ซอฟต์แวร์ตรวจสอบ GPU คือสิ่งที่สามารถเปลี่ยน "GPU ของฉันดูเหมือนจะมีปัญหา" ให้เป็นคำอธิบายที่ชัดเจนและตรงไปตรงมา เช่น "จุดร้อนสูงขึ้น นาฬิกาลดลง และ VRAM เต็มแล้ว"
ในคู่มือนี้ ผมจะพาคุณไปรู้จักกับเครื่องมือที่ใช้สำหรับงาน AI, การแสดงผลซ้อนทับในเกม และการทำงานบน workstation ต่อเนื่องยาวนาน พร้อมอธิบาย metrics ของ GPU ที่ช่วยวินิจฉัยปัญหาความช้า, อาการกระตุก และการแครช
เมื่ออ่านจบ คุณจะได้ระบบ monitoring ของ GPU ที่ปรับให้เข้ากับการทำงานของคุณโดยเฉพาะ พร้อม stack พร้อมใช้สำหรับ 4 use case ทั่วไป ที่คัดลอกไปใช้ได้เลย ไม่ต้องไปค้นหาบทความเพิ่มอีก
คำตอบสั้น ๆ: ซอฟต์แวร์มอนิเตอร์ริ่ง GPU ที่เหมาะกับแต่ละการใช้งาน
ถ้าอยากได้รายการสั้น ๆ ที่ตรงกับการทำงานจริง เริ่มจากตรงนี้ได้เลย ในทางปฏิบัติ ชุดซอฟต์แวร์มอนิเตอร์ GPU ที่ดีที่สุดมักเป็นการผสมกัน: ตัวหนึ่งสำหรับตรวจสอบเร็ว ๆ ตัวหนึ่งสำหรับ overlay หรือ log และอีกตัวสำหรับประวัติหรือการแจ้งเตือน
นี่คือภาพรวมแบบย่อ:
| กรณีการใช้งาน | สแต็กเริ่มต้นที่ดีที่สุด | สิ่งที่คุณได้รับ |
| งาน AI training, inference และ HPC | nvidia-smi (NVIDIA) หรือ AMD SMI (AMD) + การบันทึก/exporter | ตรวจสอบได้รวดเร็ว บันทึก log แบบ script ได้ แจ้งเตือนได้ง่าย |
| เกมบน Windows | MSI Afterburner + RTSS + เครื่องมือจับข้อมูล frametime | Overlay พร้อมหลักฐานเปรียบเทียบอาการกระตุกกับ FPS ต่ำ |
| การเล่นเกมบน Linux | MangoHud + โปรแกรมตรวจสอบผ่าน terminal («nvtop) | overlay ขนาดเบาพร้อมการตรวจสอบความถูกต้องแบบรายกระบวนการ |
| เวิร์กสเตชันสำหรับงาน 3D / วิดีโอ / CAD | การล็อกข้อมูลด้วย HWiNFO และการทดสอบความเครียดเบื้องต้น | บันทึกยาวที่แชร์ได้ พร้อมขั้นตอนการทดสอบซ้ำที่ทำซ้ำได้ |
| เครื่องที่ใช้ทรัพยากรร่วมกัน GPU | nvtop (Linux) + ผู้ส่งออก/แdashboard | การมองเห็นการใช้งาน VRAM แบบรายกระบวนการ |
จากนี้ งานหลักคือการเลือก GPU monitoring software ให้เข้ากับวิธีที่คุณดูข้อมูล ไม่ว่าจะเป็นบนหน้าจอ ใน log หรือใน dashboard
คู่มือนี้เหมาะกับใคร
ผมจะเขียนในแบบที่คนเคย debug เครื่องจริงเขียน เพราะจากประสบการณ์ ผู้อ่านแต่ละคนต้องการ GPU tools ที่ต่างกัน แม้จะมองที่ GPU ตัวเดียวกัน
นี่คือสี่กลุ่มผู้ใช้ที่ผมพูดถึง:
- ตัวสร้างโมเดล (AI/ML): สนใจเรื่อง VRAM headroom, sustained clocks, การ throttle และ "งานรันข้ามคืนโดยไม่มีปัญหาหรือเปล่า?"
- ผู้เล่นเกมแบบแข่งขัน/พูดคุยสดแบบแข่งขัน: สนใจเรื่อง frametime, ความเสถียรของ overlay และการสังเกตการถดถอยหลังอัปเดต driver
- ผู้ใช้สถานีงาน (3D/video/CAD): สนใจเรื่อง log, crash ที่ reproduce ได้ และการหาสาเหตุว่าเกิดจากความร้อน ไฟฟ้า หรือ driver
- ผู้ดูแลระบบที่จัดการเครื่อง GPU: สนใจเรื่อง alert, กราฟแนวโน้ม, การวางแผน capacity และการจับปัญหาตั้งแต่เนิ่น ๆ
เมื่อรู้แล้วว่าตัวเองอยู่กลุ่มไหน การเลือก GPU monitoring software ที่เหมาะสมก็ไม่ใช่เรื่องยาก
วิธีเลือก GPU Monitoring Software
แอปตรวจสอบประสิทธิภาพหลายตัวดูเหมือนกันจนกว่าจะได้ใช้จริงสักหนึ่งสัปดาห์ ความแตกต่างหลักมักอยู่ที่ output และความเชื่อถือได้ ไม่ใช่ฟีเจอร์สวยหรูที่แต่ละตัวพยายามโฆษณา
นี่คือสามคำถามที่ช่วยให้คุณเลือก GPU monitoring software ได้รวดเร็วขึ้น:
- คุณต้องการ overlay, log หรือทั้งสองอย่าง?
นักเล่นเกมต้องการ overlay งาน AI และ workstation มักต้องการ log ส่วน admin ต้องการทั้ง log และ alert - คุณต้องการมองเห็นการใช้งานแบบรายกระบวนการหรือเปล่า?
ถ้าคุณใช้เครื่องร่วมกัน ไม่ว่าจะเป็น lab, studio หรือ remote server การมองเห็น VRAM แบบรายกระบวนการมักเป็นสิ่งแรกที่ต้องการ - คุณต้องการประวัติข้อมูลและ alert หรือเปล่า?
ถ้างานรันข้ามคืน การ "ค่อยดูทีหลัง" ไม่เพียงพอ คุณต้องการกราฟและ alert
เพื่อให้ใช้งานได้จริง ส่วนที่เหลือของคู่มือจัดเรียงตาม GPU metrics ก่อน แล้วตามด้วย tool stack ที่เหมาะกับแต่ละกรณีใช้งาน
GPU Metrics ที่ควรให้ความสำคัญ
Good GPU monitoring software ให้ตัวเลขมาเยอะแยะ ส่วน GPU monitoring software ที่มีประโยชน์จริงๆ จะให้แค่ตัวเลขสำคัญที่อธิบายพฤติกรรมของระบบได้ ผมจัดกลุ่ม GPU metrics ตามการตัดสินใจที่แต่ละตัวช่วยให้คุณทำได้
Metrics อุณหภูมิและการ Throttle
นี่คือ GPU metrics ที่อธิบายว่าทำไม "ทำงานเร็วดีอยู่ 10 นาที แล้วก็ช้าลงเฉยเลย":
- อุณหภูมิ GPU
- อุณหภูมิ Hotspot (มักเป็นตัวแรกที่พุ่งขึ้น)
- อุณหภูมิ Memory/Junction (สำคัญมากในงาน AI ที่รันนานและงาน Render ที่ใช้เวลาหลายชั่วโมง)
- ความเร็วของพัดลม (ช่วยจับได้ว่า Laptop Profile หรือ Fan Curve มีปัญหา)
ถ้าต้องการปรับปรุงเสถียรภาพของระบบ ให้บันทึก metrics พวกนี้ไว้ เพราะการดู Snapshot ครั้งเดียวแทบไม่เพียงพอ
Power, Clocks, และ Limits
GPU metrics ชุดนี้อธิบายสาเหตุที่ระบบ Downclock และ Performance ไม่สม่ำเสมอ:
- Board Power Draw
- Core Clock และ Memory Clock
- Power Limit/Performance State (ถ้า Tool ที่ใช้แสดงค่านี้)
ในการ Debug จริงๆ หลายครั้ง ข้อมูลด้าน Power และ Clocks ให้ภาพที่ชัดเจนกว่า "GPU usage %" พื้นฐานมาก
VRAM และ Memory Pressure
GPU metrics ชุดนี้อธิบายอาการกระตุก, OOM errors, และอาการช้าแบบ "สุ่ม" ที่เกิดขึ้นบ่อยๆ:
- VRAM ที่ใช้อยู่ vs ทั้งหมด
- Memory Controller Activity (ช่วยตรวจจับ Bandwidth Limits)
- System RAM Pressure (เพราะ VRAM Spill ดึงประสิทธิภาพของระบบโดยรวมลงได้เช่นกัน)
สำหรับงาน AI, VRAM มักเป็นเพดานที่แข็งที่สุด สำหรับเกม, VRAM pressure มักแสดงออกมาเป็น Frametime Spike ก่อนเป็นอันดับแรก
Frametime และ Frame Pacing Metrics
สำหรับการเล่นเกมและ Streaming, FPS อย่างเดียวอาจทำให้เข้าใจผิดได้ Frametime ต่างหากที่เป็น metric ที่ต้องดู เพราะมันวัดความลื่นไหลของภาพโดยตรง:
- เวลาเฟรม (ms)
- 1% ต่ำ / 0.1% ต่ำ (เหมาะสำหรับการเปรียบเทียบ)
- GPU ยุ่ง vs CPU ยุ่ง (ช่วยแยกแยะว่าคอขวดเกิดจาก GPU หรือ CPU)
นี่คือเหตุผลที่แอปติดตามประสิทธิภาพสำหรับเกมมักมีการเก็บข้อมูล frametime ด้วย เมื่อเข้าใจพื้นฐานของ metric เหล่านี้แล้ว เราสามารถพูดถึงชุดซอฟต์แวร์ตรวจสอบ GPU ที่เหมาะสมสำหรับแต่ละ workflow ได้
ซอฟต์แวร์ตรวจสอบ GPU สำหรับ AI, Training และ Server

การตรวจสอบ AI ตั้งค่าได้ไม่ยาก ตรวจสอบเร็วผ่าน terminal พร้อม log และการแจ้งเตือนสำหรับงานที่รันนาน ซอฟต์แวร์ตรวจสอบ GPU ที่ใช้งานผ่าน CLI ได้และ export metric ออกมาได้คือสิ่งที่คุณต้องการ
NVIDIA: nvidia-smi สำหรับการตรวจสอบด่วนและ log แบบ script ได้
ใน NVIDIA systems, nvidia-smi มักเป็นคำสั่งแรกที่คนรัน เพราะมาพร้อมกับ driver และออกแบบมาสำหรับการตรวจสอบและจัดการผ่าน NVML
เอกสารอย่างเป็นทางการอยู่ที่นี่: อินเทอร์เฟซการจัดการระบบ NVIDIA (nvidia-smi).
ถ้าต้องการแนวทางแบบง่าย ๆ คือ "บันทึกไว้แล้วดูทีหลัง" (ซึ่งคุณอาจแปลกใจว่ามันแก้ปัญหาได้บ่อยแค่ไหน) รูปแบบนี้ใช้ได้ผลดีมาก:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
นี่คือพฤติกรรมพื้นฐานของซอฟต์แวร์ตรวจสอบ GPU พร้อม timestamp, metric หลักของ GPU และ output ที่ใช้งานร่วมกับ script ได้ดี
AMD: AMD SMI สำหรับ ROCm และ HPC Node
บน AMD Linux compute node, AMD SMI คือ interface หลักสำหรับการตรวจสอบและจัดการในยุคปัจจุบัน โดย AMD ระบุว่าเป็นชุดเครื่องมือแบบรวมศูนย์สำหรับการตรวจสอบและควบคุมในบริบท HPC
เอกสารอย่างเป็นทางการอยู่ที่นี่: AMD SMI เอกสารประกอบ.
หากสภาพแวดล้อมของคุณใช้ AMD เป็นหลัก AMD SMI คือรากฐานของซอฟต์แวร์ตรวจสอบ GPU ที่เครื่องมืออื่น ๆ มักสร้างต่อยอดขึ้นมา
การมองเห็นระดับ process: nvtop สำหรับ GPU ที่ใช้ร่วมกัน
ถ้าเคยเจอสถานการณ์บนเครื่องที่ใช้ร่วมกันแล้ว VRAM เต็ม "อย่างลึกลับ" การมองเห็นระดับ process ช่วยประหยัดเวลาได้มาก บน Linux, nvtop เป็นที่นิยมด้วยเหตุผลนี้ เพราะทำให้เห็นชัดว่า "ใครกำลังใช้ VRAM อยู่?" สำหรับ AMD/Intel อาจต้องใช้ kernel เวอร์ชันใหม่เพื่อดูสถิติระดับ process
ในทีมที่ใช้งานหลากหลาย ผมมักเห็นคนรัน nvtop คู่กันกับ nvidia-smi หรือ AMD SMI นี่เป็นการจับคู่ที่เรียบง่ายและลดการเดาสุ่มได้มาก แนะนำให้ลองใช้ดู
อย่ามองข้ามเรื่องการเลือกฮาร์ดแวร์!
การมอนิเตอร์ไม่ได้แก้ปัญหาเพดาน VRAM แค่ทำให้มองเห็นเพดานนั้นชัดขึ้นเท่านั้น ถ้าคุณยังแมปเวิร์กโหลดกับระดับ GPU อยู่ คู่มือของเราเกี่ยวกับ GPU ที่ดีที่สุดสำหรับ Machine Learning ในปี 2025 จะช่วยได้มาก เพราะอธิบาย VRAM และแบนด์วิดธ์ในแบบเดียวกับที่คุณจะอ่านในล็อกและแดชบอร์ดในภายหลัง
เมื่อจัดการซอฟต์แวร์มอนิเตอร์ GPU แบบเซิร์ฟเวอร์ได้แล้ว ขั้นตอนต่อไปคือโอเวอร์เลย์และเฟรมไทม์ เนื่องจาก เวิร์กโหลดแบบโต้ตอบมีพฤติกรรมต่างออกไป.
ซอฟต์แวร์มอนิเตอร์ GPU สำหรับเกมและสตรีมมิง

เกมคือพื้นที่ที่คนมีความเห็นเกี่ยวกับเครื่องมือ GPU แตกต่างกันมากที่สุด ส่วนใหญ่เพราะโอเวอร์เลย์มักพังในเวลาที่แย่ที่สุด สำหรับเกม คุณต้องการโอเวอร์เลย์ที่เรียบง่ายและการจับภาพเฟรมไทม์ที่ทำซ้ำได้
MSI Afterburner + RTSS สำหรับโอเวอร์เลย์บน Windows
คู่นี้ได้รับความนิยมมากเพราะคุณสร้างโอเวอร์เลย์ที่เรียบร้อยได้ โดยแสดงเฉพาะเมตริก GPU ที่ต้องการ เช่น การใช้งาน, ความเร็วสัญญาณนาฬิกา, VRAM, อุณหภูมิ, เฟรมไทม์ และอาจรวมถึงความเร็วพัดลม
คำเตือนสำคัญที่พบบ่อยในชุมชนคือเว็บไซต์ดาวน์โหลดปลอม หน้าเพจ Afterburner ของ MSI เองระบุชัดว่าการดาวน์โหลดที่ถูกต้องควรมาจาก msi.com และ Guru3Dและยังแสดงรุ่นที่วางจำหน่ายปัจจุบัน (4.6.6 รุ่นสมบูรณ์ เผยแพร่เดือนตุลาคม 2025)
ปัญหาโอเวอร์เลย์เป็นอีกเรื่องที่ต้องระวัง ตัวอย่างเช่น RTSS ทำงานได้ในบางเกมแต่ใช้งานไม่ได้ในบางเกม โดยเฉพาะเกมที่ใช้เรนเดอร์พาธใหม่ มีรายงานว่าโอเวอร์เลย์ แสดงผลใน Vulkan แต่ไม่แสดงใน DX12 สำหรับเกมเดียวกัน หรือหายไปหลังอัปเดต
แต่นั่นไม่ใช่ความผิดพลาดของคุณ เป็นเพียงสิ่งที่เกิดขึ้นเมื่อโอเวอร์เลย์ต้องผูกเข้ากับสแต็กของเกมและไดรเวอร์ที่เปลี่ยนอยู่เสมอ
ถ้าต้องการโอเวอร์เลย์พื้นฐานที่เสถียร ให้แสดงน้อยๆ ก็พอ :
- เวลาเฟรม
- การใช้งาน GPU
- VRAM ที่ใช้งาน
- อุณหภูมิ GPU
เพิ่ม power และ clocks เฉพาะเมื่อกำลัง debug throttling อย่างจริงจัง
การจับภาพเฟรมไทม์สำหรับปัญหา "Stutter"
นี่คือจุดที่แอปมอนิเตอร์ประสิทธิภาพที่จับกราฟเฟรมไทม์ได้มีประโยชน์มาก FPS เฉลี่ยอาจดูปกติในขณะที่ความรู้สึกของ frame pacing แย่มาก กราฟเฟรมไทม์ช่วยคลายความสับสนนั้นได้เร็ว
เวิร์กโฟลว์เบนช์มาร์กเกมส่วนใหญ่ใช้ PresentMon เป็นพื้นฐาน และ NVIDIA เอกสาร ที่การวิเคราะห์ FrameView ใช้ PresentMon สำหรับการจับข้อมูล frame rate และ frame time
คุณไม่จำเป็นต้องเบนช์มาร์กทุกเกม การจับเฟรมไทม์มีประโยชน์สูงสุดสำหรับการเปรียบเทียบ เช่น ก่อนและหลังอัปเดตไดรเวอร์, ก่อนและหลังเปลี่ยนตัวจำกัด, ก่อนและหลังปรับค่าต่างๆ เป็นต้น
MangoHud สำหรับโอเวอร์เลย์บน Linux
บน Linux มีการแนะนำ MangoHud บ่อยมากเพราะทำงานเบาและผสานกับการตั้งค่า Steam/Proton ได้ดี คำร้องเรียนที่พบบ่อยที่สุดเกี่ยวกับเซนเซอร์ที่หายไปหรือค่าแปลกๆ บนแล็ปท็อปที่ใช้กราฟิกแบบ hybrid
ในทางปฏิบัติ คุณสามารถจับคู่ MangoHud กับเครื่องมือตรวจสอบแบบ terminal อย่าง nvtop. นี่ยังเป็นตัวอย่างที่ดีของวิธีที่ซอฟต์แวร์ GPU ทำงานได้ดีกว่าอย่างเห็นได้ชัด เมื่อรันเป็น stack ขนาดเล็ก แทนที่จะเป็นแอปขนาดใหญ่ตัวเดียว
จากการใช้งานด้านเกมมิ่ง ขั้นต่อไปที่สมเหตุสมผลคือการมอนิเตอร์แบบ workstation เพราะในบริบทนั้น การเก็บ log และการแก้ปัญหาที่ตรวจสอบซ้ำได้คือสิ่งที่สำคัญที่สุด
โฮสต์เซิร์ฟเวอร์เกมไร้แล็กด้วยโฮสติ้ง VPS NVMe ความเร็วสูง
VPS สำหรับเล่นเกม
ซอฟต์แวร์ตรวจสอบ GPU สำหรับเวิร์กสเตชันและแอปพลิเคชันระดับมืออาชีพ
การมอนิเตอร์เวิร์กสเตชันไม่ใช่งานแบบเจ้าหน้าที่รักษาความปลอดภัยที่จ้องจอตลอดเวลา แต่เป็นเรื่องของการตอบคำถามว่า "เกิดอะไรขึ้นในช่วงเวลาที่ผ่านมา และเราสามารถย้อนดูซ้ำได้ไหม?"
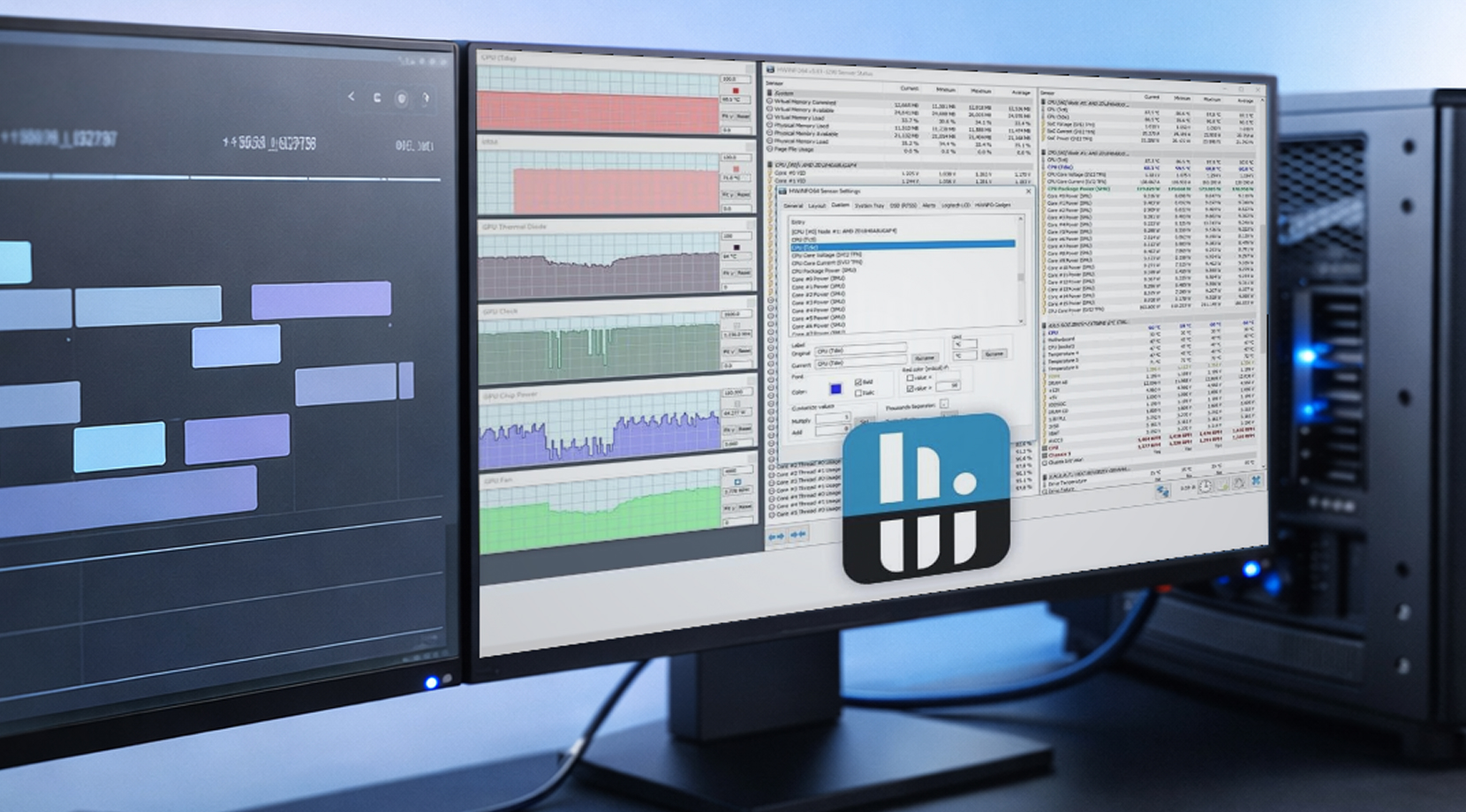
HWiNFO สำหรับการบันทึกข้อมูลบน Windows
HWiNFO ได้รับความนิยมในกลุ่มผู้ใช้ workstation เพราะอ่านค่า sensor ได้ครอบคลุมและบันทึก log ได้ง่ายต่อการแชร์ แค่ไฟล์ CSV ที่มี timestamp ก็เปลี่ยนรายงานที่คลุมเครือให้กลายเป็นข้อมูลที่นำไปแก้ปัญหาได้จริง
ถ้าคุณกำลังสร้าง workstation log เพื่อติดตามความเสถียรของ GPU ให้เริ่มต้นด้วย metrics เหล่านี้:
- อุณหภูมิและจุดร้อนของ GPU
- VRAM ที่ใช้งาน
- พลังงานบอร์ด
- ความเร็วคลอก
- แพ็กเกจ CPU power (เพราะ platform power limits อาจสร้างปัญหาได้โดยไม่คาดคิด)
นี่คือชุดข้อมูลที่ "เพียงพอต่อการอธิบาย" ข้อมูลทั้งหมด เพราะการบันทึกเซนเซอร์ทั้งหมดจะทำให้ไฟล์อ่านยากขึ้นเท่านั้น
GPU-Z สำหรับการตรวจสอบอย่างรวดเร็ว "GPU นี้คืออะไร"
GPU-Z ยังคงมีประโยชน์ เพราะทำงานได้เร็วและตรงจุด ในทีมที่ใช้ฮาร์ดแวร์หลายรุ่น มันเป็นวิธีที่เร็วที่สุดในการตรวจสอบรุ่น GPU, ข้อมูลพื้นฐานของไดรเวอร์ และค่าเซ็นเซอร์แบบเรียลไทม์ โดยไม่ต้องไล่เปิดเมนูให้เสียเวลา
การทดสอบความเครียด: มีประโยชน์จริงเมื่อมีการบันทึก Log
การทดสอบความเค้นช่วยให้คุณหาสาเหตุของการขัดข้องได้ แต่เฉพาะเมื่อซอฟต์แวร์การจัดการ GPU ของคุณบันทึกข้อมูลในขณะที่ทำการทดสอบ หากไม่มีบันทึกเหล่านั้น คุณจะเหลือแค่ "ขัดข้องอีกแล้ว" และไม่มีลำดับเวลาในการติดตามอะไรเลย
ถึงจุดนี้ ปัญหาที่พบบ่อยมักจะเหมือนกัน ไม่ว่าจะเป็น overlay ไม่แสดงผล ค่าการใช้พลังงานผิดปกติ หรือ log อ่านไม่ออก มาแก้ทีละปัญหาเลย
ปัญหาทั่วไปของซอฟต์แวร์ตรวจสอบ GPU และวิธีแก้ไขแบบเร็ว

ปัญหาส่วนใหญ่มักเกิดจากสาเหตุไม่กี่อย่าง นี่คือวิธีแก้ที่ลองก่อนเป็นอันดับแรก เพราะจัดการปัญหาพื้นฐานได้รวดเร็ว
Overlay หายไปในเกม
หาก overlay หายไปในเกมยุคใหม่ สาเหตุมักมาจาก hook ที่ทำงานเฉพาะเกมนั้น หรือเกิดความขัดแย้งกับระบบ anti-cheat หรือ anti-tamper
สิ่งที่มักช่วยได้:
- อัปเดต RTSS และรีเซ็ตโปรไฟล์รายเกม
- ตั้งค่า "application detection level" ให้สูงขึ้นสำหรับโปรไฟล์เกม
- ลองใช้ API อื่นหากเกมรองรับ
- ใช้ overlay ในตัวเป็นตัวเลือกสำรอง เมื่อชื่อเรื่องบล็อก overlay จากบุคคลที่สาม
ไม่ใช่ทุกเกมที่จะให้ความร่วมมือ และไม่คุ้มที่จะเสียเวลาหลายชั่วโมงไปกับเกมที่แก้ไขไม่ได้สักที
ค่าพลังงานแปลกๆ (0W, เส้นแบน, เซนเซอร์หายไป)
ปัญหานี้พบบ่อยบนแล็ปท็อปและอุปกรณ์แบบไฮบริด ที่ GPU ที่ทำงานอยู่อาจเปลี่ยนได้ ในกรณีเหล่านั้น ให้ตรวจสอบข้ามกับเครื่องมือที่สอง เช่น nvidia-smi (NVIDIA) หรือ AMD SMI (AMD) เพราะทั้งสองช่วยยืนยันได้ว่า GPU ตัวไหนกำลังทำงานอยู่จริง
ล็อกมากเกินไป
สาเหตุหลักมักเป็นการเก็บข้อมูลถี่เกินไป สำหรับการแก้ปัญหาทั่วไป ช่วง 1 ถึง 5 วินาทีก็เพียงพอ สำหรับงาน AI ที่รันนาน 5 วินาทีก็ใช้ได้ ช่วงเวลาที่สั้นกว่านี้จะทำให้ไฟล์ใหญ่ขึ้นและกราฟอ่านยากขึ้น
เมื่อจัดการพื้นฐานเหล่านี้ได้แล้ว การมอนิเตอร์ระยะไกลคือขั้นตอนถัดไปที่สมเหตุสมผล เพราะ workflow ของ GPU หลายอย่างในตอนนี้รันบนเครื่องอื่น
การมอนิเตอร์ GPU ระยะไกล และตัวเลือก Cloud ที่ใช้ได้จริง
การทำงานระยะไกลเปลี่ยนความหมายของ "ซอฟต์แวร์มอนิเตอร์ GPU ที่ดี" คุณไม่ได้จ้องหน้าจอเครื่องตลอดเวลา จึงต้องการวิธีตรวจสอบที่รันได้เร็ว พร้อมประวัติที่กลับมาดูย้อนหลังได้
รูปแบบการมอนิเตอร์ระยะไกลที่ดีมักมีลักษณะดังนี้:
- การตรวจสอบ CLI (nvidia-smi หรือ AMD SMI)
- ไฟล์ล็อกที่ดึงมาดูภายหลังได้
- ตัว exporter หรือ dashboard หากต้องการการแจ้งเตือน
หากถึงจุดที่ฮาร์ดแวร์ในมือเป็นข้อจำกัด (ข้อจำกัดด้าน VRAM, การใช้ GPU ตัวเดียวร่วมกัน, หรือต้องการสภาพแวดล้อมสะอาดแยกตามโปรเจกต์) การรัน workload บน GPU VPS อาจเป็นวิธีที่ง่ายที่สุดในการเดินหน้าต่อ
Cloudzy GPU VPS

หากต้องการ GPU ระยะไกลที่รองรับ workflow ด้าน AI, เกม, และการเรนเดอร์ บริการ Cloudzy GPU VPS ของเรามีตัวเลือก NVIDIA อย่าง RTX 5090, A100, และ RTX 4090 พร้อมพื้นที่เก็บข้อมูล NVMe, สิทธิ์ root เต็มรูปแบบ, การเชื่อมต่อสูงสุด 40 Gbps, การป้องกัน DDoS, และเป้าหมาย uptime ที่ระบุไว้ที่ 99.95%
ในแง่ของการมอนิเตอร์ มันทำงานเหมือนเครื่องปกติ คุณสามารถรันซอฟต์แวร์มอนิเตอร์ GPU ผ่าน SSH, บันทึก metric ของ GPU สำหรับงานที่รันนาน, และเพิ่ม dashboard หากต้องการประวัติและการแจ้งเตือน
หากยังตัดสินใจไม่ได้ระหว่าง GPU instance กับการตั้งค่าแบบ CPU อย่างเดียว บทความของเราเรื่อง GPU VPS คืออะไร และ GPU กับ CPU VPS อธิบายความแตกต่างที่ใช้งานได้จริงตาม workload แต่ละประเภท
เมื่อครอบคลุมเรื่องการมอนิเตอร์ระยะไกลแล้ว ขั้นตอนสุดท้ายคือรวบรวมทุกอย่างเข้าด้วยกันเป็น stack ที่คัดลอกไปใช้ได้เลย
Stack พร้อมใช้สำหรับแต่ละกลุ่มผู้ใช้
นี่คือ stack ที่ทำตามได้ง่าย นำไปใช้ได้โดยไม่ต้องเขียน workflow ใหม่ทั้งหมด เหมาะสำหรับเป็นจุดเริ่มต้น แล้วค่อยปรับแต่งให้เข้ากับความต้องการของคุณในภายหลัง
- ตัวสร้างโมเดล (AI/ML): ซอฟต์แวร์มอนิเตอร์ GPU ผ่าน nvidia-smi หรือ AMD SMI บวกกับล็อก CSV แบบเรียบง่าย บวกกับ exporter หรือ dashboard หากงานรันโดยไม่มีคนดูแล
- นักเล่นเกมแข่งขัน/สตรีมเมอร์: ซอฟต์แวร์มอนิเตอร์ GPU แบบ overlay ผ่าน Afterburner + RTSS พร้อมเครื่องมือจับ frametime สำหรับเปรียบเทียบ และชุด metric บนหน้าจอที่กระชับที่สุด
- ผู้ใช้ Workstation ซอฟต์แวร์มอนิเตอร์ GPU ผ่านการ log ด้วย HWiNFO พร้อม GPU-Z สำหรับตรวจสอบตัวตนเร็ว ๆ และ stress test เฉพาะเมื่อสามารถ log การรันได้
- การดูแล GPU Machines ในฐานะ Admin: ซอฟต์แวร์มอนิเตอร์ GPU แบบ as-a-service: exporter + dashboards + alerts พร้อมการมองเห็นระดับ process (nvtop) สำหรับเครื่องที่ใช้ร่วมกัน
ถ้าจะจำอะไรจากคู่มือนี้สักอย่าง จำไว้อย่างนี้: เลือกซอฟต์แวร์มอนิเตอร์ GPU ตามที่คุณต้องการข้อมูล ไม่ว่าจะเป็น overlay, log หรือ dashboard จากนั้นตั้ง metric set ให้เล็กพอที่คุณจะใช้จริง