
快速迭代、按需付费、交给别人打补丁,这套说辞依然很有市场。但当天文数字的存储账单袭来,或一个疏忽的 S3 策略让数据桶敞开大门时,蜜月就结束了。从实战经验看,云计算的大多数问题在各个技术栈和行业都会出现。提前识别它们,我们就能避免大部分麻烦,让团队专注于功能开发,而不是疲于灭火。
为什么这些棘手问题总是挥之不去
云服务故障很少源于单一的灾难性 bug。它们来自架构、流程和人员层面累积的小缺陷。在逐一分析之前,先看看这些症状信号,它们表明问题更深层次:
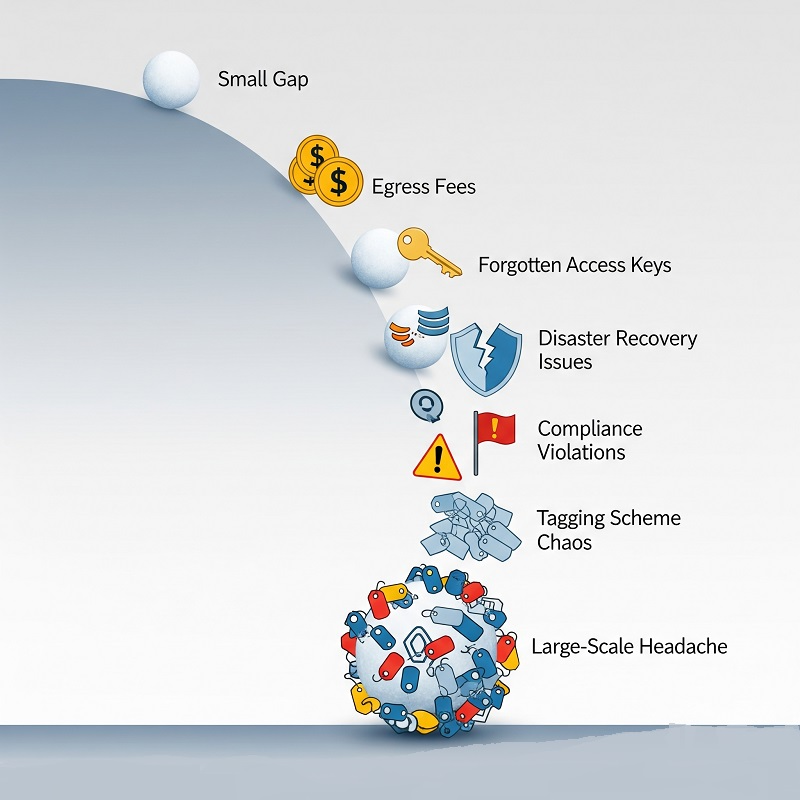
- 出口流量费用突然暴增,吞掉两个月的利润。
- 一把遗忘的访问密钥引发一场隔夜的加密挖矿狂欢。
- 某个地区的大规模故障考验一份从未演练过的灾难恢复计划。
- 合规审计发现存在对象存储中未标记的敏感数据。
- 十个团队各用十套标签方案,成本回收报告看起来像天书。
每个症状都源自一个或多个核心风险类别。把这张风险图谱记牢,后续每一步缓解措施都要参照它。
云计算的风险
行业研究一致表明,七个核心风险类别占据了各个部门大多数事件的根源。虽然这些类别相互交叉,但它们共同描绘出 云计算面临的主要挑战 团队日常遇到的问题,从成本超支到数据泄露:
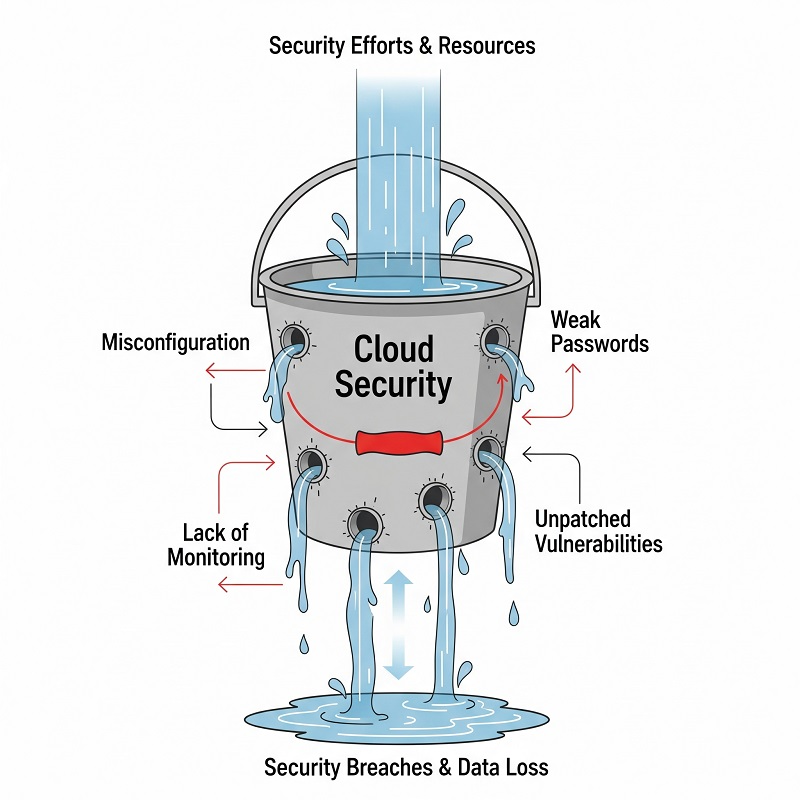
配置错误与过度权限
即使经验丰富的工程师也会偶尔在控制台上操作失误。过于宽松的安全组或公开的存储桶会将内部工具变成互联网上的安全漏洞。
常见的疏漏
- 通配符 0.0.0.0/0 管理端口的规则。
- 迁移完成后仍然授予完全访问权限的 IAM 角色。
数据泄露
一旦配置错误打开了大门,数据就会流向外界。 数据泄露 是云安全中反复出现的问题,且通常不是源于复杂的零日漏洞,而是通过暴露的端点或过期凭证传播。
内部威胁与影子管理员
并非所有风险都来自公司外部。保留权限的合同员工或启动未授权服务的员工会产生标准监控无法发现的盲点。
不安全的 API 与供应链暴露
每个云原生应用都依赖第三方 SDK 和 API。缺少速率限制或未修补的库会引发滥用,将一个无害的功能变成攻击面。
可见性不足与监控盲点
如果日志存储在一个账户中,告警存储在另一个账户中,事件处理会因为团队需要整理上下文而延长。盲点既隐藏性能漂移,也隐藏活动的入侵。
让团队夜不能寐的安全隐患
我们在以下文章中阐述的原则 什么是云安全 提供了坚实的基础,但复杂的攻击者仍然会突破防线,除非公司自动化日志审查、MFA 和最小权限设计。没有这些防护措施, 云计算中的主要安全问题 就会从抽象威胁变成迫在眉睫的危险。 现代 云安全工具 有助于缩短检测时间,但前提是团队将其集成到日常工作流中。
关键要点:
- 绘制每个外部端点的地图,每周扫描一次意外暴露。
- 自动轮换密钥;将长期有效的凭证视为技术债务。
- 将审计日志导入中央 SIEM,然后针对异常情况发出告警,而不是原始错误。
运营和财务风险
高可用听起来很简单,直到多可用区数据库集群让你的账单翻倍。在 云计算面临的主要挑战 成本超支问题往往隐而未显。每当实例族停用或容量限制阻止扩展时,支持工单就会大量积压。
需要精细化控制的团队有时会将对延迟敏感的服务迁移到轻量级 VPS Cloud setup. 通过将工作负载固定到专属 vCPU,他们可以避免邻居噪声问题,同时保持提供商的灵活性。
运维层面的常见云计算问题
- 资源配置不足导致无法应对流量突增。
- 供应商锁定导致数据平面变更缓慢且成本高昂。
- 故障转移测试期间产生了意外的跨区域流量费用。
Go治理与合规陷阱
审计人员有自己的语言习惯,云计算又引入了新的术语。标签、保留期和加密策略一旦偏离标准,审计发现就会迅速增加。下表列举了我在就绪性审查中经常遇到的四个常见问题:
| 合规缺口 | 典型触发器 | 可能性 | 业务影响 |
| 存储在对象存储中的未分类个人数据 | 缺少数据清单 | 中 | 罚款、品牌受损 |
| 高级账户不支持 MFA | 速度优先,流程次之 | 高 | 账户接管 |
| 灾难恢复计划从未测试过 | 资源压力 | 中 | 长时间宕机 |
| 专有功能深度集成 | 构建时的便利性 | 低 | 昂贵的迁出成本,缓慢的数据迁移 |
注意每一行如何对应上面的一个计算挑战。可见性、最小权限原则和可重复测试是任何成功审计周期的基础。
解决痛点
没有完美的解决方案,但分层防御能快速降低风险。我将防御策略分为三类:
- 强化基础设施安全
- 用基础设施即代码为每个账户设定基线;漂移告警能捕捉隐蔽的变更。
- 在身份提供商层面执行 MFA,而不是按应用程序。
- 自动化检测和响应
- 集中日志,然后按资源标签汇总,这样告警能清楚说明 什么 哪里出了问题,而不只是 哪里 它坏了。
- 每周启动沙箱副本来测试补丁集,在生产环境使用前验证。
- 为不可避免的情况做准备
- 运行应急演练:关闭某个服务,观察仪表板如何变化;这样学到的东西比幻灯片讲座更深入。
- 随时准备一个干净、可移植的镜像;一键 购买云服务器 选项可在区域故障时充当安全阀。
先采用适合你栈的部分,然后逐步扩大覆盖范围。自动标签或每日密钥轮换这样的小胜利会随时间复利增长。
结语
云采用持续向上发展,所以忽视其痛点不是选项。通过将你的环境对标本文 云计算面临的主要挑战 描述的内容,你能尽早发现薄弱环节、保持成本可控,让开发者有信心发布功能。这个过程永远不会真正结束,但只要眼光清楚、工具靠谱、定期审查成为习惯,云就会保持作为加速器的角色,而不会变成半夜告警的源头。
速度、一致性和严密的安保已融入 Cloudzy 的 VPS 云产品组合。每个实例搭载 NVMe 存储、高频 CPU 和冗余的一线路由,意味着工作负载启动迅速,即使流量激增也能保持响应灵敏。企业级防火墙、隔离的租户和持续补丁不会降低速度的前提下锁定整个栈。如果你想买一个 云服务器 既满足安全也满足可靠性要求的产品,看这里就够了!


