
Mit dem wachsenden Interesse an lokalen LLMs stehen viele Nutzer vor der Qual der Wahl. Der Betrieb ist dabei alles andere als trivial: Lokale Modelle brauchen teils erhebliche Ressourcen, manche mehr als andere, weshalb viele einen großen Bogen darum machen. Ganz zu schweigen von den Stunden, die Einsteiger damit verbringen, auf eine Terminalzeile zu starren.
Es gibt jedoch zwei Plattformen, die den Einstieg deutlich erleichtern. Ollama und LM Studio sind zwei der verbreitetsten Lösungen für den Betrieb lokaler LLMs, mit jeweils starker Leistung. Die Wahl zwischen den beiden ist aber nicht trivial, da jede auf andere Arbeitsweisen ausgelegt ist. Schauen wir uns also den direkten Vergleich an: Ollama vs LM Studio.
Ollama als Werkzeug für technisch versierte Nutzer
Unter den Lösungen für lokale LLMs ist Ollama eine starke Wahl, dank seines großen Funktionsumfangs. Es ist nicht nur hochgradig konfigurierbar, sondern auch kostenlos nutzbar, da es eine community-getriebene Open-Source-Plattform ist.
Ollama vereinfacht den Betrieb lokaler LLMs, setzt aber grundlegende Terminalkenntnis voraus, da es primär über die CLI (Command Line Interface) bedient wird. Für Entwicklungsworkflows ist das ein klarer Vorteil: CLI-Befehle sind präzise und direkt. Zwar ist der Umgang mit einer CLI kein Kinderspiel, aber der Einstieg geht deutlich schneller als der manuelle Betrieb lokaler LLMs.
Ollama verwandelt Ihren eigenen Rechner in einen lokalen Mini-Server mit einem HTTP API. Apps und Skripte erhalten so Zugriff auf verschiedene Modelle und können Anfragen stellen, genau wie bei einem Online-LLM, ohne dass Daten in die Cloud übertragen werden. Das API erlaubt es außerdem, Ollama in Websites und Chatbots einzubinden.
Durch den CLI-Ansatz ist Ollama zudem ressourcenschonend und auf Leistung ausgelegt. Das bedeutet nicht, dass ein veralteter Rechner ausreicht, aber wer jede verfügbare Ressource dem Modell selbst zuführen möchte, ist hier auf einem guten Weg.
Es dürfte inzwischen klar sein: Ollama ist stark auf Entwicklungsworkflows ausgerichtet. Dank einfacher Integration, lokaler Datenhaltung und API-first-Design ist die Wahl eindeutig, wenn man mit Entwickler-Mindset arbeitet.
Im Vergleich Ollama vs LM Studio kann Ollama durch seinen API-first-Ansatz punkten. Wer aber mit einer CLI nichts anfangen kann, sollte weiterlesen: Es gibt eine leichtgewichtigere Alternative, die auf Benutzerfreundlichkeit ausgelegt ist.
LM Studio: Die benutzerfreundliche Option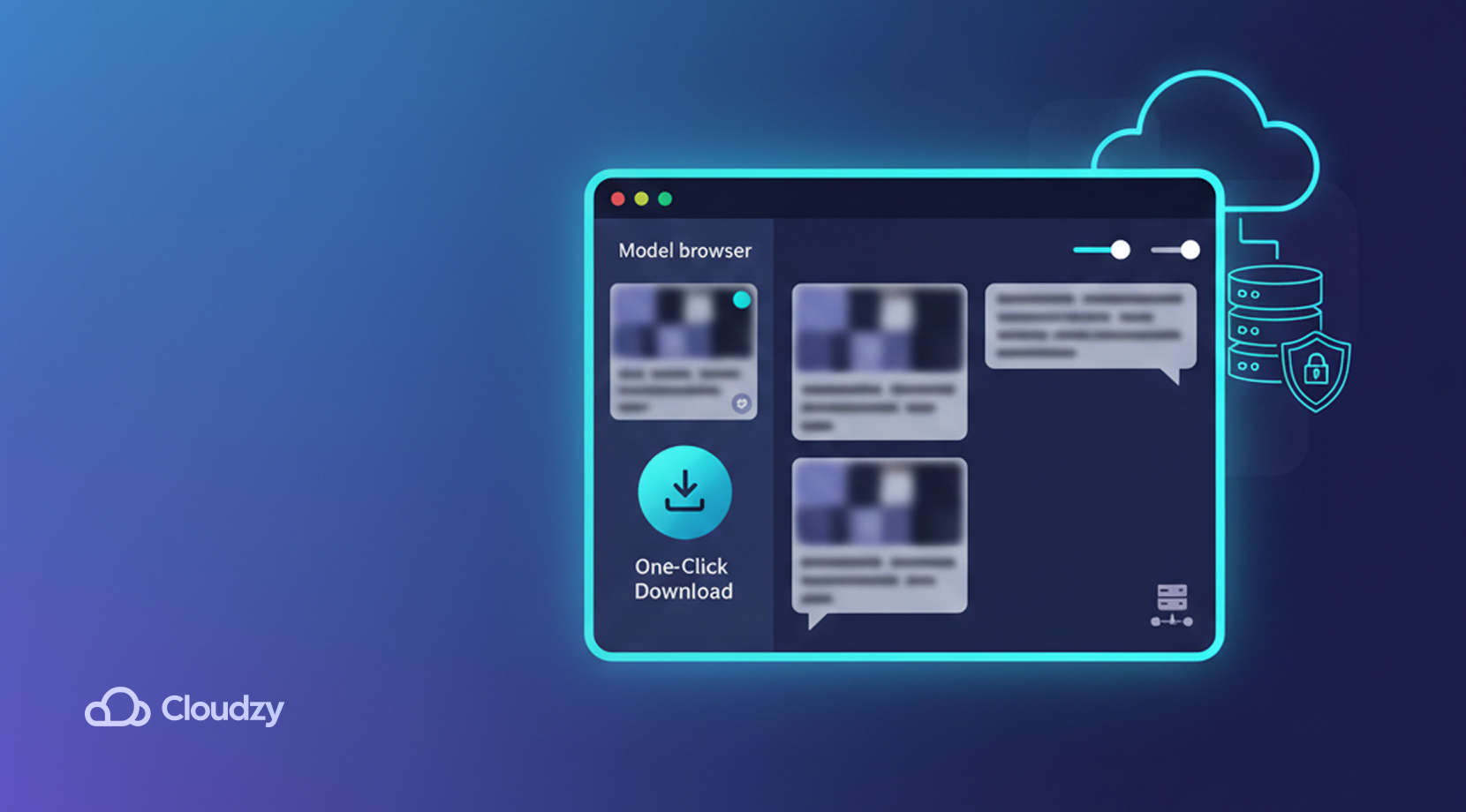
LM Studio unterscheidet sich grundlegend von Ollama. Statt einer reinen CLI-Oberfläche kommt es mit einer GUI (Graphical User Interface) daher und sieht aus wie jede andere Desktop-App. Kein Terminal, keine Befehle. Für viele Einsteiger reduziert sich die Frage Ollama vs LM Studio daher auf: CLI vs GUI.
LM Studio senkt die technische Einstiegshürde konsequent. Anstatt Modelle per Kommandozeile hinzuzufügen und zu starten, navigiert man durch Menüs und tippt in ein Chat-ähnliches Eingabefeld. Die Oberfläche erinnert an ChatGPT, sodass praktisch jeder sofort mit lokalen LLMs experimentieren kann.
Dazu kommt ein übersichtlicher In-App-Modellbrowser, über den Nutzer Modelle entdecken und direkt starten können. Das Angebot reicht von leichten Modellen für alltägliche Aufgaben bis hin zu rechenintensiven Modellen für anspruchsvolle Anforderungen. Der Browser zeigt kurze Beschreibungen und empfohlene Einsatzbereiche an und ermöglicht den Download per Klick.
Die meisten Modelle sind kostenlos, für einige gelten jedoch zusätzliche Lizenzbedingungen und Nutzungsrechte. Für bestimmte Workflows bietet LM Studio auch einen lokalen Servermodus für einfache Integrationen, der Fokus liegt jedoch klar auf der benutzerfreundlichen Desktop-Oberfläche für Einsteiger. Betrachten wir nun Ollama und LM Studio direkt nebeneinander.
Wichtige Beobachtungen: Ollama vs LM Studio
Bevor wir weitermachen, ein wichtiger Hinweis: Die Formulierung "Ollama vs LM Studio" klingt nach einem klaren Gewinner, aber so einfach ist es nicht. Beide Tools richten sich an unterschiedliche Zielgruppen. Hier ein kurzer Überblick zum Vergleich Ollama vs LM Studio.
| Funktion | Ollama | LM Studio |
| Benutzerfreundlichkeit | Weniger einsteigerfreundlich, setzt Kenntnisse im Terminal voraus | Einsteigerfreundlich, funktioniert größtenteils per Mausklick |
| Modellunterstützung | Viele bekannte Open-Weight-Modelle: gpt-oss, gemma 3, qwen 3 | Dieselben wie bei Ollama: gpt-oss, gemma3, qwen3 |
| Anpassbarkeit | Sehr flexibel anpassbar, lässt sich einfach über API integrieren | Weniger Spielraum, gängige Einstellungen über Schalter und Schieberegler |
| Hardwareanforderungen | Das kommt drauf an: Größere Modelle sind ohne ausreichende Hardware langsamer | Auch hier abhängig von der Modellgröße und der eigenen Hardware |
| Datenschutz | Standardmäßig hoher Datenschutz, keine zusätzlichen externen API | Chats bleiben lokal gespeichert. Die App kontaktiert jedoch Server für Updates sowie die Modellsuche und -downloads. |
| Offline-Nutzung | Voll offline-fähig, sobald die Modelle heruntergeladen sind | Ebenfalls hervorragend offline nutzbar, sobald die Modelle geladen sind |
| Verfügbare Plattformen | Linux, Windows, macOS | Linux, Windows, macOS |
- Hardware-Probleme mit großen Modellen: Wer kann, greift lieber zu einem größeren und leistungsfähigeren Modell. Auf den meisten Laptops kann das jedoch zu ernsthaften Problemen führen, da größere Modelle deutlich mehr RAM und VRAM benötigen. Die Folge: langsame Antworten, eingeschränkte Kontextlänge oder ein Modell, das sich gar nicht erst laden lässt.
- Akkuprobleme: Lokal ausgeführte LLMs können den Akku unter Last schnell leeren. Das verkürzt die Akkulaufzeit spürbar und sorgt obendrein für lästigen Lärm durch Lüfter und Kühlkörper.
Ollama vs. LM Studio: Modelle laden
Ein weiterer Unterschied zwischen Ollama und LM Studio liegt darin, wie Modelle heruntergeladen werden. Wie bereits erwähnt, installiert Ollama lokale LLMs nicht per Klick. Stattdessen werden dafür das integrierte Terminal und entsprechende Befehle genutzt. Die Befehle selbst sind dabei leicht verständlich.
So kannst du Modelle schnell auf Ollama ausführen.
- Lade dein bevorzugtes Modell mit dem Befehl ollama pull gpt-oss oder einem anderen Modell deiner Wahl (vergiss nicht, einen Tag anzugeben, den du aus der Bibliothek auswählen kannst).
Beispiel: ollama pull gpt-oss:20b - Das Modell kannst du anschließend mit dem Befehl ollama run gpt-oss starten.
- Weitere Coding-Tools lassen sich ebenfalls einbinden. Claude kannst du zum Beispiel mit ollama launch claude hinzufügen.
Wenn du nicht gerne mit Terminals und Befehlen arbeitest, ist LM Studio eine gute Alternative. Du musst nichts in ein Terminal eingeben, damit es funktioniert und Modelle lädt. Öffne einfach den integrierten Modell-Downloader und suche nach LLMs mit Schlagwörtern wie Llama oder Gemma.
Alternativ kannst du vollständige Hugging Face URLs in die Suchleiste eingeben.
Es gibt sogar eine Option, den Discover-Tab von überall aufzurufen, indem du ⌘ + 2 auf dem Mac drückst, oder Ctrl + 2 unter Windows / Linux.
Ollama: Klar im Vorteil bei der Geschwindigkeit
Manchmal zählt für Nutzer und Unternehmen nur die Geschwindigkeit. Beim Vergleich Ollama vs. LM Studio schneidet Ollama in dieser Hinsicht schneller ab, wobei das je nach Konfiguration und Hardware variieren kann.
Wie ein Reddit-Nutzer im r/ollama-Subreddit berichtete, verarbeitete Ollama schneller als LM Studio.
Das ist keine unbelegte Behauptung: Der Nutzer hat sowohl Ollama als auch LM Studio getestet, indem er qwen2.5:1.5b jeweils fünf Mal ausgeführt und den Durchschnitt der Tokens pro Sekunde berechnet hat.
Ollama vs. LM Studio: Leistung und Hardwareanforderungen
Beim Thema Leistung geht es im Vergleich Ollama vs. LM Studio weniger um die Benutzeroberfläche als um die Hardware. Lokale LLMs zum ersten Mal zu nutzen ist ein ganz anderes Erlebnis als die Cloud-LLMs, die wir kennen. Es fühlt sich gut an, ein LLM ganz für sich zu haben, bis man an die Grenzen der Hardware stößt.
Da die Preise für RAM und VRAM in den letzten Jahren stark gestiegen sind, ist es ziemlich schwer, die eigene Maschine mit genug Leistung auszustatten, um große LLMs zu betreiben.
Beliebte Modelle verbrauchen schnell 24-64 GB RAM
Genau so ist es. Bei den Hardwareanforderungen geht es nicht darum, wer im Vergleich Ollama vs. LM Studio gewinnt. Wer beliebte mittelgroße bis große Modelle ohne Verzögerungen oder Abstürze nutzen will, sollte 24-64 GB RAM einplanen. In den meisten Fällen wird selbst diese Menge bei längeren Kontexten und anspruchsvolleren Aufgaben zum Engpass.
Kleinere, oft als quantisiert bezeichnete Modelle lassen sich zwar mit 8-16 GB RAM betreiben, aber Komfort und Leistung sind nicht mit denen größerer Modelle vergleichbar. Qualitäts- und Geschwindigkeitseinbußen sind dabei unvermeidlich. Und RAM ist leider nicht das einzige Problem: Auch die übrigen Komponenten müssen leistungsstark sein.
Starke GPUs sind ein Eckpfeiler, um Frust fernzuhalten
Auch wenn Modelle auf CPUs laufen können, spielt die GPU nach wie vor eine zentrale Rolle. Ohne eine schnelle GPU und ausreichend VRAM wirst du langsame Token-für-Token-Generierung, lange Wartezeiten bei längeren Antworten und insgesamt eine schnell unerträglich werdende Erfahrung machen.
Mach dir keine Hoffnungen, denn selbst die mächtige RTX 5070Ti oder die RTX 5080 reicht für ernsthaftes Deep Learning nicht aus. Der Grund: Für manche Setups mit 60.000+ Kontext-Tokens gibt Ollama selbst an, dass ~23 GB VRAM benötigt werden - deutlich mehr als die typischen 16 GB VRAM, die diese GPUs bieten.
Going für alles oberhalb dieser Leistungsklasse ist zudem astronomisch teuer. Wer sich keine Gedanken um den Preis macht, hat dennoch einige GPU-Optionen zu bedenken, wenn lokale LLMs betrieben werden sollen.
Inzwischen fragst du dich vielleicht, wie du eine Maschine zusammenstellst, die leistungsstark genug ist, um größere lokale LLM-Modelle auszuführen. Genau an diesem Punkt entscheiden sich viele für eine andere Lösung.
Eine Alternative, die viele Enthusiasten in Betracht ziehen, sind virtuelle Maschinen mit leistungsfähiger, vorinstallierter Hardware. Ein VPS (Virtual Private Server) ist zum Beispiel eine gute Möglichkeit, deinen privaten Laptop oder andere persönliche Hardware mit einem Server deiner Wahl zu verbinden, auf dem bereits alles voreingerichtet ist.
Wenn ein VPS für dich nach einer guten Lösung klingt, empfehlen wir dir ernsthaft Cloudzy's Ollama VPS, in dem du in einer sauberen Shell arbeiten kannst. Ollama ist vorinstalliert, sodass du direkt mit lokalen LLMs arbeiten kannst - mit vollständiger Privatsphäre. Das Angebot ist erschwinglich: 12 Standorte, 99,95 % Uptime und 24/7-Support. Die Ressourcen sind großzügig bemessen, mit dedizierten VCPUs, DDR5 Arbeitsspeicher und NVMe Speicher über eine Verbindung mit bis zu 40 Gbps.
Ollama vs. LM Studio: Wer braucht was
Wie bereits erwähnt, sind beide Plattformen leistungsfähig und keine ist grundsätzlich besser. Der entscheidende Punkt: Jede passt zu einem anderen Arbeitsablauf - es kommt darauf an, was du brauchst.
Ollama wählen für Automatisierung und Entwicklung
Wer Ollama nutzt, will nicht nur mit einem Modell chatten, sondern es als Komponente in einem eigenen Projekt einsetzen. Ollama eignet sich besonders für:
- Entwickler den Aufbau von Produkten wie Chatbots, Copilots und anderen Anwendungen, die Deep Learning erfordern
- Workflows mit hohem Automatisierungsgrad, etwa Skripte zur Report-Zusammenfassung oder geplante Texterstellung
- Teams, die konsistente Modellversionen in jeder Umgebung benötigen
- Nutzer, die einen API-First-Ansatz bevorzugen, damit andere Tools regelmäßig auf Modelle zugreifen können
Kurz gesagt: Wenn Modelle zuverlässig in deinen Apps laufen sollen, ist Ollama wahrscheinlich die richtige Wahl.
LM Studio ist der einsteigerfreundlichere Weg zu lokalen LLMs
Wer lokale KI-Setups ohne technischen Aufwand erkunden möchte, ist mit LM Studio definitiv besser beraten.
LM Studio eignet sich generell besser für:
- Einsteiger die das Terminal und die Kommandozeile scheuen
- Autoren, Kreative oder Studierende, die eine einfache Chat-Oberfläche zur KI-Unterstützung suchen
- Nutzer, die verschiedene Optionen ausprobieren, um schnell verschiedene Modelle zu vergleichen und das Richtige für sich zu finden
- Alle, die gerade erst lernen, mit Prompts zu arbeiten, und Einstellungen lieber per Mausklick statt per Texteingabe anpassen möchten
Kurz gesagt: Wer einfach lokale LLMs herunterladen und sofort loslegen möchte, ist mit LM Studio gut bedient.
Ollama vs. LM Studio: Abschließende Empfehlung
Lässt man den Hype rund um den Vergleich zwischen Ollama und LM Studio beiseite, kommt es wirklich auf den täglichen Arbeitsablauf und die eigenen Hardware-Grenzen an.
Ollama ist generell:
- Flexibel und entwicklerorientiert
LM Studio hingegen ist:
- Einsteigerfreundlich mit einer eigenen grafischen Oberfläche
Beide Tools benötigen leistungsstarke und teure Hardware, um flüssig zu laufen. Nicht jeder hat die Möglichkeit, ein großes lokales LLM eigenständig zu betreiben. Daher gilt: Wer leistungsstarke Modelle nutzen möchte, ohne die eigene Hardware zu belasten, sollte Ollama auf einem dedizierten GPU VPSausprobieren. Im Folgenden finden Sie häufig gestellte Fragen zu Ollama vs. LM Studio.


