
你打开某个热门模型在Hugging Face上的GGUF页面,十五个文件扑面而来:Q4_0、Q4_K_S、Q4_K_M、Q5_K_M、Q6_K、Q8_0,还有GPTQ、AWQ和EXL2各自独立的文件夹,各有六七种比特设置。你随手算了一下「4比特」文件:4比特 × 80亿参数 ÷ 8 = 4GB。可文件却写着4.6GB。而一旦加载它,模型占用的内存还要更多。
文件名不是噪音。它们编码了关于位宽、加载它们的运行时以及所需硬件的真实、可解读的信息。你读过的容量估算表会告诉你一个70B模型大约需要40GB,这很有用,但它们从不解读格式本身,也不解释为什么运行中的模型要比磁盘上的文件占用更多内存。
所以计划是这样的:解读GGUF的命名规则(用真实位宽而非名义位宽)、理清四种格式里你的硬件到底能跑哪一种,并把每个文件大小都看不见的那笔内存开销,也就是KV缓存,算进去。读完之后,你就能看懂一个模型仓库,并预测它加载后的表现。
TL;DR(太长不看版)
- GGUF的量化等级是有效位宽,而不是名称里那个准确数字。Q4_K_M大约是每个权重4.89比特,这就是为什么一个「4比特」的8B文件实际落在约4.6 GiB,而不是天真4比特估算得出的数字。
- GGUF是可移植性最强的选项,因为llama.cpp可以在CPU、GPU或混合配置上运行它。GPTQ、AWQ和EXL2则更依赖特定GPU和运行时,其中EXL2尤其绑定于NVIDIA/CUDA工作流。
- KV缓存与模型权重是分开的,并且会随上下文长度增长。这就是为什么一个能顺利加载的模型,一旦对话变长,仍可能因内存耗尽而崩溃。
- 在5比特以上,质量损失通常很小。在Q4附近,这种权衡对许多本地使用场景仍然实用。低于4比特,质量代价就变得明显得多。Q4_K_M仍是社区常见的默认选择,而当你有富余内存时,Q5_K_M和Q6_K更保险。
GGUF文件名中的Q4_K_M是什么意思?

GGUF量化名称遵循Q[比特数]_[K]_[S/M/L]的格式。数字是 目标 每个权重的比特值,K表示这是一种「K-quant」,会为每个小的权重块存储缩放因子,末尾的S、M或L表示大小/质量档位(小、中、大)。因为K-quant会为每个块连同权重一起存储一个缩放值和最小值, 有效 位宽实际上比标称数字更高。Q4_K_M最终落在大约每个权重4.89比特,而不是4。
这个差距正是「为什么我的4比特文件是4.6GB」这个问题的全部答案。天真的估算假设每个权重恰好花费4比特。实际上,K-quant为每个块额外花费了一些比特用于存储元数据,正是这些让低比特量化保持精确,也就是让运行时能重建每个权重的逐块缩放值和最小值。把4.89比特乘以80亿权重,得到的结果接近4.58 GiB,这才是文件实际的重量。
以下是测得的有效位宽和文件大小,数据取自 llama.cpp quantize documentation ,以Llama 3.1 8B为参考模型,同时附上llama.cpp量化评估论文中测得的各等级困惑度代价(arXiv:2601.14277),测试对象为Llama-3.1-8B-Instruct:
| GGUF等级 | 有效BPW | ~文件大小(8B) | 困惑度对比F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3.4 GiB | +22% |
| Q3_K_M | 3.95 | ~3.7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4.0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4.4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4.6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5.3 GiB | +1.1% |
| Q6_K | 6.56 | ~6.1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8.0 GiB | +0.1% |
| F16 | 16.00 | ~15.0 GiB | 基准 |
*困惑度数字是针对arXiv:2601.14277中Llama-3.1-8B-Instruct测得的。BPW/文件大小这一列和困惑度这一列来自两个分别测量的不同来源,所以请把这张表当作实用的并列参考,而不是单一的一次基准测试。不同任务的性能下降程度不同,数学推理在低位宽下往往比常识推理受损更严重,但总体趋势成立:5比特及以上通常更安全,Q4是实用的压缩区间,而3比特则是质量损失变得难以忽视的临界点。
实际建议:Q4_K_M是大多数人应该选的默认选项,Q5_K_M和Q6_K是有富余内存时偏向质量的选择,而Q3_K_S及以下则是硬件真的容不下更多时的最后手段。
该下载哪种量化格式:GGUF、GPTQ、AWQ还是EXL2?

在四种格式中,GGUF可移植性最强:它可以通过llama.cpp在CPU、GPU或两者混合配置上运行,所以在你不确定硬件能支持什么时,这是最保险的选择。GPTQ、AWQ和EXL2则更依赖特定GPU和运行时。实际上它们在NVIDIA/CUDA配置上最常见,但GPTQ和AWQ的支持情况会因加载器和服务栈而异;比如vLLM 会按硬件和实现方式区分量化支持。如果你是在Mac、AMD显卡或纯CPU机器上本地运行,GGUF仍是最保险的答案。如果你有NVIDIA GPU并想要尽可能快的token速度,另外三种格式就该派上用场了。
| 格式 | 硬件/运行时 | 速度(相对) | VRAM对比同类 | 最适合 |
|---|---|---|---|---|
| GGUF Q4_K_M | 最广泛,通过llama.cpp支持CPU、GPU或混合 | 温和 | 最低 | 任何硬件;本地默认选择 |
| GPTQ 4比特 | 通常以CUDA/GPU为主;取决于运行时 | 快(ExLlama) | 中 | 以GPU为主,较旧的工具链 |
| AWQ 4比特 | 通常以CUDA/GPU为主;取决于运行时 | 快速 | 最高 | vLLM/TGI服务,加载快 |
| EXL2 ~4.9 bpw | 以NVIDIA/CUDA为主 | 最快的 | 低-中等 | 在NVIDIA上速度最快 |
关于这张表的一点说明:速度和VRAM排名来自 oobabooga基准测试,测试时使用的是2023/2024年代的硬件。请把 相对 视为持久的相对排序。EXL2为速度而生,AWQ用VRAM换取快速加载,GGUF保持精简和可移植,但不要把最初那些绝对的每秒token数当作现状。2026年的GPU会给出完全不同的原始吞吐量;真正延续下来的是这个相对排序。
由此得出的决策规则是:如果你有NVIDIA显卡且最看重速度,选EXL2;如果你想要在不同硬件上都最保险的本地默认选择,选GGUF。AWQ和GPTQ主要在特定服务栈(vLLM、TGI)或现有工具链把你推向那个方向时才重要。
为什么本地LLM占用的内存比文件本身还多?
文件大小只是模型权重。运行时你还要为KV缓存(上下文窗口中每个token的注意力状态)、激活值(前向传播的中间计算)以及框架和驱动开销付出代价。对单用户配置来说,这些非权重部分加在一起通常会在权重基础上再增加10%到20%,而一旦上下文变长,光是KV缓存就能压倒一切。一个4.6GB的文件运行起来可能需要远超4.6GB的内存。
可以把运行时内存想象成四个叠加在一起的组成部分:
- 模型权重。 就是你下载的那个文件。这是加载前唯一可见的部分。
- KV缓存。 上下文窗口的注意力状态。上下文短时很小,上下文长时会变得巨大。这正是下一节的主题,因为它最让人意外。
- 激活值。 前向传播的工作内存。对于单流本地推理(批大小为1)来说,这部分很小,通常只有几百兆字节。
- 框架开销。 运行时本身的占用加上GPU驱动的上下文。对于轻量级本地运行时,这部分相对模型权重和KV缓存来说可能很小;更重的服务框架可能预留得多得多。操作系统自身的内存预留则在此之外,又是另外单独的一块。
权重和框架开销是可预测的。KV缓存才是那个把「装得下」的模型变成「会崩溃」的模型的变量,所以有必要把实际的数学算清楚。
KV缓存占用多少内存?
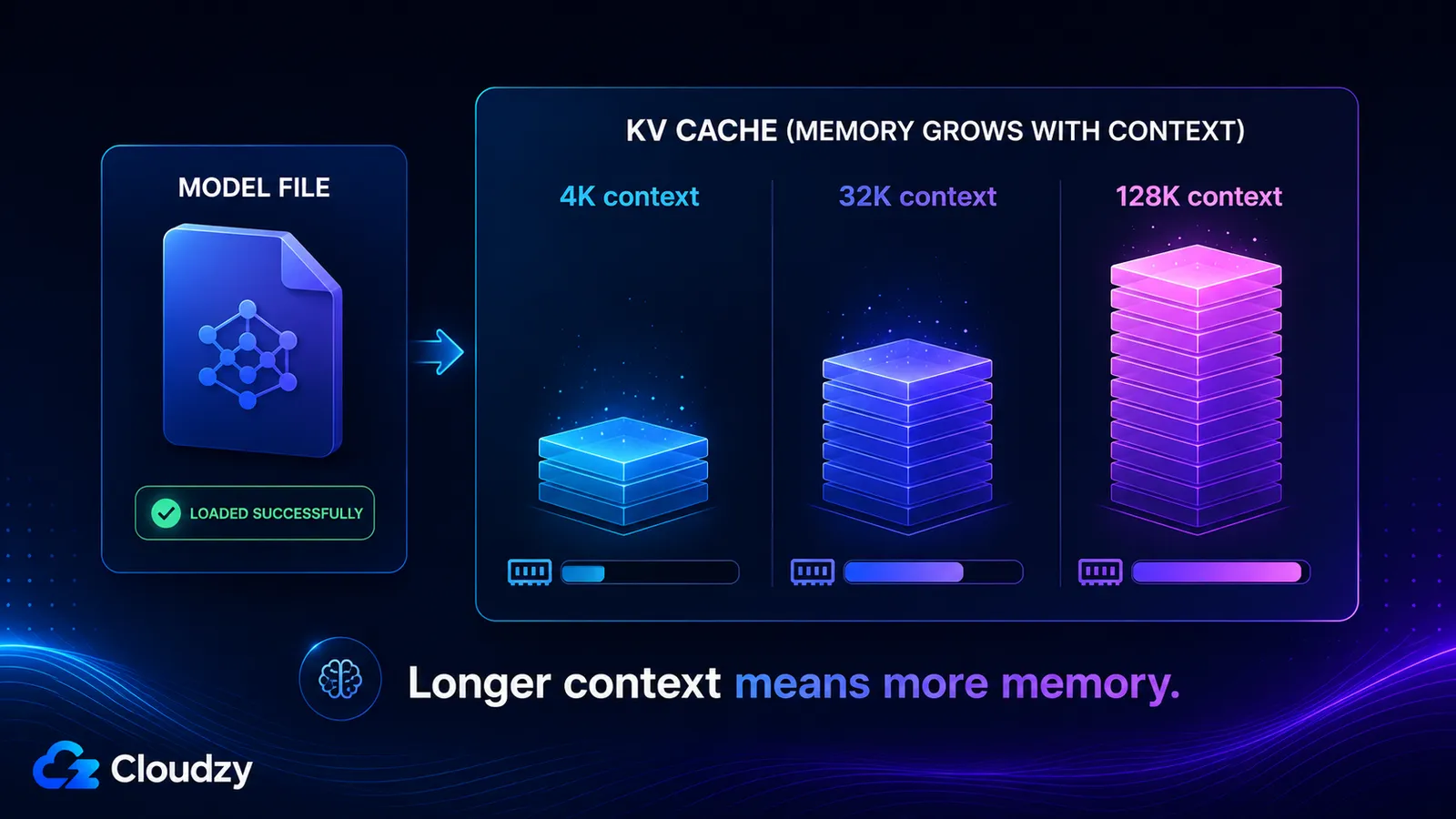
KV缓存为你上下文窗口中的每个token存储键向量和值向量,所以它的大小大致随上下文长度线性增长,并且与模型权重完全分开。它的大小由模型的层数、KV头数、头维度、上下文长度以及缓存精度共同决定。开启长上下文后,你可能会凭空多出几十GB,而一个顺利加载的模型对此从未给过任何警告。
这个公式短到可以直接记在脑子里:
KV缓存字节数 = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
开头的2代表每个token存储两个张量,一个是键,一个是值。对于FP16缓存,bytes_per_element是2。其余的都是可以从模型卡上直接读到的架构常数。
以Llama 3.1 8B为例计算一下,它有32层、8个KV头、头维度为128。在4096 token上下文、批大小为1、FP16缓存的情况下:
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
把上下文调大,这个数字也会跟着变大,因为除了context_tokens之外的每一项都是固定的:
- 4K上下文: ~536 MB
- 32K上下文: ~4.3 GB
- 128K上下文: ~17 GB
最后这两个数字解释了为什么一个模型可以宣称拥有128K上下文窗口,顺利加载,却在你真正用到那个窗口的瞬间耗尽内存。满上下文时的KV缓存,比量化后的权重本身还要大。
以下这一点正是现代长上下文模型之所以可行的关键:Llama 3.1 8B使用了 Grouped Query Attention (GQA)它有32个查询头,但只有8个KV头,缓存只为8个头存储键/值向量,而不是32个。如果用32个KV头(旧的多头注意力设计,KV头数等于查询头数)套用同样的公式,上面每个数字都会乘以4。128K时的17GB就会变成68GB。GQA正是在上下文窗口不断增长的同时,让这道数学题依然可以承受的架构原因。
文件大小不是你的内存预算。当权重或KV缓存装不进快速内存路径,运行时不得不退回到通过PCIe访问系统RAM时,吞吐量不会平缓下降,而是断崖式下跌,因为此时每个token都要通过PCIe搬运数据。做内存预算时,要确保权重和你实际使用的上下文长度下的KV缓存都能装下,而不只是权重。
该如何为你的GPU或Mac选择量化版本?
从你的硬件和运行时出发。NVIDIA GPU用户选择最多,应该在追求原始速度的EXL2和追求可移植性的GGUF之间权衡。如果你用的是AMD、Apple Silicon、纯CPU硬件或混合配置,通过llama.cpp使用GGUF通常是最保险的起点。在此基础上,按你实际会用到的上下文长度(而不是模型的最大值)预留好KV缓存的预算之后,选择能装得下的最高量化等级。
有一个值得了解的Apple Silicon陷阱:GPU并不能拿到你全部的统一内存(关于这个共享内存池具体如何运作的完整说明,请参阅我们关于 什么是统一内存 的姊妹文章)。自托管社区 记录到大约75%的上限 已经记录到GPU实际能拿到的统一内存总量存在大约75%的上限(苹果官方并未确认这一点,而且可能随macOS更新而变化)。所以一台「64GB Mac」现实中大约只有48GB可用于模型加其KV缓存,请按这个较小的数字来规划。
这篇文章讲的是如何解读格式并预测其运行时表现:解读量化名称、选择你硬件支持的格式,以及把KV缓存与权重分开做预算。至于把某个具体模型匹配到具体内存量,也就是那张大小到内存的对照表,这是一个相关但独立的问题,我们会在未来的姊妹文章中讨论。
读懂仓库
现在你可以直接读懂一个模型页面,而不用靠猜。把量化名称解读成它的有效位宽,认清GGUF是最广泛的本地格式,而GPTQ、AWQ和EXL2更依赖特定运行时,并记住文件大小只是下限,KV缓存会叠加在上面,并随你的上下文增长。打开你想要的模型的文件列表,选择你硬件能跑的格式,在为你实际使用的上下文长度预留出KV缓存空间之后,选出能装得下的最高量化等级,你就能避免那个引出这整个问题的内存耗尽崩溃。
常见问题
Q4_K_M是什么意思?
Q4_K_M是一种GGUF量化等级:大约每个权重4比特(Q4),使用逐块缩放的K-quant方式(K),处于中等大小/质量档位(M)。它的 有效 有效位宽大约是每个权重4.89比特,而不是正好4比特,因为K-quant要为每个权重块存储一个缩放值和最小值。这就是为什么一个「4比特」的8B模型文件大约是4.6GB,而不是3.5GB。
量化会降低LLM质量吗?
会,但代价大小很大程度上取决于你压缩到什么程度。在arXiv:2601.14277测得的Llama-3.1-8B-Instruct上,Q6_K的困惑度只上升约0.4%,整个Q5档位都维持在接近1%。降到Q4,增幅依然温和(百分之几);低于Q3_K_M时则陡然攀升,在Q3_K_S达到+22%。对大多数用途来说,Q4_K_M及以上基本可以视为无损;陡峭的代价出现在3比特及以下。
GGUF、GPTQ、AWQ和EXL2之间有什么区别?
GGUF(由llama.cpp运行)是可移植格式,能在CPU、GPU或混合配置的广泛硬件上运行。GPTQ、AWQ和EXL2则更依赖特定GPU和运行时。在4比特这一档,这四种格式的质量都能落在一个较窄的区间内,所以实际差异体现在硬件、加载器支持、速度和VRAM占用上:EXL2是专注速度的NVIDIA/CUDA之选,AWQ在服务栈中很常见,GPTQ适配较旧的GPU工具链和模型仓库,而GGUF仍是可移植性最强的本地选项。
为什么我的本地LLM占用的内存比文件更多?
文件大小只是模型权重。运行时你还要为KV缓存(上下文窗口中每个token的注意力状态)、激活值以及框架加驱动开销付出代价。当差距很大时,通常是KV缓存在作祟,因为它会随上下文长度增长,并且是与权重分开分配的,一个文件只有几GB的模型,一旦你设置了长上下文,可能需要远超此数的内存。
上下文长度如何影响内存使用?
KV缓存大致随上下文长度线性增长,所以上下文翻倍,缓存也大致翻倍。对Llama 3.1 8B来说,在4K token时缓存约为536MB,32K时约为4.3GB,128K时约为17GB(FP16,单流)。这种增长与模型权重完全无关,这就是为什么声明一个长上下文窗口会把一个明明加载正常的模型推向内存耗尽。


