
在一个运行中的 agent 里把 GPT-5 换成 Claude,大多数情况下几乎什么都不会变。改变它处理重试的方式、你向上下文窗口喂入的内容,或者它决定停止的时机——整个 agent 的行为就会截然不同。这个差距说明了一切:模型是一个运行中 agent 最小、最容易替换的部分。真正有趣的工程在于包裹它的一切。
这个 wrapper 现在有了名字。从业者将「harness」这个词确定为那个把文本生成器变成能够随时间推移执行动作(而非运行固定脚本)的东西的层。这个术语在 2026 年初迅速在 Twitter 和工程博客上传播,这也意味着它被宽泛地使用——同一个词在你读到的每篇文章里做着略微不同的事。本文给出精确定义:harness 是什么、由什么构成、与「framework」和「scaffold」有何区别,以及为什么你的 agent 质量大部分藏在 harness 里而不是模型里。
简短版本
- Agent harness 是围绕 LLM 的软件,负责管理执行循环、工具、内存、上下文、状态、错误处理和安全护栏。 模型负责生成文本;harness 决定模型看到什么、能做什么、何时停止,以及出现故障时如何处理。
- 在生产环境中,模型调用往往是系统表面积中最小的可见部分。在构建良好的 harness 中,一个较弱的模型可以胜过在粗糙 harness 中运行的更强模型,尤其是在长时间运行、工具密集的任务中。
- 一个 harness 大约有九到十一个反复出现的组件。其中大多数是模型从不直接接触的部分。
- "Harness" 和 "framework" 不是一回事。framework(LangGraph、agents SDK)是你用来构建的库;harness 是那个库帮你组装起来的运行层。
什么是 Agent Harness?
Agent harness 是围绕语言模型的软件基础设施,负责管理执行循环、工具访问、内存、上下文、状态持久化、错误处理和安全护栏。模型负责生成文本。Harness 决定模型在每一轮看到什么、可以采取哪些行动、何时停止,以及某个步骤失败时如何处理。
最简洁的表述来自 LangChain,他们将其简化为一个等式: Agent = Model + Harness. 模型提供智能。而 harness 则让这种智能在现实世界中真正发挥作用。
"Harness 是所有不属于模型本身的代码、配置和执行逻辑。"
—— LangChain, Agent Harness 的结构剖析
我发现通过一个问题最容易感受到这条边界:当你的 agent 做出错误的事情时,是模型自身的推理出了问题,还是周围的系统给了模型错误的上下文、错误的工具,或者没有任何恢复途径?在真实系统中,大多数情况下是第二种。模型在糟糕的输入上推理得很好。Harness 控制的是输入。
核心要点: 模型负责生成,harness 负责治理。这种划分就是整个概念的核心。
Agent Harness 的组成部分有哪些?
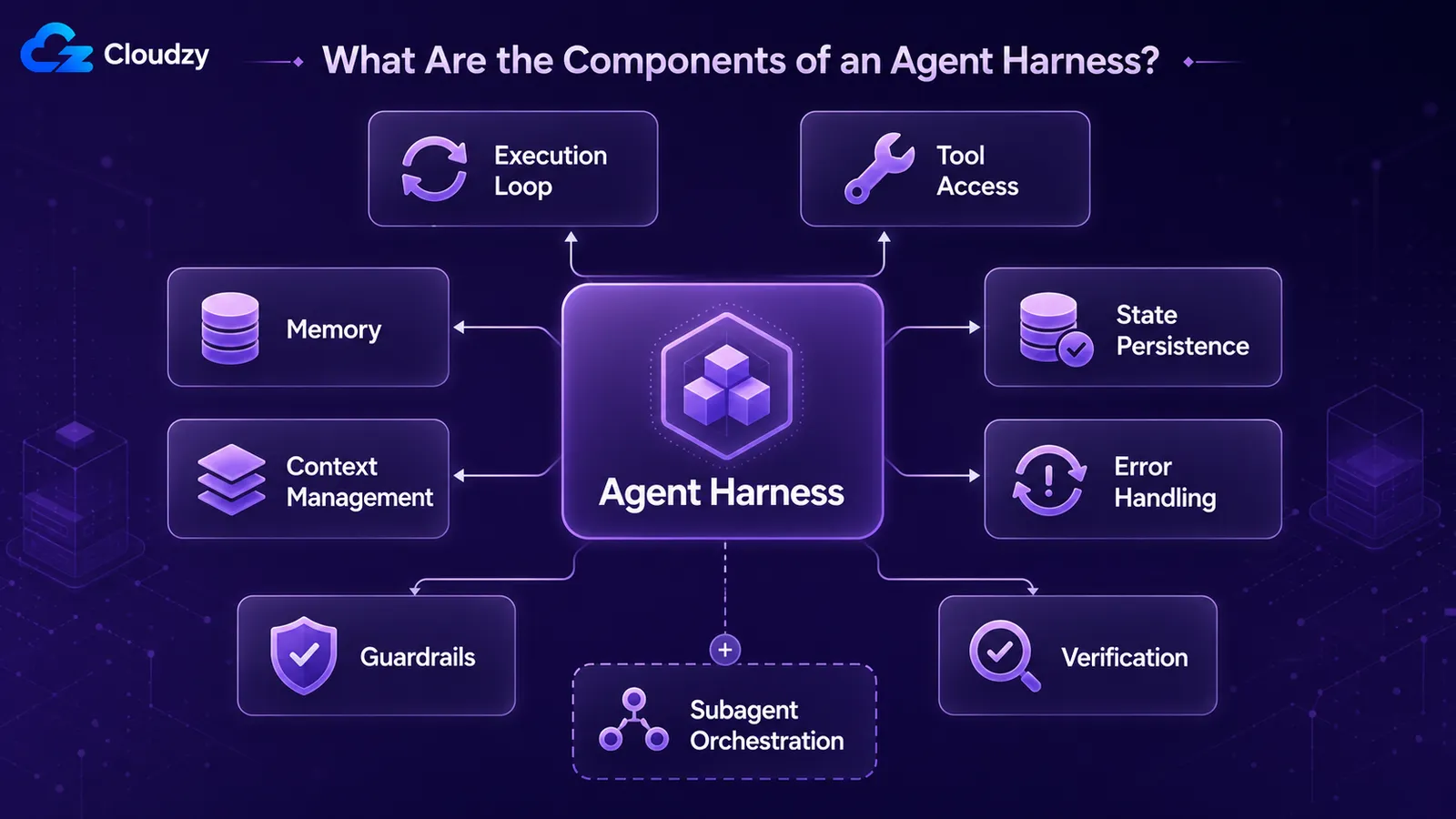
每个 production harness 都由相同的重复组件构成:逐轮驱动模型的执行循环、允许其采取行动的工具访问、跨轮次的记忆、针对当前所见的上下文管理、让工作在会话间持久存在的状态持久化、处理失败步骤的错误处理,以及约束其行为的护栏。生产系统还会加入验证循环和子 agent 编排。
一份实用清单,来源于从业者对真实系统的描述方式:
- 执行/控制循环: 驱动 agent 逐轮运行的机制。调用模型,读取输出,执行所请求的工具,将结果反馈回去,重复直到满足停止条件。
- Tool 访问: 模型可以调用的函数、API、代码执行环境和文件系统。
- Memory: agent 在多轮和多个会话之间保留的内容。
- 上下文管理: 每轮打包进模型窗口的内容,以及溢出时被压缩移除的内容。
- 状态持久化 / checkpointing: 保存 agent 的状态,使崩溃或暂停的运行能够恢复。
- 错误处理: tool 调用或模型调用失败时的重试、降级和恢复机制。
- 护栏: 对 agent 可执行操作的限制,例如允许的工具、步骤上限和输出验证。
- 验证循环: 由 agent(或 harness)在宣告完成之前检查自身的工作。
- 子 agent 编排: 在较大任务中创建 sub-agent、向其委派任务并收集结果。
并非所有这些都是通用的。执行循环、工具、上下文处理和错误处理甚至在周末原型中也会出现。状态持久化、验证和 sub-agent 编排是原型与生产系统分道扬镳的地方。原型可以跳过它们,但长期运行的生产 agent 不能。Anthropic 关于 长期运行的 agent 是对仅限生产环境部分的介绍:agent 在上下文窗口重置后如何从进度文件重建其理解,以及测试如何被纳入循环。
对于想要学术桥梁的人,近期一篇 agent 架构综述 将同样的机制折叠成更小的核心组件形式元组。从业者列表和综述的框架是同一结构的两个缩放级别:综述压缩,上面的清单展开。将九到十一的数量视为大多数生产 harness 共享的组件,而非经过批准的标准,该领域尚未批准任何内容。
核心要点: agent 的大部分运动部件存在于 harness 中,而非模型中。模型只是众多组件之一。
为什么 Harness 比模型更重要?
在设计精良的 harness 中,较弱的模型常常优于设计粗糙的 harness 中的较强模型。原因是机械性的,而非神奇的:agent 的端到端可靠性是每个步骤可靠性的乘积,而大多数步骤(工具选择、上下文组装、错误恢复)是 harness 的职责,而非模型的职责。改进这些步骤,无论内部使用哪个模型,整条链路都会变得更可靠。
数学让这一点变得具体。假设一个十步任务中每个步骤的成功率为 99%。端到端的成功率不是 99%,而是 0.99 的十次方,约为 90%。将每个步骤提升到 99.9%,端到端成功率就会跃升至约 99%。每步可靠性是复利效应,而每步可靠性绝大部分是 harness 的属性。这就是为什么优化错误处理和上下文管理比换用一个在某个基准上高出半分的模型更有价值。
生产环境中也有指向同一方向的信号。 MongoDB 援引 Vercel 的案例研究, 报告称 Vercel 削减了其 agent 的大部分工具,在同一模型上、使用更小更简洁的 harness 后,成功率显著提升。将其视为收敛性证据而非确凿证明:这是一个生产案例,而非受控实验,但它与上述复利运算和调研结论指向同一方向。
这是我作为平台工程师反复回归的启发式原则:context 是瓶颈,而不是模型的原始能力;为掩盖当今模型缺陷而搭建的脚手架,往往会随着模型进步而被淘汰。构建 harness 中经久耐用的部分(循环、状态、恢复),让底层模型按自己的节奏进步。
核心要点: 当你的 agent 出现故障时,先怀疑 harness,再怀疑模型。概率站在这一侧。
Harness、Scaffold 和 Framework 有什么区别?
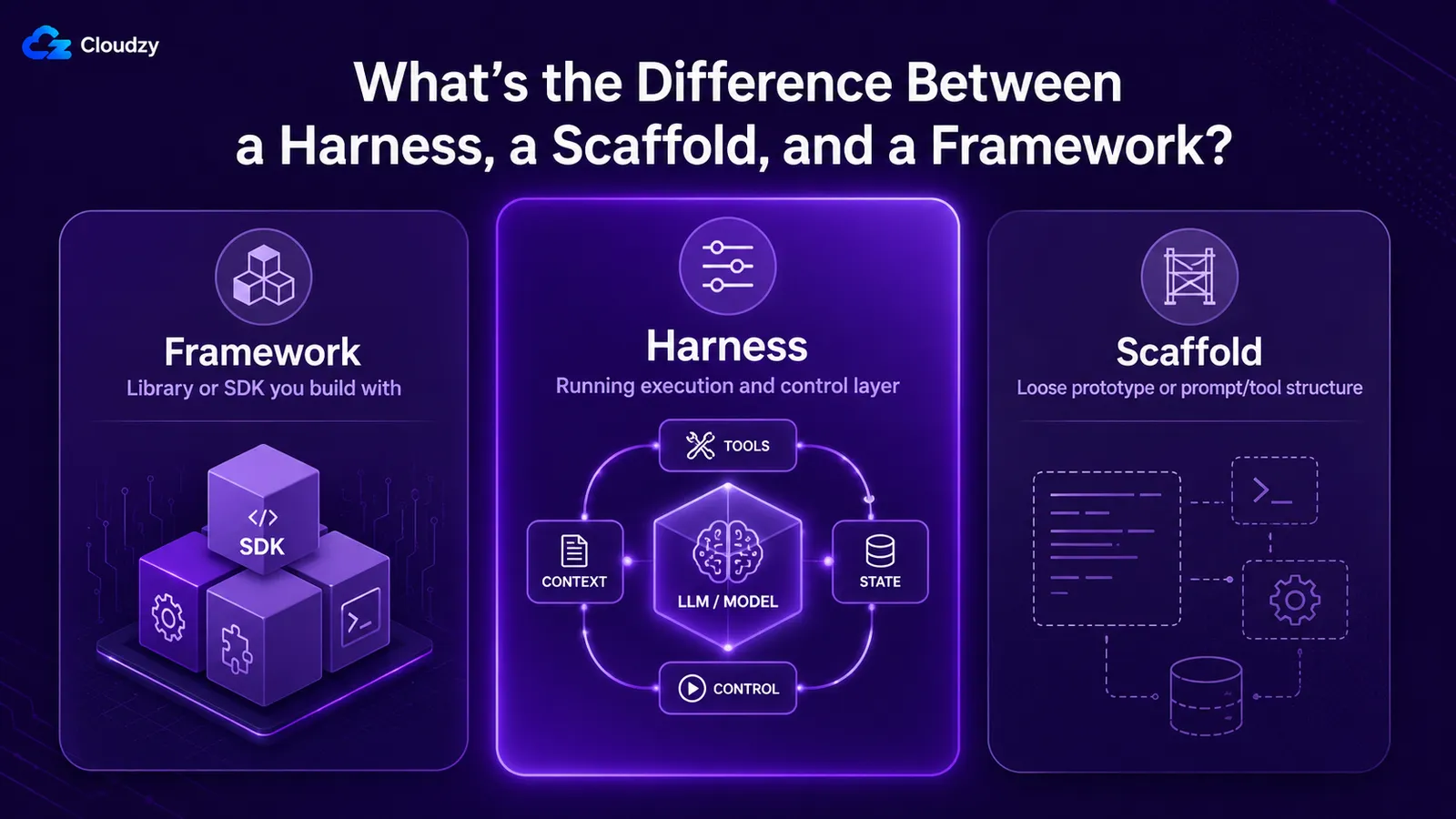
这三个术语经常被混用,但它们不应该混用。A framework 是您用于构建的库或 SDK,例如 LangGraph 或 agents SDK。A harness 是围绕模型运行的执行与治理层,framework 帮助您将其组装起来。A scaffold 是三者中最宽泛的:有时几乎是 harness 的同义词,有时是其原型版本,有时特指 prompt 和工具描述层。
这套词汇确实尚未定型,最清晰的做法是梳理各种用法,而非强行规定一种。HuggingFace 的 Agent 术语表 直接说明了这一点:
"这些术语中有很多还没有被普遍接受的定义,不同的 framework 对同一个词的使用方式也各不相同。"
——HuggingFace, Agent 术语表
| 术语 | 所指内容 | 关系 |
|---|---|---|
| Framework | 你用来构建的库或 SDK(LangGraph、一个 agents SDK) | 用于组装 harness 的工具 |
| Harness | 围绕模型的运行层:循环、工具、上下文、状态、guardrails | 你发布和运行的内容 |
| Scaffold | 泛指:harness 的近义词,或原型级别 / prompt 层版本 | 与 harness 有重叠;精确度较低 |
| 循环 | harness 内部的执行周期 | harness 的一个组件 |
对自己系统进行推理的实用结论:当有人说「framework」时,询问他们指的是库还是正在运行的东西。当有人说「scaffold」时,询问他们指的是整个 harness 还是仅仅是 prompt-and-tool 层。这里的价值在于消除歧义,而非对最终答案提出主张。
LangGraph 如何实现 Harness 模式?
LangGraph 是 harness 模式的一个流行的开源 Python 实现。它将 agent 执行建模为节点和边的有向图,类型化的状态在它们之间流动,每个转换都可以做 checkpoint。如果上面的抽象组件感觉难以捉摸,LangGraph 是一个可以在真实工具中看到它们具体形态的地方。
这种映射接近一对一。node 和 edge 是执行循环:每个 node 做工作,每个 edge 决定控制权下一步去哪里。在 node 之间传递的 typed state object 是明确化的 context-and-state 组件。Checkpointing(LangGraph 通过 saver 持久化 state 比如其 Postgres 支持的实现) 是 state-persistence 组件。可配置的步骤限制是一个停止条件 guardrail,防止行为异常的 agent 永远循环。相同的组件,由特定的库命名和连接。
如果你想在自己的服务器上全天候运行 LangGraph agent,这是一个部署问题而不是概念问题。请参阅 我们的 Linux VPS 指南 适用于该路径。这里,LangGraph 只是一个具体示例:证明「execution loop」、「state persistence」和「guardrail」不是抽象概念——它们是你可以在真实代码中指出来的东西。
常见问题
什么是 Agent Harness?
agent harness 是围绕 language model 的软件,将其变成一个 agent。它管理 execution loop、工具访问、内存、context、state persistence、错误处理和 guardrail。模型生成文本;harness 决定模型看到什么、可以做什么、何时停止,以及当出现故障时会发生什么。
Agent Harness 和 Agent Framework 是同一回事吗?
不是。Framework 是你用来构建的库或 SDK,例如 LangGraph 或 agents SDK。Harness 是围绕模型运行的执行与治理层(循环、工具、上下文、状态和护栏),framework 帮助你将其组装起来。你使用 framework 来构建 harness。
每个 Agent Harness 都有哪些组件?
大多数 harness 共享一个反复出现的核心:执行循环、工具访问、内存、上下文管理、状态持久化、错误处理和护栏。生产级 harness 还会加入验证循环和子代理编排。原型可以跳过仅用于生产的部分,但循环、工具、上下文处理和错误处理几乎无处不在。
"LLM 是你的 Agent 系统中最小的部分" 是什么意思?
这意味着 agent 大部分的行为和可靠性来自 harness,而不是模型。端到端可靠性是每个步骤成功率的乘积,而大多数步骤都是 harness 的工作。MongoDB 引用 Vercel 的案例研究,报告了仅通过 harness 更改就实现了成功率提升,而使用的是同一个模型。这证明修复 harness 的效果优于修复模型。
你的 Agent 质量在哪里
Harness 是 agent 大部分质量所在之处,而现在你已经掌握了在自己的系统中定位问题的词汇。你可以定义 harness,命名其组件,将其与 framework 和 scaffold 区分开来,并判断某个特定的失败是模型问题还是 harness 问题。
所以下次你的 agent 出现问题时,先审查 harness 层:你提供给它的上下文、你暴露的工具、你设置的停止条件,以及它从失败步骤中恢复的方式。只有在那一层检查通过之后,才考虑换用更大的模型。大多数时候,你不需要那样做。


