Програмне забезпечення моніторингу GPU — це те, що може перетворити «мій GPU поводиться дивно» на чітке пояснення типу «hotspot зросла, частоти впали, а VRAM переповнена».
У цьому посібнику я покажу вам інструменти для завдань штучного інтелекту, ігрових оверлеїв та тривалих сесій робочої станції, а також метрики GPU, які допомагають діагностувати гальмування, заїкання та збої.
Наприкінці у вас буде налаштування програмного забезпечення моніторингу GPU, яке відповідатиме вашому робочому процесу. Ви також отримаєте готові конфігурації для чотирьох найпоширеніших сценаріїв, щоб вам не довелось шукати статті.
Швидка відповідь: найкращі варіанти програмного забезпечення GPU для моніторингу за варіантами використання
Якщо вам потрібен короткий список, відповідний реальним робочим процесам, почніть з цих. На практиці найкращий набір програмного забезпечення GPU для моніторингу — це зазвичай комбінація: один інструмент для швидких перевірок, один для оверлеїв або логів, і один для історії або сповіщень.
Ось швидка карта:
| Сценарій використання | Рекомендований набір для старту | Що ви отримуєте |
| Навчання штучного інтелекту, висновок, завдання HPC | nvidia-smi (NVIDIA) або AMD SMI (AMD) + логування/експортер | Швидкі перевірки, скрипти логів, легко налаштувати сповіщення |
| Ігри на Windows | MSI Afterburner + RTSS + інструмент захоплення часу кадрів | Оверлей плюс доказ затримок проти низької частоти кадрів |
| Ігри на Linux | MangoHud + перевірка в терміналі (nvtop) | Легкий оверлей плюс перевірки стану для кожного процесу |
| Робочі станції (3D/відео/CAD) | HWiNFO логування + простий стрес-тест | Довгі логи, які можна поділитися, повторювані кроки для відтворення |
| Спільні машини GPU | nvtop (Linux) + експортер/дашборд | Видимість VRAM для кожного процесу |
Звідси основне завдання - узгодити програмне забезпечення моніторингу GPU з тим, як ви споживаєте дані: на екрані, в логах або на дашборді.
Для кого цей посібник
Я напишу це як той, хто дебажив реальні машини. Тому що з досвіду знаю - різні читачі потребують різних інструментів GPU, навіть якщо дивляться на один і той же GPU.
Ось чотири сценарії, на які я орієнтуюсь:
- Творець моделей (AI/ML): потребує резерву VRAM, стійких тактових частот, обмеження частоти та контролю, чи завдання не перервалось ночами
- Конкурентний геймер/стрімер: потребує моніторингу часу кадрів, стабільності оверлея та виявлення регресій після оновлень драйверів
- Користувач робочої станції (3D/відео/CAD): потребує логів, відтворюваних краш-дампів та визначення впливу температури, живлення та поведінки драйверів
- Адміністратор машин GPU: потребує сповіщень, графіків трендів, планування потужності та раннього виявлення відмов
Коли ви знаєте, до якої групи належите, легко обрати програмне забезпечення для моніторингу GPU, яке вам підходить
Як обрати програмне забезпечення для моніторингу GPU
Багато додатків моніторингу продуктивності виглядають однаково, поки не спробуєш їх використовувати тиждень. Насправді різниця переважно в якості даних та надійності, а не в тих привабливих «функціях», які кожна відчайдушно рекламує.
Ось три запитання, щоб швидко обрати програму моніторингу GPU:
- Тобі потрібен оверлей, логування чи обидва?
Геймери хочуть оверлей. AI та робота на станціях зазвичай потребують логування. Адміністраторам потрібні логи плюс сповіщення. - Потрібна тобі видимість по окремим процесам?
Якщо комп'ютер ділиться між кількома користувачами (лаб, студія, віддалений сервер), видимість по процесам VRAM часто першое, що ти шукаєш. - Потрібна тобі історія та сповіщення?
Коли завдання виконуються вночі, «перевірю пізніше» недостатньо. Потрібен граф та сповіщення.
Щоб залишитися практичним, решта посібника організована за метриками GPU, а потім за стеками інструментів для кожного сценарію.
Метрики GPU, на яких варто зосередитися
Good програма моніторингу GPU видає масу цифр. Справді корисна програма видає саме той невеликий набір, який пояснює поведінку. Я групую метрики GPU за рішенням, яке вони допомагають прийняти.
Метрики температури та дроселювання
Це метрики GPU, які пояснюють «було швидко 10 хвилин, потім став повільний»:
- температура GPU
- Температура гарячої точки (часто перша, що стрибає)
- Температура пам'яті та переходу (більш важлива під час довгих AI-обчислень та рендерування)
- Швидкість вентилятора (допомагає помітити профілі ноутбука чи погані криві вентиляторів)
Якщо хочеш поліпшити стабільність, логуй ці метрики — окремі моменти часу рідко дають достатньо інформації.
Потужність, тактові частоти та обмеження
Ці метрики GPU пояснюють зниження частоти та нестабільну продуктивність:
- Споживання потужності платою
- Частота ядра та частота пам'яті
- Ліміт потужності/стан продуктивності (якщо твій інструмент це показує)
У більшості реальних налагоджувань потужність та частоти дають набагато яснішу картину, ніж просто «використання GPU %».
VRAM і навантаження на пам'ять
Ці метрики GPU пояснюють затримки, помилки нестачі пам'яті та типові «випадкові» сповільнення:
- VRAM використано vs всього
- Активність контролера пам'яті (допомагає виявити обмеження пропускної здатності)
- Системне навантаження RAM (тому що переповнення VRAM може сповільнити всю систему)
Для AI VRAM часто є жорстким обмеженням. Для ігор навантаження на VRAM зазвичай спочатку проявляється як стрибки frametime.
Метрики Frametime та Frame Pacing
Для ігор та стрімінгу самі FPS можуть бути оманливі. Frametime — це метрика, на яку варто звертати увагу, адже вона показує гладкість або її відсутність:
- Час кадру (мс)
- 1% низько / 0.1% низько (добре підходить для порівнянь)
- GPU зайнята проти CPU зайнята (допомагає розділити вузькі місця GPU від вузьких місць CPU)
Ось чому ігрові програми моніторингу продуктивності часто включають шлях захоплення frametime. Розібравшись з основними метриками, можна поговорити про найкращий софт для моніторингу GPU на різні сценарії роботи.
Софт для моніторингу GPU при роботі з AI, навчанням та серверами

AI моніторинг має просту схему з швидкими перевірками в терміналі, плюс логи й сповіщення для довгих запусків. Для цього потрібен софт моніторингу GPU, який працює з CLI й експортує метрики.
NVIDIA: nvidia-smi для швидких перевірок та скриптованих логів
На системах NVIDIA, nvidia-smi зазвичай першої команди, яку запускають люди, адже вона поставляється з драйвером і призначена для моніторингу та управління через NVML.
Офіційна документація тут: Інтерфейс управління системою NVIDIA (nvidia-smi).
Якщо потрібен простий підхід «залогувати й подивитися пізніше» (а таких випадків буває більше, ніж ви думаєте), цей шаблон дуже надійний:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
Це базова поведінка софту для моніторингу GPU з часовими мітками, основними метриками GPU та виводом, який добре працює зі скриптами.
AMD: AMD SMI для ROCm та HPC-вузлів
На обчислювальних вузлах AMD та Linux AMD SMI це сучасний інтерфейс моніторингу та управління. AMD документує його як єдиний набір інструментів для моніторингу та контролю в HPC-середовищах.
Офіційна документація тут: Документація AMD SMI.
Якщо ваше середовище активно використовує AMD, AMD SMI це основа для GPU моніторингу, на якій будується більшість інших інструментів.
Per-Process Visibility: nvtop для спільних GPU
Якщо у вас коли-небудь була спільна машина, де VRAM «таємничо» залишається завантаженою, видимість за процесами економить час. На Linux nvtop популярна саме з цієї причини, бо дає чітку відповідь на запитання «хто використовує VRAM?». На AMD/Intel вам може знадобитися свіжіше ядро для статистики per-process.
У змішаних командах люди часто запускають nvtop поруч з nvidia-smi або AMD SMI. Це простий варіант, який дозволяє уникнути здогадок, тому я його настійно рекомендую.
Не Забувайте про Вибір Обладнання!
Моніторинг не вирішує проблему VRAM; він просто робить цей стан видимим. Якщо ви все ще розподіляєте навантаження на GPU рівні, наш посібник про Найкращі GPU для машинного навчання у 2025 році буде корисною підтримкою, оскільки пояснює VRAM та пропускну спроможність так само, як ви їх пізніше читатимете в логах та дашбордах.
Коли серверний GPU моніторинг працює як слід, наступний крок це оверлеї та frametime, оскільки інтерактивні навантаження поводяться по-іншому.
GPU Моніторинг для Ігор та Стрімінгу

Ігри це район, де люди мають найсильніші думки про GPU інструменти, здебільшого тому що оверлеї виходять з ладу у найгіршу мить. Для ігор потрібні простий оверлей та передбачувані вимірювання frametime.
MSI Afterburner + RTSS для оверлеїв на Windows
Цей комбо популярний, оскільки дозволяє створити чистий оверлей з точно тими GPU метриками, які вас цікавлять, наприклад утилізація, частота, VRAM, температура, frametime та швидкість вентилятора.
Одне серйозне попередження, що часто з'являється в треди спільноти, це підробні сайти завантаження. Сама сторінка MSI про Afterburner вказує, що легітимні завантаження повинні йти з msi.com та Guru3Dі також вказує поточну лінійку релізів (4.6.6 final, випущено жовтень 2025).
Проблеми з оверлеєм це ще одне, на що варто звернути увагу. Наприклад, RTSS працює в деяких іграх і виходить з ладу в інших, особливо в сучасних шляхах рендерингу. Люди повідомляють про випадки, коли оверлей з'являється у Vulkan, але не в DX12 для того ж самого титулу, або зникає після оновлень.
Однак це трапляється не через помилку з вашого боку, просто так бувається, коли оверлеї підключаються до що змінюється стека ігор і драйверів.
Якщо хочете стабільний оверлей без зайвого, тримайте його коротким:
- час кадру
- Використання GPU
- VRAM використано
- температура GPU
Додавайте живлення та частоти лише якщо активно налагоджуєте троттлінг.
Захоплення часу кадру для виявлення «заїканням»
Тут допомагають програми моніторингу продуктивності, які можуть записувати графіки часу кадру. Середня кількість FPS може виглядати нормально, але синхронізація кадрів відчувається жахливо. Графіки часу кадру швидко розвіюють цю плутанину.
Багато ігрових бенчмарків використовують PresentMon як основу, і NVIDIA документи його FrameView аналітика використовує PresentMon для запису частоти кадрів і часу кадру.
Не потрібно тестувати кожну гру. Захоплення часу кадру найкорисніше для порівнянь — до та після оновлення драйвера, до та після зміни лімітера, до та після зміни налаштувань тощо.
MangoHud для оверлеїв Linux
На Linux часто рекомендують MangoHud, тому що він легкий і добре інтегрується зі Steam/Proton. Найчастіші скарги — про відсутні датчики або дивні показання на гібридних лаптопах.
На практиці можете легко комбінувати MangoHud з терміналом для перевірки типу nvtop. Це також хороший приклад того, як програмне забезпечення моніторингу GPU працює набагато краще як невелика стопка інструментів, а не один величезний застосунок.
Від ігрових настроєнь природно переходять на моніторинг робочих станцій, де головне — логи та можливість відтворити проблему.
Розміщуйте ігрові сервери без лагів на швидкісному NVMe VPS-хостингу.
VPS для ігор
Програмне забезпечення моніторингу GPU для робочих станцій і професійних додатків
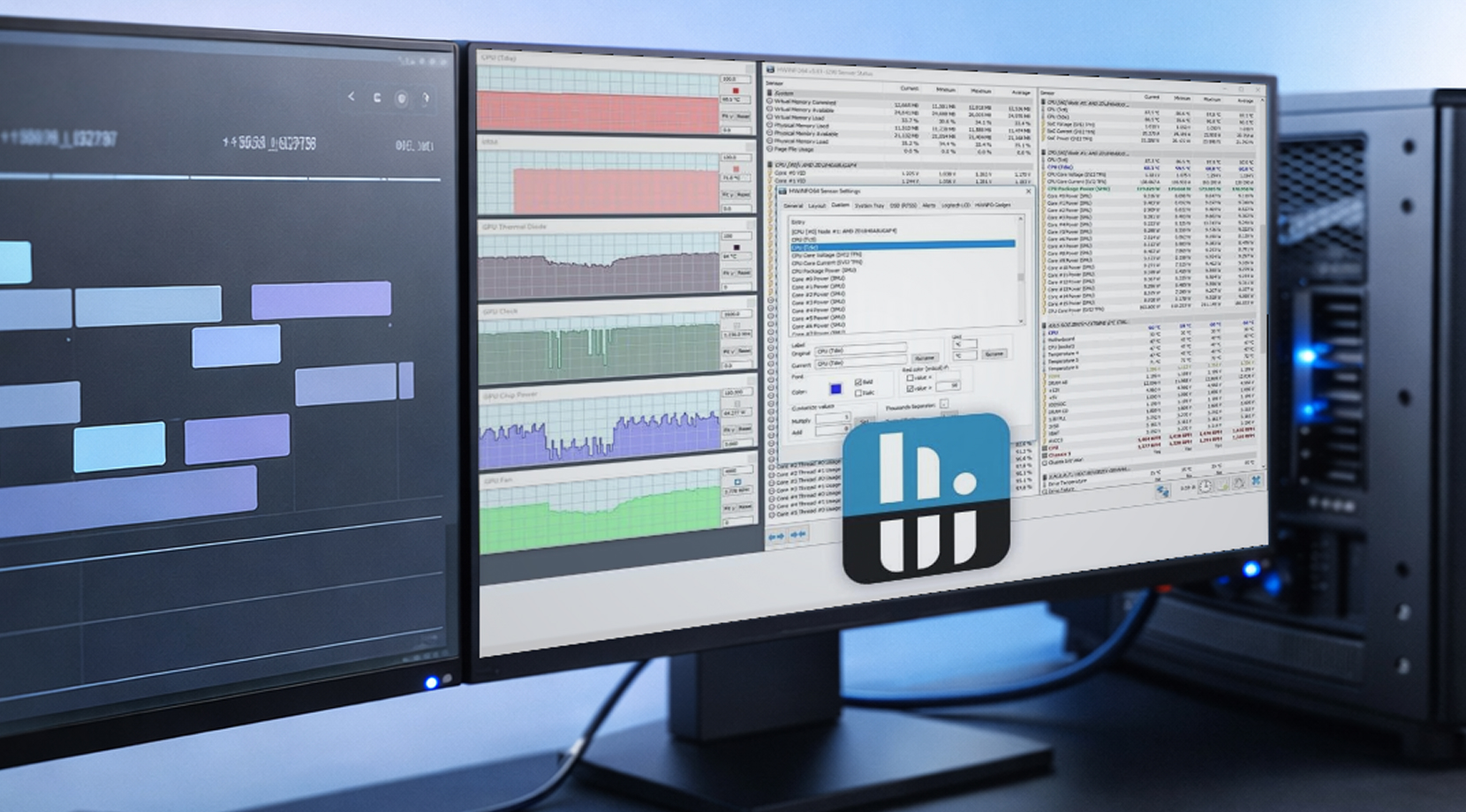
Моніторинг робочої станції — це не спостереження за живим оверлеєм, а пошук відповідей на запитання «Що сталося з часом, і я можу це відтворити?»
HWiNFO для логування на Windows
HWiNFO популярен у середовищі робочих станцій завдяки глибокому охопленню датчиків і логам, які легко поділити. Простий CSV-лог з часовими мітками може перетворити невизначений звіт на щось, що насправді допомагає виправити проблему.
Якщо будуєте лог стабільності GPU для робочої станції, почніть з цих метрик GPU:
- Температура та гарячка GPU
- VRAM використано
- живлення плати
- тактова частота ядра
- Потужність пакета CPU (тому що обмеження потужності платформи можуть вас укусити)
Це набір «достатньо даних для пояснення». Логування кожного датчика просто ускладнює читання файлу.
GPU-Z для швидких перевірок «Який це GPU?»
GPU-Z залишається корисним, тому що він швидкий і зосереджений. У командах із змішаним обладнанням це найшвидший спосіб підтвердити модель GPU, основи драйвера та живі датчики без занурення в меню.
Стрес-тестування: корисне лише з логуванням
Стрес-тести можуть допомогти відтворити крах, але тільки якщо ваше програмне забезпечення моніторингу GPU логує під час їх запуску. Без цих логів у вас залишається «це знову впало» і фактично жоден часовий ряд.
На цьому етапі більшість людей зіштовхуються з однаковими проблемами: оверлеї не показуються, показання потужності виглядають невірно, а логи стають нечитаними. Давайте вирішимо це прямо.
Поширені проблеми з ПЗ для моніторингу GPU та швидкі рішення

Більшість проблем укладаються в кілька сценаріїв. Це ті способи, які я спробую першими, тому що вони швидко вирішують нудні речі.
Оверлей не з'являється в грі
Якщо оверлей зникає в новій грі, це часто проблема хука на окрему гру або конфлікт з античітом чи шарами захисту від модифікацій.
Що можна спробувати:
- Оновіть RTSS і скиньте профіль на окрему гру
- Встановіть вищий рівень «виявлення застосунку» для профілю гри
- Спробуйте інший API, якщо гра його підтримує
- Повертайтесь до вбудованих оверлеїв, коли гра блокує сторонні оверлеї
Не кожна гра буде співпрацювати, і не варто витрачати години на одну впертую гру.
Дивні показання потужності (0W, плоскі лінії, відсутні датчики)
Це часто траплялося на ноутбуках і гібридних установках, де активний GPU може змінюватися. У цих випадках перевірте себе другим інструментом, наприклад nvidia-smi (NVIDIA) або AMD SMI (AMD) — вони хорошо показують, чи дійсно GPU активний.
Забагато шуму в логах
Надмірна вибірка — звичайна причина. Для більшості діагностики 1-5 секунд достатньо. Для тривалих завдань на AI 5 секунд нормально. Коротші інтервали роблять файли більшими і ускладнюють читання графіків.
Коли основи розібрані, дистанційний моніторинг стає наступним логічним кроком, тому що багато робочих процесів GPU тепер працюють поза машиною.
Дистанційний моніторинг GPU та практичний варіант у хмарі
Дистанційна робота змінює, що означає «гарне програмне забезпечення для моніторингу GPU». Ви не завжди дивитеся на машину, тому вам потрібні перевірки, які можна запустити швидко, та історія, яку можна переглянути пізніше.
Чиста дистанційна установка зазвичай виглядає так:
- Перевірки CLI (nvidia-smi або AMD SMI)
- файл логу, який ви можете завантажити пізніше
- експортер/панель інструментів, якщо вам потрібні сповіщення
Якщо локальне обладнання блокує прогрес (обмеження VRAM, спільне використання однієї GPU, потреба в чистому середовищі для кожного проекту), запуск робочих навантажень на GPU VPS часто найпростіший спосіб рухатися вперед.
Cloudzy GPU VPS

Якщо вам потрібен дистанційний час роботи GPU для робочих процесів на AI, ігор та рендерингу, наш Cloudzy GPU VPS включає варіанти NVIDIA, такі як RTX 5090, A100 та RTX 4090, плюс сховище NVMe, повний корінь, з'єднання до 40 Gbps, захист DDoS та задекларований час безперервної роботи 99,95%.
З точки зору моніторингу це працює як звичайна машина: ви можете запустити програмне забезпечення для моніторингу GPU через SSH, логувати метрики GPU для довгих завдань та додавати дашборди, якщо потрібна історія та сповіщення.
Якщо ви все ще вагаєтеся між екземпляром GPU та налаштуванням тільки CPU, наші матеріали про Що таке GPU VPS? та порівняння GPU і CPU VPS розбирають практичні відмінності за типами завдань.
З дистанційним моніторингом розібралися, залишилось скласти все в готові конфігурації.
Готові конфігурації для кожного типу користувача
Ось легкі для запозичення конфігурації, які можна використати без переписування всього вашого робочого процесу. Це хороші стартові точки, які ви потім зможете налаштувати під свої потреби.
- Конструктор моделей (AI/ML): Програмне забезпечення для моніторингу GPU через nvidia-smi або AMD SMI, плюс простий CSV лог, плюс експортер/дашборд, якщо завдання працюють без нагляду.
- Геймер-стрімер: Накладання програмного забезпечення для моніторингу GPU через Afterburner + RTSS, плюс інструмент для захоплення frametime для порівняння, плюс мінімальний набір метрик на екрані.
- Користувач Робочої станції Програмне забезпечення для моніторингу GPU через HWiNFO логування, плюс GPU-Z для швидких перевірок, плюс стрес-тест тільки коли можете залогувати запуск.
- Адміністратор, що керує машинами GPU: Програмне забезпечення для моніторингу GPU як сервіс: експортер + дашборди + сповіщення, плюс видимість для окремих процесів (nvtop) для спільних машин.
Якщо візьмете одне з цього посібника, то це: вибирайте програмне забезпечення для моніторингу GPU за місцем, де вам потрібні дані (накладання, лог, дашборд), потім тримайте набір метрик досить малим, щоб ви насправді його використовували.