pass.
Unit-unit ini menangani praproses data: mengonversi gambar menjadi tensor, menormalisasi nilai, dan menerapkan augmentation transform. Kemampuan menangani ribuan tugas sekaligus inilah yang membuat GPU sangat penting untuk AI.
Selama pelatihan, unit-unit ini mengatur learning rate schedule, komputasi gradient, dan pembaruan status optimizer.
Untuk VPS yang menjalankan operasi inferensi AI seperti sistem rekomendasi atau chatbot, unit-unit ini memproses permintaan secara bersamaan, menjalankan ratusan prediksi sekaligus. Panduan kami tentang GPU terbaik untuk AI 2025 membahas konfigurasi mana yang cocok untuk berbagai ukuran model.
16.896 unit milik H100 yang dikombinasikan dengan Tensor core mampu melatih model berparameter 7 miliar dalam hitungan minggu, bukan bulan. Inferensi real-time untuk chatbot yang melayani ribuan pengguna membutuhkan kemampuan eksekusi paralel yang setara.
Komputasi Ilmiah dan Riset
Para peneliti menggunakan prosesor ini untuk simulasi dinamika molekuler, pemodelan iklim, dan analisis genomik. Setiap komputasi bersifat independen, sehingga sangat cocok untuk eksekusi paralel. Institusi keuangan menjalankan simulasi Monte Carlo dengan jutaan skenario secara bersamaan.
Rendering 3D dan Produksi Video
Ray tracing menghitung pantulan cahaya dalam scene 3D dengan menelusuri ray independen di setiap piksel. RT core menangani traversal, sementara unit standar mengelola texture sampling dan pencahayaan. Pembagian kerja ini menentukan kecepatan rendering scene dengan jutaan ray.
NVENC menangani encoding untuk H.264 dan H.265, sementara arsitektur terbaru (Ada Lovelace dan Hopper) menghadirkan dukungan hardware untuk AV1. CUDA membantu efek, filter, scaling, denoise, transformasi warna, dan pipeline glue. Ini memungkinkan encode engine bekerja berdampingan dengan prosesor paralel untuk produksi video yang lebih cepat.
Rendering 3D di Blender atau Maya mendistribusikan miliaran perhitungan surface shader ke seluruh unit yang tersedia. Sistem partikel pun diuntungkan karena mensimulasikan ribuan partikel yang berinteraksi sekaligus. Fitur-fitur ini menjadi kunci dalam kreasi digital kelas atas.
Pengaruh CUDA Core terhadap Performa GPU

Jumlah core memberi gambaran kasar soal kemampuan eksekusi paralel, tetapi menilai CUDA core tidak cukup hanya dari angka. Clock speed, bandwidth memori, efisiensi arsitektur, dan optimasi software semuanya berperan besar.
GPU dengan 10.000 unit yang berjalan di 2,0 GHz menghasilkan performa berbeda dibanding yang sama-sama 10.000 unit tetapi di 1,5 GHz. Clock speed yang lebih tinggi berarti setiap unit menyelesaikan lebih banyak komputasi per detik. Arsitektur terbaru memaksimalkan pekerjaan di setiap siklus melalui instruction scheduling yang lebih baik.
Periksa apakah perangkat Anda tetap sibuk, tetapi ingat bahwa nvidia-smi utilization adalah metrik yang kasar. Metrik ini mengukur persentase waktu sebuah kernel aktif, bukan berapa banyak core yang sedang bekerja.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderContoh output: 85%, 92% (85% waktu aktif, 92% aktivitas memory controller)
Jika GPU Anda menunjukkan utilisasi 60-70%, kemungkinan ada bottleneck di hulu seperti pemuatan data CPU atau ukuran batch yang terlalu kecil. Namun, bahkan utilisasi 100% pun bisa menyesatkan jika kernel Anda terbatas oleh memori atau berjalan single-threaded. Untuk gambaran saturasi core yang sesungguhnya, gunakan profiler seperti Nsight Systems untuk melacak metrik "SM Efficiency" atau "SM Active".
Bandwidth memori sering menjadi bottleneck sebelum komputasi mencapai kapasitas penuh. Jika GPU Anda memproses data lebih cepat dari yang bisa disuplai memori, unit-unit tersebut akan menganggur. Model H100 SXM5 menggunakan bandwidth memori sebesar 3,35 TB/s untuk melayani 16.896 core-nya. Versi PCIe, sebaliknya, hanya mendapat 2 TB/s.
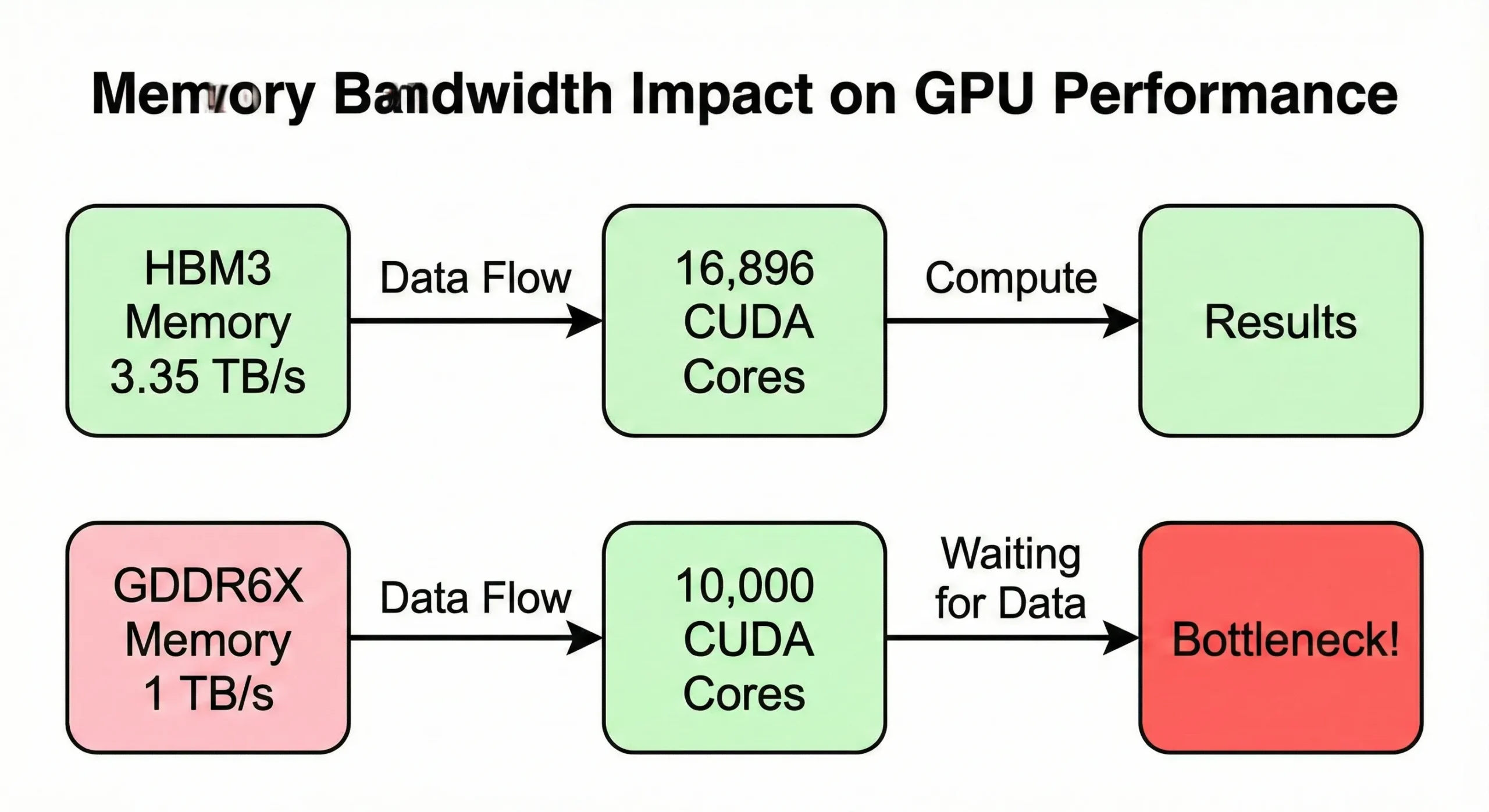
GPU konsumer dengan jumlah core serupa tetapi bandwidth lebih rendah (sekitar 1 TB/s) menunjukkan kecepatan nyata yang lebih lambat pada operasi yang intensif terhadap memori.
Kapasitas VRAM menentukan seberapa besar tugas yang bisa ditangani. Baik itu bobot FP16 untuk sebuah Model 70B, pelatihan penuh membutuhkan lebih banyak memori. Anda harus memperhitungkan gradien dan status optimizer. Status-status ini sering kali melipattigakan jejak memori kecuali Anda menggunakan strategi offload.
A100 80GB ditargetkan untuk inferensi throughput tinggi dan fine-tuning. Sementara itu, RTX 4090 24GB, yang sering disebut untuk model 7B, secara mengejutkan bisa menjalankan model dengan 30B+ parameter jika Anda menggunakan teknik kuantisasi modern seperti INT4. Namun, kehabisan VRAM memaksa transfer data CPU-GPU yang merusak throughput.
Optimasi perangkat lunak menentukan apakah kode Anda benar-benar memanfaatkan semua unit tersebut. Kernel yang ditulis dengan buruk mungkin hanya menggunakan sebagian kecil dari sumber daya yang tersedia. Library seperti cuDNN untuk deep learning dan RAPIDS untuk data science sudah disempurnakan secara intensif untuk memaksimalkan utilisasi.
Lebih Banyak CUDA Core Tidak Selalu Berarti Performa Lebih Baik

Membeli GPU dengan jumlah core tertinggi terlihat logis, tetapi Anda membuang uang jika unit-unit tersebut jauh melampaui komponen sistem lainnya atau tugas Anda tidak bertambah cepat seiring bertambahnya jumlah core.
Bandwidth memori menciptakan batasan pertama. 21.760 unit milik RTX 5090 dilayani oleh bandwidth memori sebesar 1.792 GB/s. GPU lama dengan lebih sedikit unit mungkin memiliki bandwidth per unit yang secara proporsional lebih tinggi.
Perbedaan arsitektur turut berperan. GPU terbaru dengan 14.000 unit di 2,2 GHz mengungguli GPU lama dengan 16.000 unit di 1,8 GHz berkat instruksi per clock yang lebih baik. Kode Anda membutuhkan paralelisasi yang tepat untuk memanfaatkan 20.000 unit secara efektif.
Mengapa CUDA Core Penting Saat Memilih GPU VPS

Memilih konfigurasi CUDA core GPU yang tepat untuk VPS Anda mencegah pemborosan biaya pada sumber daya yang tidak terpakai maupun bottleneck di tengah proyek.
Memori 80GB milik H100 mampu menangani inferensi untuk model 70B parameter menggunakan kuantisasi 4-bit. Namun untuk pelatihan penuh, bahkan 80GB pun sering tidak cukup untuk model 34B setelah memperhitungkan gradien dan status optimizer. Dalam pelatihan FP16, jejak memori bertambah signifikan, sering kali memerlukan sharding multi-GPU.
Operasi inferensi untuk prediksi real-time membutuhkan lebih sedikit unit tetapi diuntungkan oleh latensi rendah. Pekerjaan pengembangan dan prototyping berjalan baik dengan GPU kelas menengah untuk menguji algoritma dan men-debug kode.
RTX 4060 Ti dengan 4.352 unit memungkinkan Anda melakukan pengujian tanpa membayar untuk hardware berlebihan. Setelah pendekatan Anda tervalidasi, tingkatkan ke GPU produksi untuk sesi pelatihan penuh.
Rendering dan pekerjaan video bertambah cepat seiring bertambahnya unit hingga titik tertentu. Renderer Cycles milik Blender memanfaatkan semua sumber daya yang tersedia secara efisien. GPU dengan 8.000-10.000 unit merender scene 2-3x lebih cepat dibandingkan yang memiliki 4.000 unit.
Di Cloudzy, kami menyediakan GPU VPS hosting berperforma tinggi yang dirancang untuk beban kerja berat. Pilih RTX 5090 atau RTX 4090 untuk rendering cepat dan inferensi AI yang hemat biaya, atau tingkatkan ke A100 untuk workload deep learning skala besar. Semua paket berjalan di jaringan 40 Gbps dengan kebijakan yang mengutamakan privasi dan opsi pembayaran menggunakan cryptocurrency, memberikan Anda daya komputasi penuh tanpa birokrasi enterprise.
Baik itu melatih model AI, merender scene 3D, atau menjalankan simulasi ilmiah, Anda memilih jumlah core yang sesuai dengan kebutuhan.
Pertimbangan anggaran penting untuk diperhatikan. A100 dengan 6.912 unit harganya jauh lebih murah dari H100 dengan 16.896 unit. Untuk banyak operasi, dua A100 memberikan rasio harga-terhadap-kecepatan yang lebih baik dibandingkan satu H100. Titik impasnya bergantung pada apakah kode Anda dapat berjalan secara terdistribusi di beberapa GPU.
Cara Memilih Jumlah CUDA Core yang Tepat
Sesuaikan kebutuhan Anda dengan karakteristik beban kerja nyata, bukan sekadar mengejar angka tertinggi yang tersedia di pasaran.
Mulai dengan memprofilkan pekerjaan Anda saat ini. Jika Anda melatih model di hardware lokal atau instance cloud, periksa metrik utilisasi GPU. Jika GPU Anda saat ini menunjukkan utilisasi 60-70% secara konsisten, Anda belum memaksimalkan penggunaannya.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Benchmark sederhana ini menunjukkan apakah core GPU Anda menghasilkan throughput yang diharapkan. Bandingkan hasilnya dengan benchmark yang dipublikasikan untuk model GPU Anda.
Upgrade tidak akan membantu. Anda perlu mengatasi bottleneck seperti memori, bandwidth, atau stall CPU terlebih dahulu. Selanjutnya, estimasi kebutuhan memori dengan menghitung ukuran model dalam byte ditambah memori aktivasi.
Tambahkan batch size dikali output layer dan sertakan optimizer states. Total ini harus muat di VRAM. Setelah mengetahui kebutuhan memori, periksa GPU mana yang memenuhi ambang batas tersebut.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Pertimbangkan target waktu Anda. Jika butuh hasil dalam hitungan jam, bayar untuk lebih banyak unit. Proses training yang bisa memakan waktu berhari-hari tetap berjalan baik di GPU yang lebih kecil dengan waktu penyelesaian yang lebih panjang secara proporsional.
Biaya per jam dikali jam yang dibutuhkan menghasilkan total biaya, yang terkadang membuat GPU yang lebih lambat justru lebih hemat secara keseluruhan. Uji efisiensi penskalaan menggunakan berbagai framework yang menyediakan alat benchmarking untuk menunjukkan perubahan throughput.
Jika menggandakan unit hanya memberikan percepatan 1,5x, unit tambahan tersebut tidak sebanding biayanya. Cari titik optimal di mana rasio harga terhadap kecepatan mencapai puncaknya.
| Jenis Beban Kerja | Inti yang Direkomendasikan | GPU Contoh | Catatan |
| Pengembangan & debugging model | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Iterasi cepat, biaya lebih rendah |
| Pelatihan AI skala kecil (<7B parameter) | 6,000-10,000 | RTX 4090, L40S | Cocok untuk konsumen dan perusahaan kecil |
| Pelatihan AI skala besar (7B-70B parameter) | 14,000+ | A100, H100 | Membutuhkan GPU data center |
| Inferensi real-time (throughput tinggi) | 10,000-16,000 | RTX 5080, L40 | Seimbangkan biaya dan performa |
| Rendering 3D & encoding video | 8,000-12,000 | RTX 4080, RTX 4090 | Berkembang sesuai kompleksitas |
| Komputasi ilmiah & HPC | 10,000+ | A100, H100 | Memerlukan dukungan FP64 |
GPU VPS Populer dan Jumlah CUDA Core-nya

Tingkatan GPU yang berbeda melayani segmen pengguna yang berbeda. Apa itu GPUaaS? Ini adalah GPU-as-a-Service, di mana penyedia seperti Cloudzy menawarkan akses on-demand ke NVIDIA GPU yang andal tanpa mengharuskan Anda membeli dan mengelola hardware fisik sendiri.
| Model GPU | Inti CUDA | VRAM | Bandwidth Memori | Arsitektur | Cocok Untuk |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1.792 GB/s | Blackwell | Workstation unggulan, rendering 8K |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/s | Ada Lovelace | AI kelas atas, rendering 4K |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3.350 GB/s | Hopper | Pelatihan AI skala besar |
| H100 PCIe | 14,592 | 80GB HBM2e | 2.000 GB/d | Hopper | AI korporat, pusat data hemat biaya |
| A100 | 6,912 | 40/80GB HBM2e | 1.555–2.039 GB/s | Ampere | AI kelas menengah, keandalan teruji |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Gaming, AI kelas menengah |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Pusat data multi-beban kerja |
Kartu RTX konsumer (4070, 4080, 4090, 5080, 5090) ditujukan untuk kreator dan gaming, tapi juga bekerja baik untuk pengembangan AI. Kecepatannya per-GPU terbilang kencang dengan harga lebih terjangkau dibanding kartu datacenter.
Penyedia VPS sering menyediakan kartu ini untuk pengguna yang sensitif terhadap biaya. Kartu datacenter (A100, H100, L40) mengutamakan keandalan, memori ECC, dan skalabilitas multi-GPU. Kartu ini dirancang untuk operasi 24/7 dan mendukung fitur-fitur lanjutan.
Multi-Instance GPU (MIG) memungkinkan satu GPU dibagi menjadi beberapa instans yang terisolasi. A100 tetap populer meski ada opsi yang lebih baru, berkat spesifikasinya yang seimbang.
Perpaduan antara NVIDIA cores, memori, dan harganya menjadikannya pilihan aman untuk sebagian besar operasi AI di lingkungan produksi. H100 menawarkan 2,4x lebih banyak unit, tapi dengan harga yang jauh lebih tinggi.
Kesimpulan
Unit pemrosesan paralel adalah fondasi dari AI modern, rendering, dan komputasi ilmiah. Memahami cara kerjanya, serta interaksinya dengan memori, kecepatan clock, dan perangkat lunak, membantu Anda memilih konfigurasi GPU VPS yang tepat.
Unit yang lebih banyak membantu jika pekerjaan Anda dapat diparalelkan secara efektif dan komponen seperti bandwidth memori mampu mengimbanginya. Tapi mengejar jumlah core tertinggi tanpa pertimbangan hanya membuang uang jika bottleneck Anda ada di tempat lain.
Mulailah dengan memprofilkan operasi Anda yang sebenarnya, identifikasi di mana waktu paling banyak terpakai, lalu cocokkan spesifikasi GPU dengan kebutuhan tersebut tanpa membeli kapasitas berlebih.
Untuk sebagian besar pekerjaan pengembangan AI, 6.000-10.000 unit memberikan titik optimal antara biaya dan kemampuan. Operasi produksi yang melatih model besar atau menjalankan inferensi throughput tinggi akan diuntungkan oleh GPU dengan 14.000+ unit seperti H100.
Rendering dan pekerjaan video diskalakan secara efisien hingga sekitar 16.000 unit, setelah itu bandwidth memori menjadi faktor pembatasnya.


