选择 GPU 或 VPS 时,盯着满是数字的规格表确实容易感到困顿。核心数从 2,560 跳到 21,760,但这究竟意味着什么呢?
CUDA 核心是 NVIDIA GPU 中的并行处理单元,能够同时执行数千次计算,支持从 AI 训练到 3D 渲染的各种任务。本指南讲解 CUDA 核心的工作原理、与 CPU 和张量核心的区别,以及如何选择合适的核心数量而不会过度投入。
什么是 CUDA 核心?

CUDA 核心是 NVIDIA GPU 内部的独立处理单元,能够并行执行指令。CUDA 核心技术的基础是什么?把这些单元看作小型处理器,同时处理同一任务的不同部分。
NVIDIA 在 2006 年推出了 CUDA(统一计算架构),用于将 GPU 的计算能力应用于图形以外的通用计算。 CUDA 官方文档 提供全面的技术细节。每个单元对浮点数执行基本算术运算,非常适合重复计算。
现代 NVIDIA GPU 在单个芯片中集成了数千个这样的单元。最新一代消费级 GPU 包含超过 21,000 个核心,而 基于 Hopper 架构的数据中心 GPUs 配备多达 16,896 个。这些单元通过流式多处理器 (SM) 协同工作。
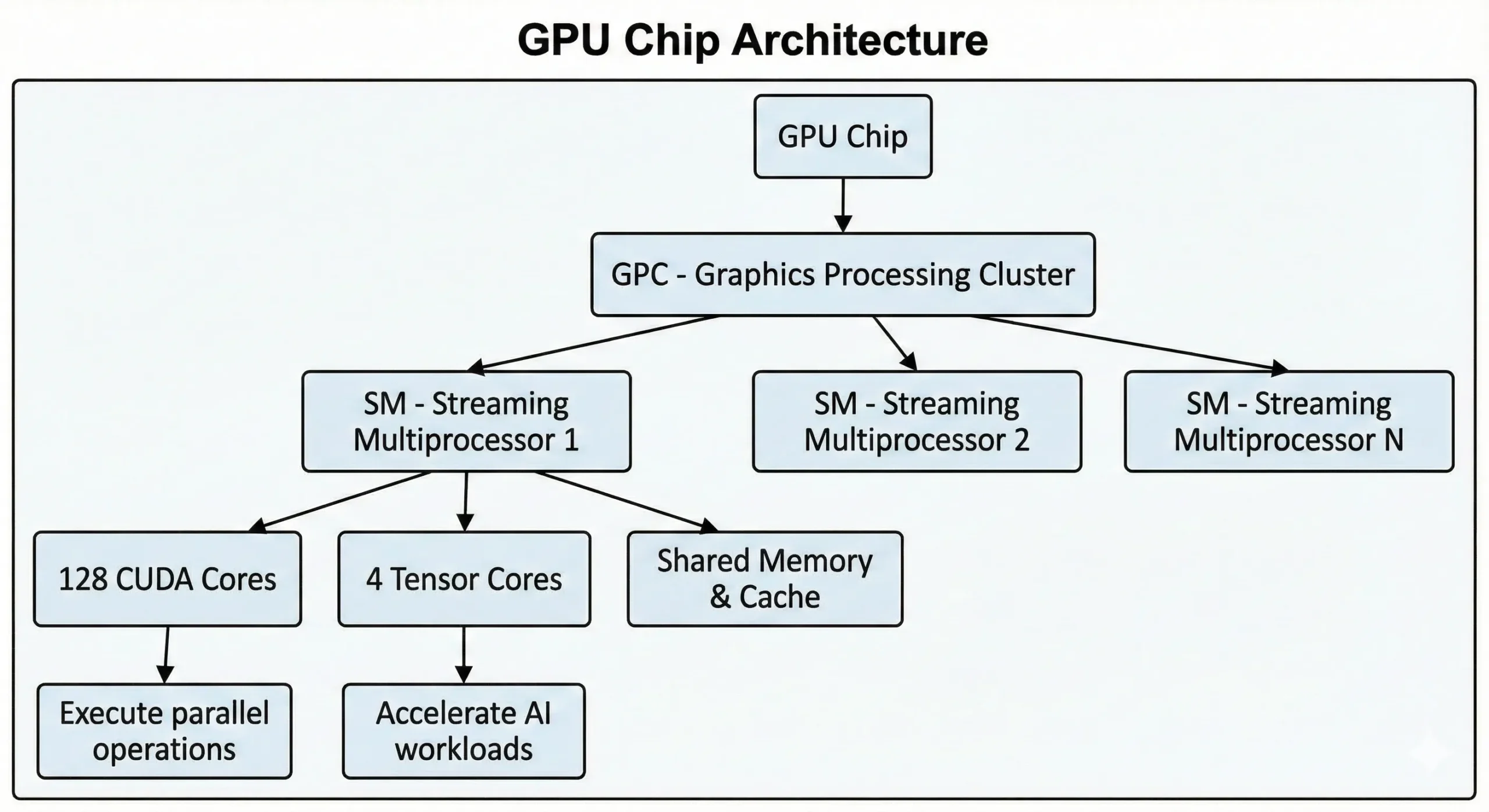
这些单元通过并行计算方法执行 SIMT(单指令多线程)操作。一条指令在众多数据点上同时执行。在训练神经网络或渲染 3D 场景时,数千个类似的操作会并行发生。它们将这些工作分成多个并发流,同时执行而不是按顺序执行。
CUDA 核心 vs CPU 核心:有什么区别?

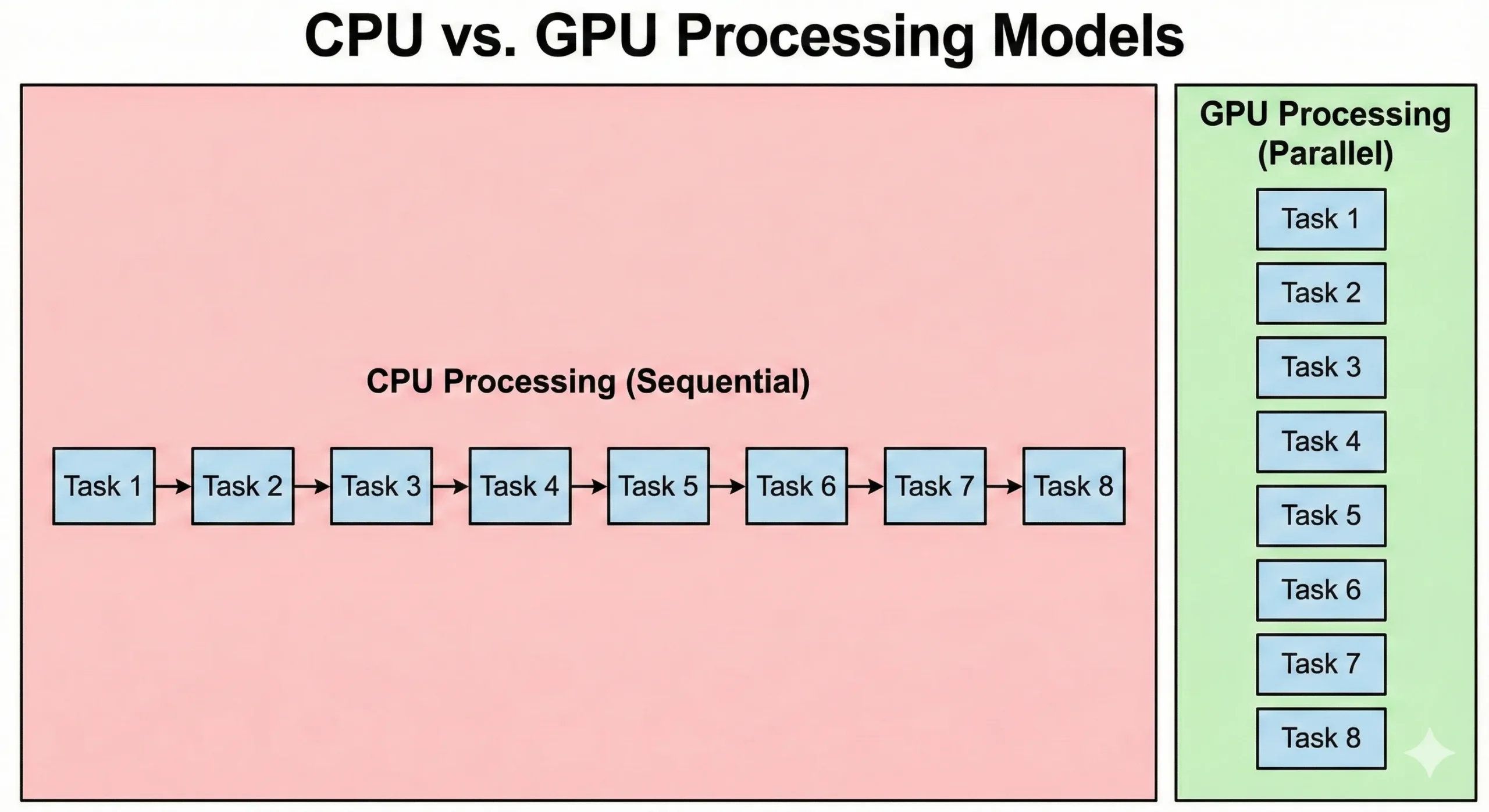
CPUs 和 GPUs 采用本质不同的方式解决问题。现代服务器 CPU 可能搭载 8-128+ 个核心,运行频率较高。这些处理器擅长处理串行操作,其中每一步都依赖于前一步的结果。它们能够高效地处理复杂逻辑和分支判断。
GPUs 采用不同的策略。它们集成数千个低频 CUDA 核心。这些核心通过并行计算来弥补频率不足。当 16,000 个核心协同工作时,总吞吐量超过标准 CPU 的性能。
CPUs 执行操作系统代码和复杂应用逻辑。GPUs 优先考虑吞吐量,但任务初始化和同步的开销导致延迟较高。并行图形处理优先考虑数据移动。虽然启动时间较长,但处理大型数据集的速度比 CPUs 更快。
| 功能 | CPU 核心 | CUDA 核心 |
| 每个芯片的数量 | 4-128+核心 | 2,560-21,760 个核心 |
| 时钟速度 | 3.0-5.5 GHz | 1.4-2.5 GHz |
| 处理方式 | 顺序执行的复杂指令 | 平行处理,简洁指令 |
| 最适合 | 操作系统、单线程任务 | 矩阵运算、并行数据处理 |
| 延迟 | 低(微秒) | 较高(启动开销) |
| 建筑 | 通用 | 专为重复计算优化 |
虚拟 GPU (vGPU) 和多实例 GPU (MIG) 技术负责资源分区和调度,将处理器分配给多个用户。这种配置让团队能够通过时间切片共享或专属硬件实例来最大化硬件利用率,具体取决于你的需求。
训练神经网络需要进行数十亿次矩阵乘法运算。拥有10,000个处理单元的GPU并非简单地同时执行10,000个操作,而是将数千个并行线程分组为"warp"来统一调度,从而最大化吞吐量。正是这种大规模并行处理能力,使GPU成为AI开发者必须深入了解的核心工具。
CUDA 核心 vs 张量核心:了解两者的区别

NVIDIA GPUs 包含两种专用单元协同工作:标准 CUDA 核心和 Tensor 核心。它们不是竞争技术,而是分别处理不同类型的工作负载。
标准单元是通用并行处理器,处理 FP32 和 FP64 计算、整数运算和坐标变换。这项核心 CUDA 技术是 GPU 计算的基础,支持从物理模拟到数据预处理的各种工作负载,无需专用加速器。
张量核心是专门为矩阵运算和AI任务设计的硬件单元。NVIDIA在Volta架构中首次推出(2017年),擅长处理FP16和TF32精度计算。最新一代支持FP8,进一步加快AI推理速度。
| 功能 | CUDA 核心 | Tensor核心 |
| 目的 | 通用并行计算 | AI 矩阵乘法运算 |
| 精度 | FP32、FP64、INT8、INT32 | FP16, FP8, TF32, INT8 |
| 人工智能速度 | 1倍基线性能 | 比 CUDA 核心快 2-10 倍 |
| 使用场景 | 数据预处理、传统机器学习 | 深度学习训练/推理 |
| 可用性 | 所有 NVIDIA GPUs | RTX 20 系列及更新版本,数据中心 GPUs |
现代 GPU 系列集两者之力。RTX 5090 配备 21,760 个标准计算单元和 680 个第五代 Tensor 核心。H100 则搭载 16,896 个标准计算单元与 528 个第四代 Tensor 核心,专为深度学习加速优化。
在训练神经网络时,Tensor 核心在模型的前向和反向传播中承担计算密集的工作。标准单元管理数据加载、预处理、损失计算和优化器更新。两种类型协同工作,Tensor 核心加速计算密集型操作。
随机森林或梯度提升这类传统机器学习算法不涉及张量核心加速的矩阵乘法模式,标准计算单元就能处理。但对于Transformer模型和卷积神经网络,张量核心能提供显著的性能提升。
CUDA 核心有什么用?

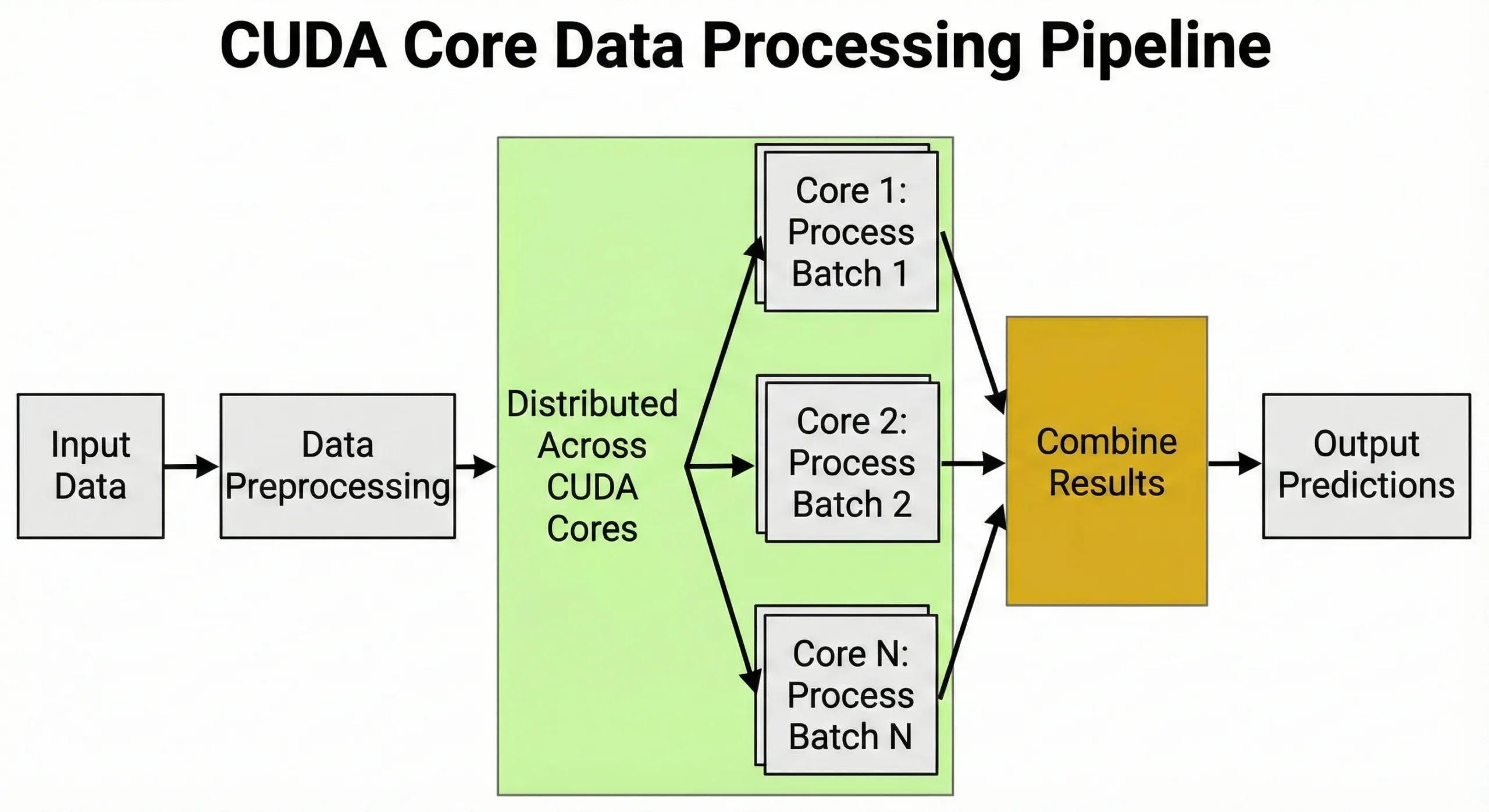
CUDA 核心处理需要大量相同计算同时进行的任务。矩阵运算或重复数值计算都能从其架构中获益。
AI 和机器学习应用
深度学习在训练和推理过程中依赖矩阵乘法。训练神经网络时,每次前向传播都需要在权重矩阵上执行数百万次乘加运算。反向传播在后向过程中又增加了数百万次运算。
单元管理数据预处理,将图像转换为张量、归一化数值并应用增强变换。同时处理数千个任务的能力正是 GPUs 对 AI 如此重要的原因。
在训练过程中,它们管理学习率计划、梯度计算和优化器状态更新。
VPS 用于运行推荐系统或聊天机器人等 AI 推理操作时,能并发处理请求,同时执行数百个预测。我们的指南 AI 2025 最佳选择 GPU 介绍不同模型规模下哪些配置能够正常运行。
H100 的 16,896 个 Tensor 核心可在数周内训练 70 亿参数模型,而非数月。为数千用户提供服务的聊天机器人需要实时推理,这需要相同的并发执行能力。
科学计算与研究
研究人员使用这些处理器进行分子动力学模拟、气候建模和基因组学分析。每次计算都是独立的,非常适合并发执行。金融机构通过这些处理器同时运行数百万个场景的蒙特卡洛模拟。
3D 渲染和视频制作
光线追踪通过追踪穿过每个像素的独立光线来计算光在3D场景中的反弹。专用RT核心处理遍历,而标准单元管理纹理采样和光照计算。这种分工决定了处理数百万条光线场景的速度。
NVENC 处理 H.264 和 H.265 的编码,而最新架构(Ada Lovelace 和 Hopper)增加了 AV1 硬件支持。CUDA 协助处理效果、滤镜、缩放、降噪、色彩转换和管道整合。这样编码引擎可以与并行处理器配合工作,加快视频制作速度。
在 Blender 或 Maya 中进行 3D 渲染时,数十亿次表面着色器计算会分散到可用的处理单元。粒子系统也能获益,因为它们需要同时模拟数千个粒子的相互作用。这些功能对高端数字创意工作至关重要。
CUDA 核心如何影响 GPU 性能

核心数量能让你大致了解并发执行能力,但 CUDA 核心需要你看得更深。时钟速度、内存带宽、架构效率和软件优化都起着重要作用。
一个运行频率为 2.0 GHz 的 GPU(10,000 个单元)和一个运行频率为 1.5 GHz 的(10,000 个单元)的性能表现截然不同。更高的时钟频率意味着每个单元每秒可以完成更多计算。较新的架构通过更优的指令调度,在每个周期内完成更多工作。
检查一下是否让设备处于满载状态,但要记住 nvidia-smi 利用率是一个粗糙的指标。它衡量的是内核活跃的时间百分比,而不是有多少核心在工作。
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheader示例输出:85%、92%(85% 运行时间活跃度,92% 内存控制器活跃度)
如果你的 GPU 显示 60-70% 利用率,很可能是上游存在瓶颈,比如 CPU 数据加载或批处理尺寸过小。不过,即使显示 100% 利用率也可能具有迷惑性,因为你的内核可能受内存限制或单线程限制。要准确了解核心饱和情况,应该用 Nsight Systems 这样的性能分析工具来跟踪 SM Efficiency 或 SM Active 指标。
内存带宽通常会先成为瓶颈,限制计算能力的充分利用。如果 GPU 处理数据的速度超过内存供应速度,计算单元就会闲置。 H100 SXM5 型号使用 3.35 TB/s 的带宽 来驱动其 16,896 个核心。但 PCIe 版本将此降低到 2 TB/s。
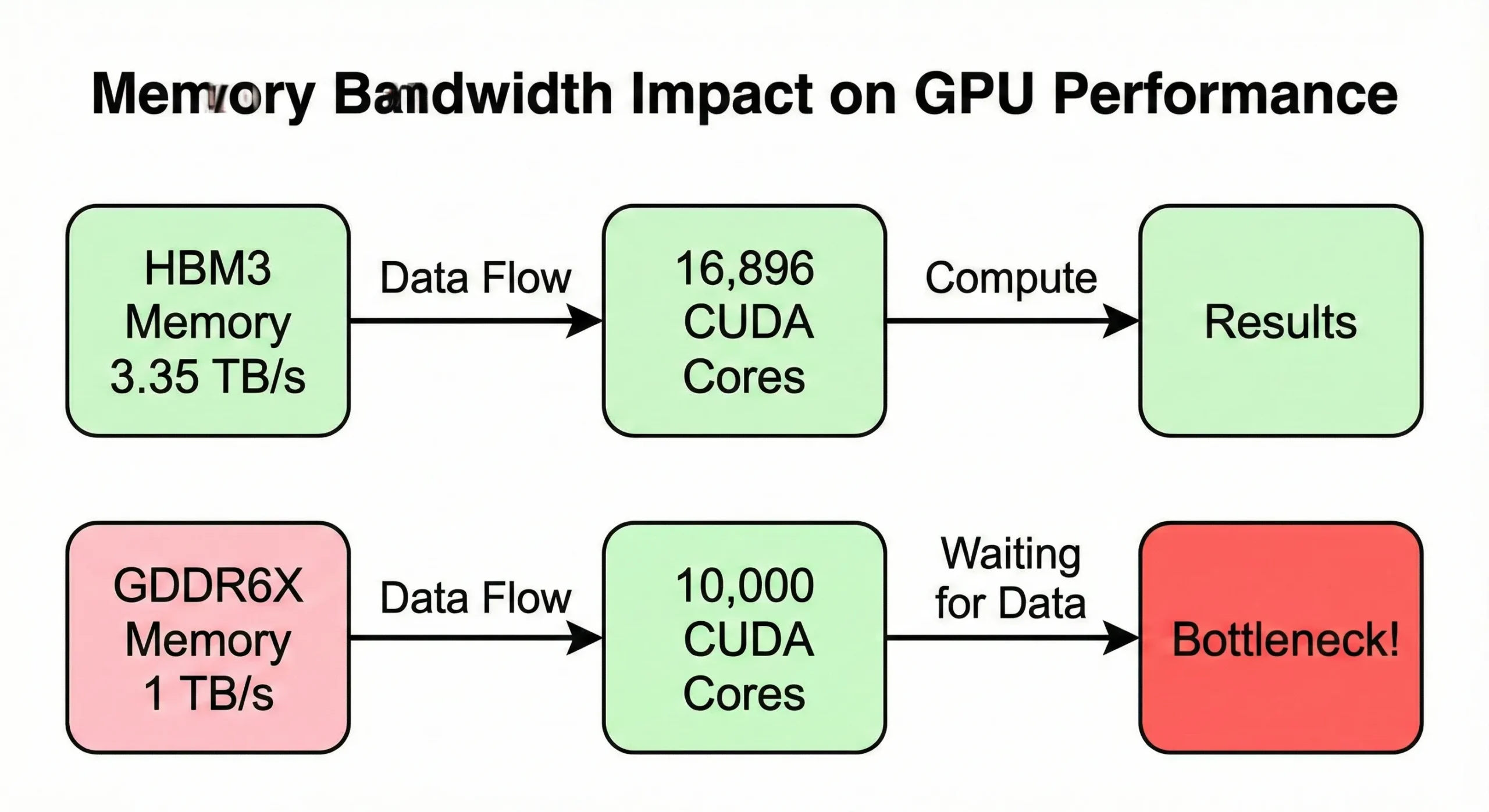
具有相似核心数但带宽较低(约 1 TB/s)的消费级 GPU 在内存密集型操作中表现出较低的实际速度。
VRAM 容量决定了你任务的规模。无论是用于 70B 模型的 FP16 权重,完整训练都需要更多内存。你必须考虑梯度和优化器状态。除非使用卸载策略,这些状态通常会使内存占用增加三倍
A100 80GB 版本针对高吞吐量推理和微调。同时,24GB 的 RTX 4090 虽然常被引用用于 7B 模型,但使用现代量化技术如 INT4,可以意外地运行 30B+ 参数模型。但是,VRAM 溢出会强制执行 CPU-GPU 数据传输,摧毁吞吐量。
软件优化决定了你的代码是否真正使用了所有这些单元。编写不当的内核可能只能使用可用资源的一小部分。深度学习的 cuDNN 和数据科学的 RAPIDS 等库经过大量调优以最大化利用率。
更多 CUDA 核心并不总是意味着更好的性能

购买核心数最高的 GPU 似乎合理,但如果单元超过其他系统组件的速度,或你的任务不会随核心数扩展,就浪费了金钱。
内存带宽造成第一个限制。RTX 5090 的 21,760 个单元由 1,792 GB/s 的内存带宽驱动。较旧的 GPU 单元较少,但每单元的带宽比例可能更高。
架构差异很重要。运行频率为 2.2 GHz 且有 14,000 个单元的较新 GPU 由于更好的每时钟指令性能,优于运行频率为 1.8 GHz 且有 16,000 个单元的较旧 GPU。你的代码需要适当的并行化才能有效地使用 20,000 个单元。
选择 GPU VPS 时为什么 CUDA 核心很重要

为你的 VPS 选择正确的 CUDA 核心 GPU 配置可以防止浪费未使用的资源或在项目中期遇到瓶颈。
H100 的 80GB 内存可以使用 4 位量化处理 70B 参数模型的推理。但对于完整训练,即使 80GB 对于 34B 模型也常常不足,一旦计算梯度和优化器状态。在 FP16 训练中,内存占用会显著扩展,通常需要多 GPU 分片。
为实时预测提供服务的推理操作需要较少单元但受益于低延迟。开发和原型设计工作可以使用中端 GPU 进行算法测试和代码调试。
RTX 4060 Ti 拥有 4,352 个单元,让你在不为过度配置硬件付费的情况下进行测试。一旦验证你的方法,可以升级到生产级 GPU 进行完整训练运行。
渲染和视频工作会随着单元数增加而扩展。Blender 的 Cycles 渲染器有效利用所有可用资源。具有 8,000-10,000 个单元的 GPU 渲染场景速度快 2-3 倍。
在 Cloudzy,我们提供高性能 GPU VPS 托管服务,专为繁重工作打造。选择 RTX 5090 或 RTX 4090 进行快速渲染和经济高效的 AI 推理,或升级到 A100 以处理大规模深度学习工作负载。所有方案运行在 40 Gbps 网络上,采用隐私优先政策和加密货币支付选项,为你提供强大性能,无企业繁琐程序。
无论是训练 AI 模型、渲染 3D 场景还是运行科学模拟,你都可以选择适合你需求的核心数。
预算考虑很重要。具有 6,912 个单元的 A100 成本明显低于具有 16,896 个单元的 H100。对于许多操作,两个 A100 提供比一个 H100 更好的性价比。盈亏平衡点取决于你的代码是否跨多个 GPU 扩展。
如何选择正确数量的 CUDA 核心
根据实际工作负载特点选择配置,而不是盲目追求市场上最高的数字。
先分析你目前的工作负载。如果你在本地硬件或云实例上训练模型,检查 GPU 的利用率指标。如果你现在的 GPU 利用率在 60-70% 之间,说明你还没有充分利用这些资源。
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")这个简单的基准测试可以检验你的 GPU 核心是否达到预期的吞吐量。将你的结果与已发布的 GPU 型号基准进行对比。
升级硬件解决不了根本问题。你需要先解决内存、带宽或 CPU 停顿这些瓶颈。接下来估算内存需求,把模型大小(以字节计)加上激活内存就行。
将批大小乘以层输出数,再加上优化器状态。这个总值必须能放入 VRAM。确定所需内存后,检查哪些 GPU 满足该要求。
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)根据你的时间表来选择。如果你需要几小时内得到结果,就增加计算单元数量。如果训练任务可以等待几天,用较小的 GPU 也能完成,只是耗时会更长。
按小时费率乘以所需小时数得出总成本,有时速度较慢的 GPU 实际上更便宜。使用多个提供基准测试工具的框架来测试扩展效率,这些工具能显示吞吐量的变化。
如果增加两倍的单元只能获得1.5倍的性能提升,额外成本不划算。找到价格与性能比最优的配置点。
| 工作负载类型 | 推荐核心数 | 示例 GPU | 注意事项 |
| 模型开发与调试 | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | 快速迭代,成本更低 |
| 小规模 AI 训练(<7B 参数) | 6,000-10,000 | RTX 4090, L40S | 适合个人用户和小型企业 |
| 大规模 AI 训练(70 亿到 700 亿参数) | 14,000+ | A100, H100 | 需要数据中心 GPUs |
| 实时推理(高吞吐量) | 10,000-16,000 | RTX 5080, L40 | 平衡成本与性能 |
| 3D 渲染和视频编码 | 8,000-12,000 | RTX 4080, RTX 4090 | 随着需求增长而扩展 |
| 科学计算与高性能计算 | 10,000+ | A100, H100 | 需要FP64支持 |
热门 VPS 和 GPU 的 CUDA 核心数量

不同的 GPU 等级服务于不同的用户群体。什么是 GPUaaS?它是 GPU 即服务,由 Cloudzy 这样的提供商提供按需访问权限,让你可以使用强大的 NVIDIA GPUs,无需自己购买和维护物理硬件。
| GPU 型号 | CUDA 核心 | VRAM | 内存带宽 | 建筑 | 最适合 |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1,792 GB/秒 | Blackwell | 旗舰工作站,8K 渲染 |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/秒 | 艾达·洛夫莱斯 | 高性能 AI、4K 渲染 |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3,350 GB/秒 | Hopper | 大规模 AI 训练 |
| H100 PCIe | 14,592 | 80GB HBM2e | 2,000 GB/秒 | Hopper | 企业级 AI,经济高效的数据中心 |
| A100 | 6,912 | 40/80GB HBM2e | 1,555-2,039 GB/秒 | Ampere | 中端 AI,久经考验的可靠性 |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | 艾达·洛夫莱斯 | 游戏、中端 AI |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | 艾达·洛夫莱斯 | 多工作负载数据中心 |
消费级 RTX 显卡(4070、4080、4090、5080、5090)面向创意工作者和游戏玩家,但同样适合 AI 开发。相比数据中心显卡,它们提供更强的单精度浮点性能,价格也更低。
VPS 提供商通常为成本敏感的用户库存这些卡。数据中心卡(A100、H100、L40)优先考虑可靠性、ECC 内存和多 GPU 扩展。它们可以管理 24/7 运营并支持高级功能。
多实例 GPU (MIG) 让你将一块 GPU 分区为多个独立实例。尽管有更新的选项,A100 仍然很受欢迎,因为它的规格配置很均衡。
它在 NVIDIA 核心数、内存和价格之间找到了平衡,是大多数生产环境 AI 应用的稳妥之选。H100 提供的单位数多出 2.4 倍,但成本也显著更高。
结语
并行处理引擎推动了现代 AI、渲染和科学计算的发展。了解它们的工作原理、如何与内存和时钟速度交互,以及软件的影响,能帮助你选择合适的 GPU VPS 配置。
更多核心数在工作能有效并行化、内存带宽等组件跟上节奏时才有帮助。但如果瓶颈出现在其他地方,盲目追求最高核心数只会浪费钱。
从分析实际业务开始,找出时间消耗最多的地方,然后根据这些需求选择 GPU 规格,避免购买不必要的多余容量。
在大多数AI开发工作中,6,000-10,000个单元在成本和性能之间达到最佳平衡。用于生产环境、训练大型模型或处理高吞吐量推理的场景,14,000+个单元的GPU(如H100)会更合适。
渲染和视频处理可以高效扩展至约 16,000 个单位,超过这个数量后内存带宽会成为瓶颈。