El software de monitorización de GPU es lo que convierte un vago «mi GPU no va bien» en una explicación clara y concreta, como «el punto caliente se disparó, las frecuencias bajaron y la VRAM se llenó».
En esta guía te explico las herramientas que puedes usar para cargas de trabajo de IA, overlays para gaming y sesiones largas de workstation, y te muestro las métricas de GPU que ayudan a diagnosticar ralentizaciones, microcortes y cuelgues.
Al terminar, tendrás una configuración de software de monitorización de GPU que se adapta a tu forma de trabajar. También encontrarás stacks listos para copiar en cuatro casos de uso habituales, para que no tengas que buscar más artículos.
Respuesta rápida: mejores herramientas de monitorización de GPU según el caso de uso
Si solo quieres una lista corta que se ajuste a cómo trabaja la gente en la práctica, empieza por aquí. En general, el mejor stack de monitorización de GPU suele ser una combinación: algo para comprobaciones rápidas, algo para overlays o logs, y algo para historial o alertas.
El mapa rápido:
| Caso de uso | Stack de inicio recomendado | Qué obtienes |
| Entrenamiento de IA, inferencia, tareas HPC | nvidia-smi (NVIDIA) o AMD SMI (AMD) + logging/exporter | Comprobaciones rápidas, logs con scripts y alertas sencillas |
| Gaming en Windows | MSI Afterburner + RTSS + una herramienta de captura de frametime | Overlay más datos para distinguir microcortes de FPS bajos |
| Gaming en Linux | MangoHud + un monitor de terminal (nvtop) | Superposición ligera con comprobaciones de estado por proceso |
| Estaciones de trabajo (3D/vídeo/CAD) | Registro con HWiNFO + prueba de estrés básica | Registros detallados que puedes compartir y reproducir |
| Máquinas compartidas GPU | nvtop (Linux) + exportador/panel de control | Visibilidad de VRAM por proceso |
A partir de aquí, lo principal es encontrar el software de monitoreo de GPU que encaje con la forma en que consumes los datos: en pantalla, en un registro o en un panel.
Para quién es esta guía
Voy a escribir esto como alguien que ha tenido que depurar máquinas reales. Porque, por experiencia, sé que distintos usuarios necesitan distintas herramientas para GPU, aunque estén mirando el mismo GPU.
Estos son los cuatro perfiles que tengo en mente:
- El desarrollador de modelos (AI/ML): le preocupa el margen de VRAM, los clocks sostenidos, el throttling y si el trabajo completó la noche sin fallar.
- El jugador competitivo / streamer: le preocupan los frametimes, la estabilidad del overlay y detectar regresiones tras actualizaciones de controladores.
- El usuario de estación de trabajo (3D/vídeo/CAD): le preocupan los registros, los cuelgues reproducibles y distinguir si el problema es de temperatura, consumo o comportamiento del controlador.
- El administrador que gestiona máquinas GPU: le preocupan las alertas, las gráficas de tendencias, la planificación de capacidad y detectar fallos antes de que escalen.
Una vez que sabes en qué perfil encajas, elegir el software de monitoreo de GPU adecuado es sencillo.
Cómo elegir software de monitoreo de GPU
Muchas aplicaciones de monitoreo de rendimiento parecen similares hasta que las usas durante una semana. La diferencia real suele estar en la salida de datos y la fiabilidad, no en esas atractivas «funciones» que cada una anuncia a toda costa.
Te propongo tres preguntas para elegir software de monitoreo de GPU rápidamente:
- ¿Necesitas un overlay, un registro o ambos?
Los jugadores quieren un overlay. El trabajo de AI y estaciones de trabajo suele requerir registros. Los administradores necesitan registros más alertas. - ¿Necesitas visibilidad por proceso?
Si compartes un servidor (laboratorio, estudio, servidor remoto), lo primero que sueles buscar es el VRAM por proceso. - ¿Necesitas historial y alertas?
Si los trabajos se ejecutan de noche, «ya lo compruebo después» no es suficiente. Necesitas una gráfica y una alerta.
Para que esta guía sea práctica, el resto está organizado primero por métricas de GPU y luego por conjuntos de herramientas según cada caso de uso.
Métricas de GPU que deberías priorizar
El software de monitorización de GPU Good te da muchos números. El software realmente útil te da ese puñado concreto que explica el comportamiento. Agrupo las métricas de GPU según la decisión que te ayudan a tomar.
Métricas de temperatura y throttling
Estas son las métricas de GPU que explican «iba rápido durante 10 minutos y luego dejó de hacerlo»:
- Temperatura de GPU
- Temperatura de hotspot (suele ser lo primero en dispararse)
- Temperatura de memoria/junction (más relevante en ejecuciones largas de IA y renders prolongados)
- Velocidad del ventilador (ayuda a detectar perfiles de portátil o curvas de ventilador incorrectas)
Si buscas mejorar la estabilidad, registra estas métricas: una sola captura puntual rara vez da información suficiente.
Consumo, frecuencias y límites
Estas métricas de GPU explican las bajadas de frecuencia y el rendimiento inconsistente:
- Consumo de la placa
- Frecuencia de núcleo y frecuencia de memoria
- Límite de potencia/estado de rendimiento (si tu herramienta lo expone)
En muchos casos reales de depuración, el consumo y las frecuencias ofrecen una imagen mucho más clara que el simple «% de uso de GPU».
VRAM y presión de memoria
Estas métricas de GPU explican los stutters, los errores OOM y las ralentizaciones «aleatorias» más habituales:
- VRAM usada vs total
- Actividad del controlador de memoria (útil para detectar límites de ancho de banda)
- Presión de RAM del sistema (porque el desbordamiento de VRAM también puede arrastrar al sistema)
En IA, la VRAM suele ser el límite absoluto. En juegos, la presión de VRAM se manifiesta primero como picos en el frametime.
Métricas de Frametime y Frame Pacing
En gaming y streaming, los FPS por sí solos pueden engañar. La métrica que realmente importa es el frametime, ya que mide la fluidez, o la falta de ella:
- Tiempo de fotograma (ms)
- 1% bajo / 0.1% bajo (útil para comparaciones)
- GPU ocupada vs CPU ocupada (ayuda a distinguir cuellos de botella de GPU de los de CPU)
Por eso las aplicaciones de monitorización orientadas al gaming suelen incluir una ruta de captura de frametime. Con los conceptos básicos cubiertos, podemos hablar de los mejores stacks de software de monitorización de GPU para cada tipo de uso.
Software de monitorización de GPU para IA, entrenamiento y servidores

La monitorización de IA tiene una configuración sencilla: comprobaciones rápidas en el terminal, más logs y alertas para ejecuciones largas. Para esto, el software de monitorización de GPU que funciona desde la CLI y exporta métricas es lo que necesitas.
NVIDIA: nvidia-smi para comprobaciones rápidas y logs automatizados
En sistemas NVIDIA, nvidia-smi suele ser el primer comando que ejecuta todo el mundo, ya que se incluye con el driver y está diseñado para monitorización y gestión a través de NVML.
La documentación oficial está aquí: Interfaz de Gestión del Sistema NVIDIA (nvidia-smi).
Si quieres un enfoque sencillo de «registrar y revisar después» (y te sorprendería la frecuencia con que esto resuelve el problema), este patrón es bastante fiable:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
Este es el comportamiento básico del software de monitorización GPU: marcas de tiempo, métricas principales de GPU y una salida compatible con scripts.
AMD: AMD SMI para nodos ROCm y HPC
En los nodos de cómputo AMD Linux, AMD SMI es la interfaz moderna de monitorización y gestión. AMD lo documenta como un conjunto de herramientas unificado para la monitorización y el control en entornos HPC.
La documentación oficial está aquí: Documentación de AMD SMI.
Si tu entorno es mayoritariamente AMD, AMD SMI es la base del software de monitorización GPU sobre la que suele apoyarse el resto de herramientas.
Visibilidad por proceso: nvtop para GPUs compartidas
Si alguna vez has tenido un servidor compartido donde la VRAM se llenaba «misteriosamente», la visibilidad por proceso te ahorra mucho tiempo. En Linux, nvtop es la opción más popular precisamente por eso, ya que deja muy claro quién está usando la VRAM. En AMD/Intel, es posible que necesites un kernel reciente para obtener estadísticas por proceso.
En equipos mixtos, suelo ver que la gente ejecuta nvtop junto a nvidia-smi o AMD SMI. Es una combinación sencilla que elimina muchas suposiciones, así que la recomiendo sin dudarlo.
¡No descuides la elección del hardware!
La monitorización no elimina el límite de VRAM; solo lo hace visible. Si todavía estás asignando cargas de trabajo a distintos niveles de GPU, nuestra guía sobre Las mejores GPU para machine learning en 2025 es un buen complemento, ya que trata la VRAM y el ancho de banda de la misma forma en que los verás después en logs y paneles de control.
Una vez que tengas controlado el software de monitorización GPU en servidor, el siguiente paso son los overlays y los frametimes, dado que las cargas interactivas se comportan de forma diferente.
Software de monitorización GPU para gaming y streaming

El gaming es donde la gente tiene opiniones más firmes sobre las herramientas para GPU, sobre todo porque los overlays fallan en el peor momento. Para gaming, lo que necesitas son overlays sencillos y capturas de frametime reproducibles.
MSI Afterburner + RTSS para overlays en Windows
Esta combinación es muy popular porque permite crear un overlay limpio con exactamente las métricas de GPU que te interesan: uso, frecuencias, VRAM, temperaturas, frametime y, si quieres, velocidad del ventilador.
Un aviso importante que aparece con frecuencia en foros y comunidades: hay sitios falsos de descarga. La propia página de Afterburner de MSI advierte que las descargas legítimas deben provenir de msi.com y Guru3D, y también indica la versión actual disponible (4.6.6 final, publicada en octubre de 2025).
Los problemas con los overlays son otro punto a tener en cuenta. Por ejemplo, RTSS funciona en algunos juegos y falla en otros, especialmente con pipelines de renderizado modernos. Hay casos reportados donde el overlay aparece en Vulkan pero no en DX12 para el mismo juego, o desaparece tras las actualizaciones.
Sin embargo, no es un error tuyo, sino lo que ocurre cuando los overlays se enganchan a stacks de juegos y drivers que cambian constantemente.
Si quieres un overlay de referencia estable, mantenlo simple:
- tiempo de fotograma
- Uso de GPU
- VRAM utilizada
- Temperatura de GPU
Añade power y clocks solo si estás depurando activamente throttling.
Captura de frametime para el "stuttering"
Aquí es donde las aplicaciones de monitorización de rendimiento que capturan gráficas de frametime son de gran ayuda. Los FPS medios pueden parecer correctos mientras que el frame pacing se siente fatal. Las gráficas de frametime resuelven esa confusión rápidamente.
Muchos flujos de trabajo de benchmark para juegos usan PresentMon internamente, y NVIDIA documenta que su herramienta FrameView utiliza PresentMon para capturar la tasa de fotogramas y el frametime.
No hace falta hacer benchmark de cada juego. La captura de frametime es más útil para comparaciones: antes y después de una actualización de driver, antes y después de cambiar un limitador, antes y después de modificar ajustes, etcétera.
MangoHud para overlays en Linux
En Linux, MangoHud se recomienda mucho porque es ligero y se integra bien con configuraciones de Steam/Proton. Las quejas más habituales tienen que ver con sensores que faltan o lecturas extrañas en portátiles con gráficos híbridos.
En la práctica, puedes combinar fácilmente MangoHud con un comprobador de terminal como nvtop. También es un buen ejemplo de cómo el software de monitorización de GPU funciona bastante mejor como un stack pequeño, en lugar de una sola aplicación gigantesca.
Desde el gaming, el siguiente paso natural es la monitorización en estaciones de trabajo, porque ahí tus prioridades son los registros y la reproducibilidad de los problemas.
Aloja servidores de juego sin lag con hosting VPS NVMe de alta velocidad.
VPS para gaming
Software de monitorización de GPU para estaciones de trabajo y aplicaciones profesionales
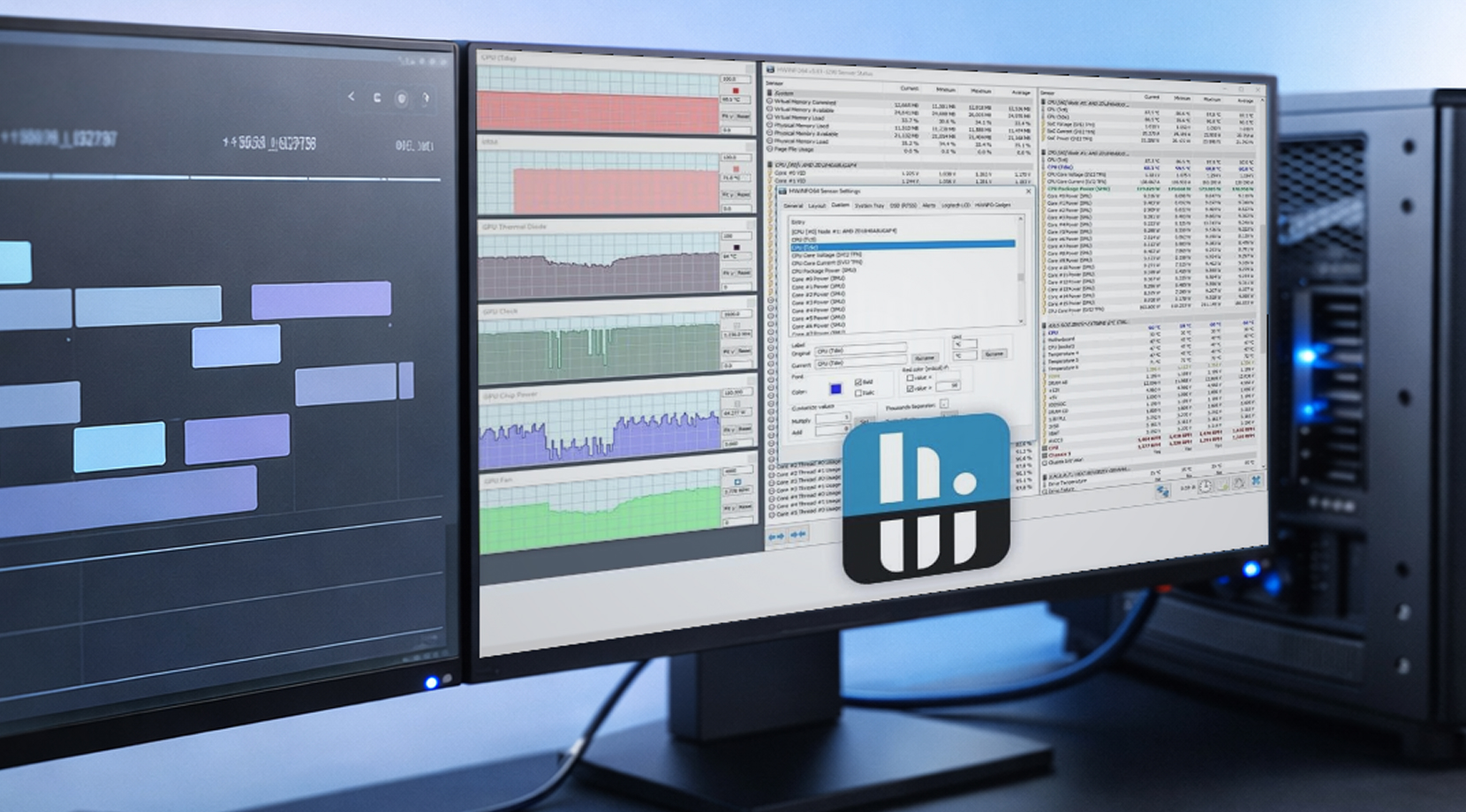
La monitorización en estaciones de trabajo se parece mucho menos a la labor de un vigilante mirando un overlay en tiempo real, y más a responder la pregunta: "¿Qué ocurrió con el tiempo y puedo reproducirlo?"
HWiNFO para registros en Windows
HWiNFO es popular en entornos de estaciones de trabajo porque ofrece una cobertura profunda de sensores y registros fáciles de compartir. Un simple log en CSV con marcas de tiempo puede convertir un informe vago en algo con lo que trabajar activamente para resolver problemas.
Si estás construyendo un log de estación de trabajo para la estabilidad de GPU, empieza con estas métricas de GPU:
- temperatura y punto caliente de GPU
- VRAM utilizada
- potencia de la placa
- frecuencia del núcleo
- potencia del paquete CPU (los límites de potencia de la plataforma pueden darte problemas)
Este es el conjunto de "datos suficientes para explicarlo". Registrar todos los sensores solo hace el archivo más difícil de leer.
GPU-Z para comprobaciones rápidas de "¿qué GPU es esta?"
GPU-Z sigue siendo útil porque es rápido y directo. En equipos con hardware variado, es la forma más rápida de confirmar el modelo de GPU, los datos básicos del controlador y los sensores en tiempo real sin tener que navegar por menús.
Pruebas de estrés: solo útiles con registro activo
Las pruebas de estrés pueden ayudar a reproducir un fallo, pero solo si el software de monitorización de GPU está registrando datos mientras las ejecutas. Sin esos registros, solo tienes "volvió a fallar" y prácticamente ninguna línea de tiempo.
A estas alturas, la mayoría de las personas se topa con los mismos problemas: superposiciones que no aparecen, lecturas de potencia incorrectas y registros ilegibles. Vamos a resolverlos directamente.
Problemas comunes con el software de monitorización de GPU y soluciones rápidas

La mayoría de los problemas siguen unos pocos patrones. Estas son las soluciones que pruebo primero porque resuelven los problemas habituales rápidamente.
Superposición ausente en un juego
Si una superposición desaparece en un título moderno, suele ser un problema de enganche por juego o un conflicto con las capas anti-cheat o anti-tamper.
Lo que puedes hacer y suele funcionar:
- Actualiza RTSS y restablece el perfil por juego
- Establece un "nivel de detección de aplicación" más alto para el perfil del juego
- Prueba un API diferente si el juego lo admite
- Recurre a las superposiciones integradas cuando un título bloquee las de terceros
No todos los juegos van a cooperar, y no vale la pena perder horas con un título que se resiste.
Lecturas de potencia extrañas (0W, líneas planas, sensores ausentes)
Esto aparece mucho en portátiles y configuraciones híbridas donde la GPU activa puede cambiar. En esos casos, verifica los datos con una segunda herramienta, como nvidia-smi (NVIDIA) o AMD SMI (AMD), ya que son buenas comprobaciones de "¿está realmente activa la GPU?".
Registros con demasiado ruido
El sobremuestreo es la causa habitual. Para la mayoría de los diagnósticos, un intervalo de 1 a 5 segundos es suficiente. Para tareas largas de AI, 5 segundos está bien. Los intervalos más cortos disparan el tamaño del archivo y dificultan la lectura de los gráficos.
Una vez cubiertos esos aspectos básicos, la monitorización remota es el siguiente paso lógico, ya que muchos flujos de trabajo con GPU ahora se ejecutan fuera de la máquina local.
Monitorización Remota de GPU y una Opción Práctica en la Nube
El trabajo remoto cambia lo que significa un «buen software de monitorización de GPU». No siempre tienes la máquina delante, así que necesitas comprobaciones rápidas y un historial que puedas revisar más tarde.
Una configuración remota limpia suele tener este aspecto:
- Comprobaciones por CLI (nvidia-smi o AMD SMI)
- un archivo de registro que puedas consultar después
- un exportador o panel de control si necesitas alertas
Si el hardware local está frenando tu progreso (limitaciones de VRAM, compartir una sola GPU entre varios proyectos, necesitar un entorno limpio por proyecto), ejecutar las cargas de trabajo en una GPU VPS suele ser la forma más directa de seguir avanzando.
Cloudzy GPU VPS

Si buscas tiempo de GPU remota para flujos de trabajo de IA, gaming y renderizado, nuestro Cloudzy GPU VPS incluye opciones de NVIDIA como RTX 5090, A100 y RTX 4090, además de almacenamiento NVMe, acceso root completo, conexiones de hasta 40 Gbps, protección DDoS y un objetivo de disponibilidad declarado del 99,95 %.
Desde el punto de vista de la monitorización, se comporta como una máquina normal: puedes ejecutar software de monitorización de GPU vía SSH, registrar métricas de GPU en trabajos largos y añadir paneles de control si quieres historial y alertas.
Si todavía estás decidiendo entre una instancia GPU y una configuración solo con CPU, nuestros artículos sobre ¿Qué es un VPS GPU? y GPU frente a CPU VPS explican las diferencias prácticas según el tipo de carga de trabajo.
Con la monitorización remota ya cubierta, el último paso es reunirlo todo en configuraciones listas para usar.
Configuraciones Listas para Usar por Perfil de Usuario
Aquí tienes configuraciones fáciles de seguir que puedes adoptar sin rehacer todo tu flujo de trabajo. Son un buen punto de partida que luego podrás ajustar a tus necesidades concretas.
- Creador de modelos (AI/ML): Software de monitorización de GPU vía nvidia-smi o AMD SMI, más un registro CSV sencillo, más un exportador o panel de control si los trabajos se ejecutan sin supervisión.
- Jugador competitivo o streamer: Overlay de monitorización de GPU vía Afterburner + RTSS, más una herramienta de captura de frametime para comparativas, más un conjunto mínimo de métricas en pantalla.
- Usuario de estación de trabajo: Software de monitorización de GPU vía HWiNFO con registro, más GPU-Z para comprobaciones rápidas de identidad, más una prueba de estrés solo cuando puedas registrar la ejecución completa.
- Admin ejecutando máquinas GPU: Software de monitorización GPU como servicio: exportador + dashboards + alertas, con visibilidad por proceso (nvtop) para servidores compartidos.
Si solo te quedas con una idea de esta guía, que sea esta: elige el software de monitorización GPU según dónde necesitas los datos (overlay, registro, dashboard), y limita el conjunto de métricas a lo que realmente vas a usar.