
当 NVIDIA 展示 DLSS 4 生成 每十六个像素中的十五个 由 AI 生成时,很大一部分观众并没有看到进步。他们看到的是“假帧”和“AI 废料”:那些看起来没问题、直到出问题为止的生成细节,而且你无法像调试一个放错位置的多边形那样去调试它。PCGuide 关于一项社区投票的报道发现,54% 的回应只是干脆地“否定”了 DLSS 5的画面效果,其中大部分批评针对面部特征以及“AI 废料”这一反应。这种反应值得认真对待,我们稍后会再回到这一点。
但所有这些争论中更大的问题在于,“神经渲染”这个词至少被用于五种不同的事物:超分辨率重建、AI 生成帧、从照片重建场景、你在社交媒体上看到的 NeRF 和 Gaussian Splatting 演示,以及用单个网络渲染整张图像的研究系统。人们各说各话,是因为他们各自指向不同的层级,却使用同一个词。NVIDIA 的黄仁勋称这一转变为“图形的 GPT 时刻”。这是他的说法。真正有用的问题是它背后究竟发生了什么。
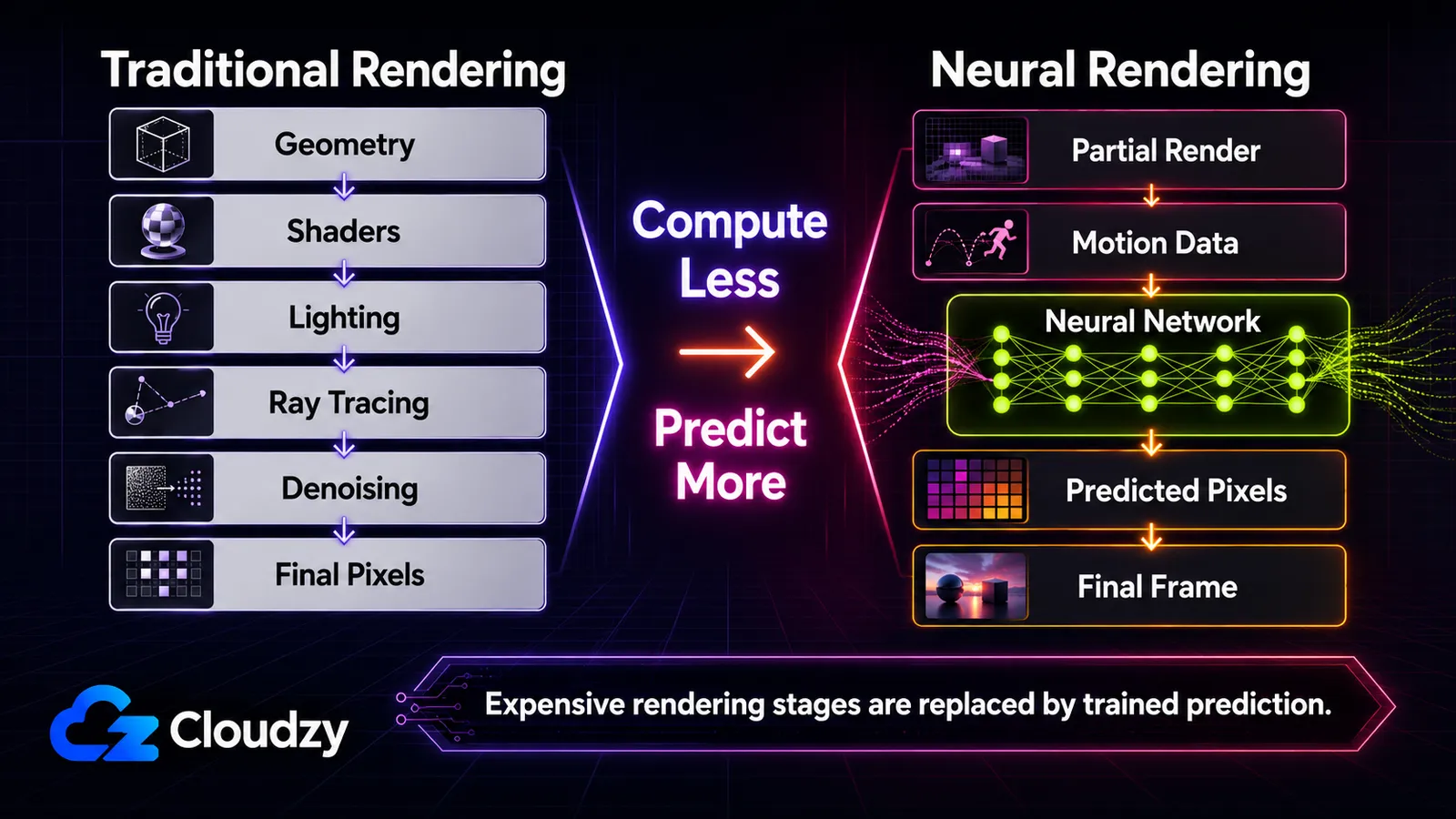
以下这条主线让整件事变得清晰可辨: GPU 正越来越多地预测图像,而非计算图像。 传统上,GPU 通过模拟几何、光照和材质(光栅化,以及近来在其之上的光线追踪)来计算每一个像素。神经渲染改变了什么被 计算 而什么被 预测 由经过训练的网络来完成。这一个区分就是本文的主干。读到最后,你将能够把任何一种技术放到一条谱系上,知道哪些可以实时运行、运行在什么硬件上,并且分辨出今天哪些已经用在游戏里、哪些还只是研究论文或 GTC 演示。这是一张地图,而非操作指南。任何单一技术的深层机制都各自是一篇文章。
简短版本
- 神经渲染是一条谱系,而非 DLSS 的同义词。 它涵盖场景重建研究(NeRF、Gaussian Splatting)、位于渲染管线内部的实时组件(DLSS、Ray Reconstruction、神经辐射缓存),以及凭空创造出帧中从未有过的细节的生成式方法。
- 其主线是“以预测取代计算”。 每种技术都用一个网络来取代管线中某个昂贵的计算阶段,由该网络预测它被训练去得出的结果。
- 今天投入使用的大多是混合方案。 超分辨率、帧生成和 AI 降噪如今已在实时游戏中运行,而神经纹理压缩和神经着色器正通过开发者工具包逐步出现。用一个网络绘制整张图像的完整神经渲染器仍处于研究阶段。
- 它正在变成跨厂商的事,而不只是 NVIDIA 一家的故事。 Microsoft 在着色器级 ML 上的 DirectX 工作始于 Shader Model 6.9 中的 Cooperative Vectors,并正朝着 Shader Model 6.10 中更广泛的线性代数支持迈进,为引擎提供了一条超越单一厂商技术栈、面向神经风格着色器工作负载的途径。
为何“神经渲染”指代五种不同的事物
神经渲染是一类利用神经网络来预测图像某些部分(像素、光照、材质,乃至整帧)的方法,而这些部分原本需要 GPU 从头计算。 Tewari 等人的综述 将其定义为把经典计算机图形学与深度生成模型相结合,以产生照片级真实的输出。这个术语横跨一条宽广的谱系,而“DLSS”只是其上的一个点。
讨论之所以一团乱,是因为这条谱系至少有三个截然不同的层级,而大众却用同一个词来指代它们全部。
第一层是 学术 / 重建类神经渲染:NeRF、3D Gaussian Splatting 和可微渲染。它们采集真实场景的照片或测量数据,学习出一种表示,使你能够从新的相机视角进行渲染。 最初的 NeRF 论文 (Mildenhall 等人,2020)训练一个小型网络,将 3D 坐标和观察方向映射为颜色和密度,然后通过查询它来渲染新视角。这一层大多是离线的。它重建场景,并不驱动你游戏的逐帧循环。
第二层是 实时管线神经渲染:在普通光栅化帧内部或旁侧运行的网络。DLSS 超分辨率、Ray Reconstruction 和神经辐射缓存都属于这一层。管线仍然进行光栅化和光线追踪,由一个网络处理其中某个昂贵的阶段。这一层正是今天已用于游戏的层级。
第三层是 生成式神经渲染:网络产出帧根本从未计算过的图像内容。DLSS 4 的生成帧位于这一层的边缘,而 DLSS 5(NVIDIA 已宣布于 2026 年秋季推出)则更深入其中,通过生成光照和材质细节,而不仅仅是在已渲染帧之间做插值。
这三层行为各异,运行速度不同,所需硬件也不同。把它们当作同一回事,正是为何两个人可以分别说“神经渲染被过度炒作”和“神经渲染是未来”,而双方都各有几分道理。
本节要点:这个术语早于 DLSS 出现,并非它的同义词。DLSS 只是一条宽广得多的谱系中的一个应用(实时、管线内),这条谱系从离线场景重建一直延伸到完全生成的帧。
神经渲染如何取代暴力计算管线的某些部分
在完整的 DLSS 4 多帧生成下,屏幕上每十六个像素中大约有十五个是由 AI 产出的,而非传统渲染得来(依据 NVIDIA 的 DLSS 4 数据)。这个数字把整场转变压缩成了一项统计:渲染器计算图像的一小部分,预测其余部分。
传统渲染靠真本事赢得每一个像素。GPU 对几何进行光栅化,运行着色器来计算光照和材质,并(借助光线追踪)模拟光线在场景中的弹射。尤其是光线追踪,开销极其巨大,因为真实的光照需要多次弹射和每像素多个采样,而采样不足带来的噪点之后还得清理掉。随着场景越来越雄心勃勃,开销最大的那些阶段就成了显而易见的目标:与其去计算它们,不如训练一个网络来预测它们的输出。
这一进程是稳步推进而非骤然发生的:
- 2018 年,DLSS 1.0。 第一个商业化步骤:以低分辨率渲染,预测高分辨率图像。把放大从“计算更多像素”转变为“预测更多像素”。
- 2020 年,NeRF。 通过学习得到的辐射场,从图像重建场景。预测新视角,而非建模并渲染几何。
- 2021 年,神经辐射缓存。 在路径追踪过程中预测弹射光,使渲染器能够提前停止追踪。
- 2022 年,DLSS 3 帧生成。 生成完整的中间帧,而非渲染它们。
- 2023 年,3D Gaussian Splatting。 针对重建场景,一种比 NeRF 更快、更偏向实时的替代方案。
- 2025 年,DLSS 4 + RTX Kit。 多帧生成,外加一套神经组件工具包(纹理压缩、辐射缓存、神经着色器)。
- 2025 年,DirectX Cooperative Vectors(预览版)。 一个面向神经着色器所需矩阵运算的跨厂商 API(作为 Shader Model 6.9 的一部分以预览形式推出)。
- 2026 年,DLSS 4.5。 画质和 Ray Reconstruction 的渐进式改进(由 NVIDIA 在 Computex 上介绍)。
- 2026 年秋季,DLSS 5(已宣布)。 迈向生成式神经渲染的下一次推进。
自上而下读,每一行都是同一招用在不同阶段上:把管线过去用来计算的某样东西,改由一个网络来预测。
六个层级:AI 在管线的每个阶段取代了什么
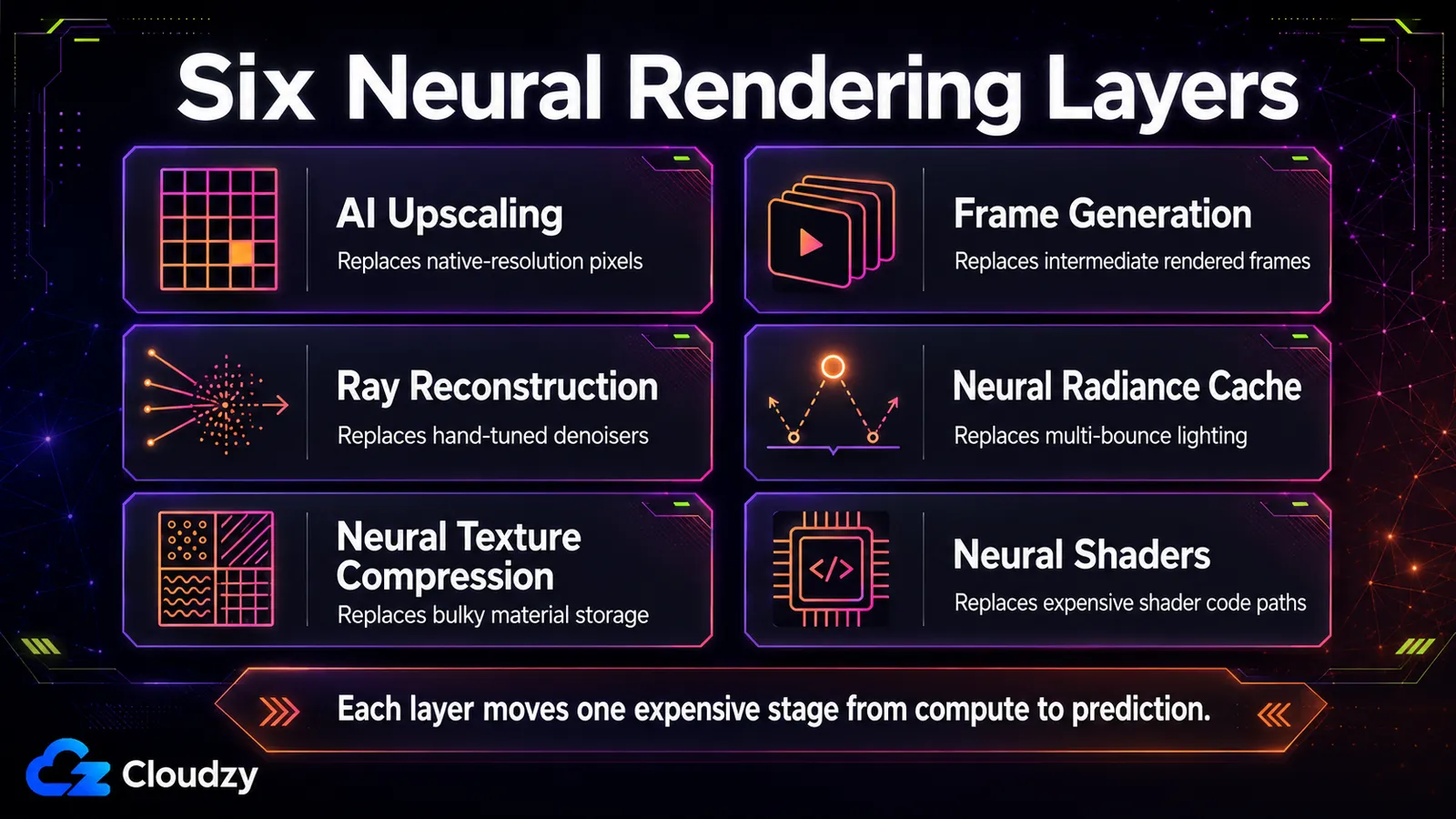
六种技术承载了当今大部分实时神经渲染,每一种都取代了某个特定的计算阶段:超分辨率(分辨率)、帧生成(帧数)、ray reconstruction(降噪)、神经辐射缓存(全局光照)、神经纹理压缩(材质存储)和神经着色器(着色器内计算)。弄清楚每一种触及哪个阶段,便已是成功的大半。
它们的划分依据是 网络在管线中的何处运行。有的在最末端作为对成品帧的后处理运行;有的在管线中段与光线追踪并行运行;有的就存在于着色器本身内部。这个位置并非细枝末节。它决定了该技术能跑多快、需要什么硬件。下表梳理了这六种技术;下面的小节则解释那些无法整齐地塞进表格单元的机制。
| 技术 | 它取代了什么 | 实时可行性 | 所需硬件 | 跨厂商? |
|---|---|---|---|---|
| AI 超分辨率(super resolution) | 计算原生分辨率像素 | 实时,开销低 | Tensor / 矩阵核心(RTX 20+、RDNA 4、Intel XMX) | 作为一个类别是;但具体实现仍因厂商而异(DLSS、FSR / FSR Upscaling、XeSS) |
| 帧生成 | 渲染中间帧 | 实时;会增加延迟 | RTX 40+(DLSS 3),多帧需 RTX 50 | 部分是;因厂商而异 |
| Ray reconstruction | 手工调校的降噪器堆栈 | 实时 | RTX 20+ | 目前仅 NVIDIA |
| 神经辐射缓存 | 计算多次弹射的间接光 | 实时(据称约 2.6 ms) | RTX 级矩阵核心 | 目前仅 NVIDIA(RTX Kit) |
| 神经纹理压缩 | 块压缩的材质存储 | 实时解码 | RTX 级矩阵核心 | 目前为 NVIDIA SDK/工具;更广泛的着色器级 ML 支持正在另行标准化 |
| 神经着色器 | 计算式着色器代码路径 | 实时 | 着色器级 ML / 具备矩阵能力的 GPU | 通过 DirectX SM 6.9 / SM 6.10 路径逐步出现 |
AI 超分辨率(Super Resolution)
AI 超分辨率以较低分辨率渲染帧,并预测出高分辨率结果,因此 GPU 绘制的像素少得多,由网络补全结构。DLSS、AMD 的 FSR 4 和 Intel 的 XeSS 都通过 时域 上采样来实现:它们在连续多帧间采样不同的像素,并将这段历史与运动矢量结合起来,重建出单一低分辨率帧所不包含的细节。
这是最成熟、部署最广泛的一层,也是跨厂商现实最清晰的地方。DLSS 4 将其放大器从卷积网络换成了 transformer,以获得更好的细节稳定性。FSR 4 是 AMD 首个基于 ML 的放大器,运行在 RDNA 4 上,采用 FP8 推理,而非早期 FSR 版本的手写启发式方法。XeSS 使用 Intel 的 XMX 矩阵单元。三家厂商,同一个底层思路:预测出你没有渲染的那些像素。
帧生成与多帧生成
帧生成通过将运动矢量等游戏数据与光流估计和 AI 相结合,预测出 GPU 实际渲染的两帧之间的整帧画面。DLSS 3 利用 RTX 40 系列的 Optical Flow Accelerator 在已渲染帧之间插入一帧生成帧;运行在 RTX 50 系列硬件上的 DLSS 4 多帧生成则可以为每一个传统渲染帧最多生成三个额外帧,且 NVIDIA 表示 DLSS 4 用一个更高效的 AI 模型取代了硬件光流步骤。
这正是“假帧”争论真正所指的那一层,而这里的表述方式很关键。一个生成帧是对场景走向的一种合理插值:它向你呈现出可用的视觉内容。但它是被 预测出来的,而非根据游戏的实际状态渲染而成,它也不携带新的游戏逻辑或输入。至关重要的是,帧生成是在一帧被渲染 之后 运行的,这会增加延迟而非消除延迟;NVIDIA 的 Reflex 2 正是为了把这部分延迟夺回来而存在。所以“帧生成让游戏更快”只是部分属实:它提升了感知上的流畅度(显示更多帧),却并未提升游戏实际更新和响应的速率。你所看到的与游戏所知道的之间的这道鸿沟,正是整场争论的核心;而对于由输入延迟决定胜负的竞技对战来说,这是一项值得权衡的取舍。
Ray Reconstruction(AI 降噪)
Ray Reconstruction 用单个神经网络取代了光线追踪渲染所依赖的那一套手工调校降噪滤镜,该网络经过训练,能从带噪、欠采样的光线追踪输入中重建出干净的图像。路径追踪在实时条件下每像素只承担得起寥寥几个光线采样,这使得原始输出充满噪点;在你看到之前,总得有东西把它清理干净。
传统做法是一连串专用降噪器,每一个都为某种特定效果手工调校。把它换成单个训练好的网络,往往能保留手工调校滤镜会抹掉的细节,尤其是在反射和精细光照上,而且只需维护一个网络,而非一条脆弱的滤镜流水线。这是该主线的一个清晰例证:降噪阶段从“用手写启发式方法计算”转变为“用训练好的模型预测”。
神经辐射缓存(全局光照)
神经辐射缓存(NRC)预测光线如何在场景中弹射,使路径追踪器能够提前停止追踪大部分光线,而不必追踪每一次弹射直到结束。全局光照(那种从墙壁和地板上弹射开来的柔和间接光)是实时图形中开销最大的事物之一,而让 NRC 得以运作的机制很少有人用通俗的语言解释,因此值得放慢节奏细说。
机制如下。路径追踪器通常会跟踪每一条光线经历多次弹射,开销正是在此处爆炸式增长。NRC 训练一个小型网络, 在 渲染期间(而非提前)预测某一点在进一步弹射之后所接收到的光。于是路径追踪器只追踪光线一两次弹射,然后向网络发问“这里其余的光是多少?”,并提前终止该路径; 实时神经辐射缓存论文 (Müller 等人,2021)报告称以这种方式终止了绝大多数路径。可以把它想象成一种缓存,它并不存储自己以前见过的精确答案,而是学习 模式 场景光照的模式,学得足够好,以至于能回答它未曾见过的查询,并随着场景变化不断重新学习。NVIDIA 报告称 NRC 运行时开销约为 2.6 ms,正是这一点使它具备实时可行性,而非仅仅是一桩研究上的趣谈。
神经纹理压缩
神经纹理压缩(NTC)用一个网络把一个材质的所有纹理通道一并压缩,在相近的视觉质量下,相比传统块压缩可达到最高 8 倍的显存节省(依据 NVIDIA 的 RTX Kit 文档)。现代材质并非单一纹理。它是一叠纹理(颜色、法线、粗糙度、金属度等等),而这些通道之间存在相关性,块压缩独立地压缩每个通道,恰恰把这种相关性丢弃了。
NTC 正是利用了这种相关性。通过一次性学习一个材质所有通道之间的联合结构,它用少得多的内存存储同一个材质,并在渲染时即时解码。随着游戏不断推高纹理细节,显存始终是个制约因素,因此“在相同内存中塞进 8 倍的材质”是一项直接而实用的收益,而非视觉上的花招。
神经着色器与 DirectX Cooperative Vectors
神经着色器在 内置于 一个可编程着色器(GPU 已经在执行的逐像素/逐顶点程序)内部运行小型神经网络,使网络能够就在某个效果所需之处近似出一个昂贵的计算效果。与其把 AI 作为一个独立通道外挂上去,不如让 MLP 作为着色器的一部分,运行在 GPU 的矩阵单元上(在 NVIDIA 硬件上即 Tensor Cores)。
Tensor Cores 负责这些网络所依赖的矩阵运算,有别于处理其余工作的通用核心。把神经着色器从单一厂商的特性转变为更广泛的行业能力的,是它们底层的 API 层。 Microsoft 引入了 DirectX Cooperative Vectors, 于 2025 年随 Shader Model 6.9 以预览形式推出,用以在 HLSL 着色器内部暴露向量/矩阵运算。到 2026 年,Shader Model 6.9 已转为正式版,Microsoft 表示 Cooperative Vector 正被弃用,转而采用计划用于 Shader Model 6.10 的更广泛的线性代数设计。稳妥的结论并非 Cooperative Vectors 就是最终的 API,而是 DirectX 正朝着跨厂商的着色器级 ML 支持迈进。
本节要点:这六种技术按网络运行的位置来归类:在帧末端作为后处理、在管线中段与光线追踪并行,或在着色器本身内部。正是这个位置决定了一种技术能否实时运行,以及它需要哪种硬件。
什么能实时运行,以及运行在什么硬件上
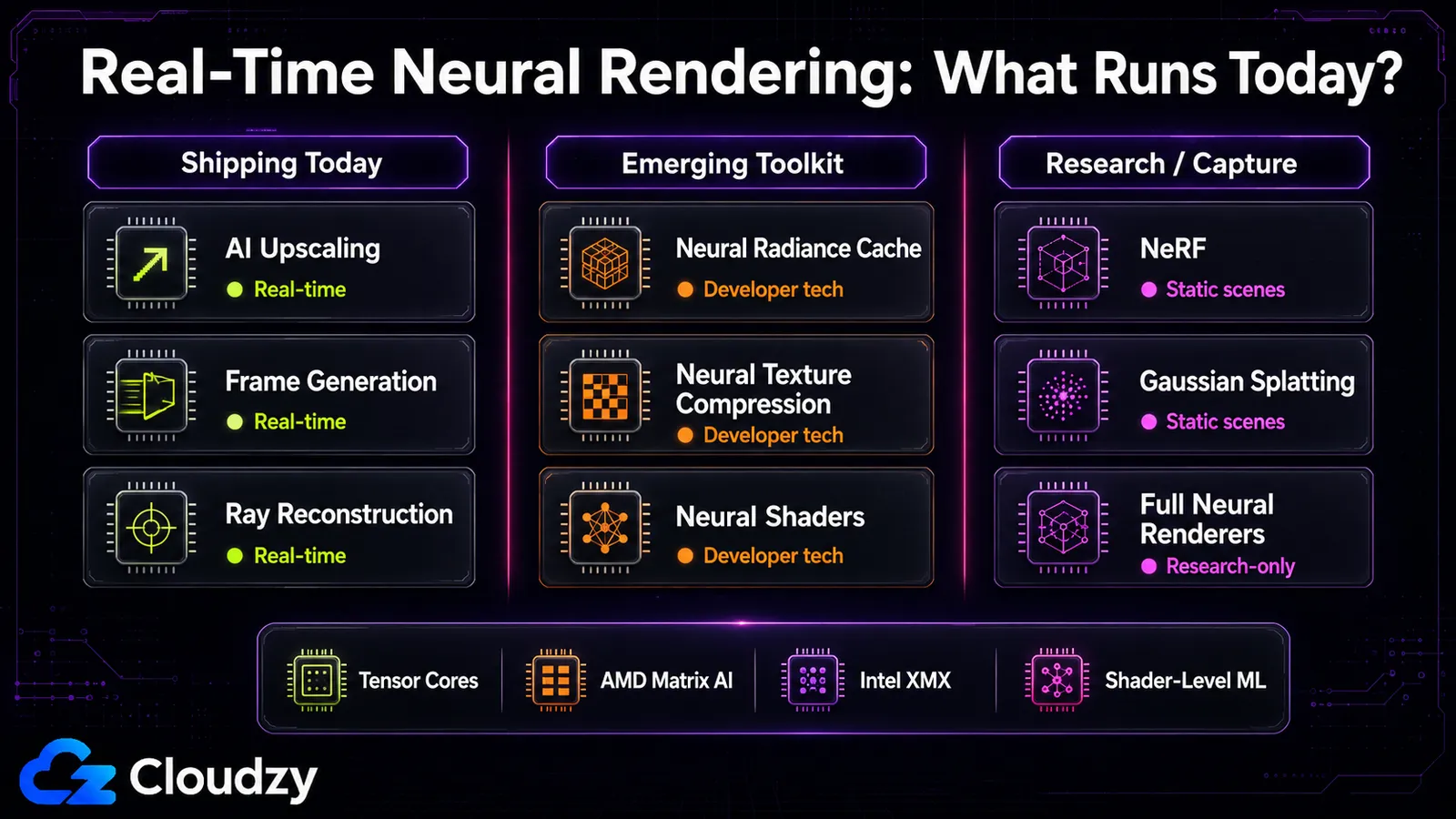
实时与否的界线比炒作所暗示的要清晰得多:AI 超分辨率通常开销很低,NRC 增加约 2.6 ms,3D Gaussian Splatting 对静态场景接近实时。最初的 NeRF 和像 RenderFormer 这样的完整神经渲染器则确凿地仅限研究,每帧耗时远超交互式使用所能接受的范围。“神经渲染是实时的”这句话对管线内那一层成立,而对重建层和完整渲染器层则不成立。
这一划分恰好与谱系吻合。部分管线内组件,尤其是超分辨率、帧生成和 Ray Reconstruction,已经在已发售的游戏中运行。另一些,如 NRC、NTC 和神经着色器,更宜被描述为开发者技术和初现的工具包特性,而非常见的量产特性。重建层则参差不齐:最初的 NeRF 很慢,但 3D Gaussian Splatting 是有意朝实时推进的尝试,并对静态场景实现了实时。完整神经渲染器那一层(用单个网络产出整张图像)正是研究所在之处,其帧时间远远谈不上交互式。
硬件是答案的另一半,而跨厂商的故事正落脚于此。这里的每一种技术都运行在现代 GPU 为 AI 推理而搭载的矩阵运算单元上:
- NVIDIA 从 20 系列起的每一块 RTX 显卡上都配有 Tensor Cores,这也是为何这些技术大多最先在它上面亮相。
- AMD 的 基于 ML 的 FSR Upscaling 目前在 ML 路径上面向 RDNA 4 / Radeon RX 9000 系列 GPU;在更早的硬件上,AMD 的 SDK 会回退到分析式的 FSR 3.1.5 路径。对更广泛的旧 GPU 支持,应视其为仍在变动的路线图条目,而非有保证的 FSR 4 特性,除非你能引用 AMD 的某项具体公告。
- Intel 在 Arc GPU 上使用 XMX 矩阵引擎来实现 XeSS。
DLSS 本身按代际对功能设限:超分辨率可向上追溯至 RTX 20 系列,最初的帧生成需要 RTX 40 系列,而多帧生成仅限 RTX 50 系列。如果你想推断某块显卡能做什么,这种代际设限才是实用的答案,而非营销层级。
你今天能用什么,对比即将到来的是什么:超分辨率、帧生成和 Ray Reconstruction 今天已能在游戏中使用。 RTX Kit 组件 (如 NRC、NTC 和神经着色器)作为开发者技术和工具已可获取,但你不应暗示它们全都已在已发售的游戏中普遍存在。Gaussian Splatting 拥有可用于场景捕获的开放工具。尚未到来的是:用单个网络绘制整帧的完整神经渲染器、成熟的跨厂商神经着色器(AMD 的支持尚处早期),以及 DLSS 5 的生成式特性(已宣布于 2026 年秋季推出)。如果你想在重建这一侧做实验(自己运行 NeRF 或推理工作负载),那是一项 GPU 计算 的活儿,而不是你的游戏会替你完成的事。
神经渲染不是什么:五个误解

大多数关于神经渲染的争论,一旦你辨明该说法针对的是谱系中的哪一层,就会变得容易许多。有五个误解反复出现。
1. “DLSS 超分辨率就是神经渲染。” DLSS 是神经渲染的一个 an 应用,即管线内的实时层,而非整个领域。这个术语早于 DLSS,还包括 NeRF、Gaussian Splatting 以及生成式方法。把二者等同起来,就像把“数据库”说成是你恰好在用的某一款产品的同义词。
2. “帧生成让游戏更快。” 它提高了你看到的帧数,使动作看起来更流畅,但它在渲染之后运行,会增加延迟。游戏更新并响应你输入的速率并未提高。对竞技对战而言,那点延迟是一项实实在在的取舍;对视觉流畅度而言,它是一项真切的收益。“更快”把这两者混为一谈了。
3. “DLSS 5 具备 3D 感知 / 读取 3D 场景。” 这一点最值得弄清楚,因为科技报道一再地对它做出错误描述。按 NVIDIA 的说法,DLSS 5 以每一帧的颜色数据和运动矢量作为输入,然后用其训练好的模型推断场景语义,例如角色、头发、布料、皮肤和光照条件。它以游戏内容为依据,但 NVIDIA 并未将其描述为直接读取游戏完整的 3D 场景文件。“3D 引导”意味着推断在几何上保持一致(它尊重表面如何运动以及彼此间的关系),而非网络直接读取场景几何。这一区分很重要,因为它界定了该技术能知道和不能知道什么。
4. “NeRF 现在已经实时了。” 这取决于你指的是哪种技术,而这恰恰就是谱系问题。最初的 NeRF 不是实时的。3D Gaussian Splatting 对静态场景接近实时。用单个网络渲染整帧的研究系统(RenderFormer 及类似者)则根本谈不上实时。“NeRF”已成了一个笼统的统称,囊括了速度天差地别的六七种方法。
5. “神经渲染很快就会取代光栅化。” 如今的系统是混合式的:神经组件位于一条光栅化与光线追踪管线 内置于 之内,而非取而代之。用单个生成式渲染器完全取代经典管线是一个长远的研究目标,而非近期的产品方向。把“未来将完全神经化”当作一个行进方向,而非一个有明确时间表的预言。
本节要点:几乎每一场神经渲染分歧的唯一根源,都是人们用同一个词指代谱系中不同的层级。先把那个说法定位到谱系上,大部分争论便会烟消云散。
这一切将走向何方
其走向与上文的一切相吻合:今天是混合管线,越来越多的阶段从计算转向预测,跨厂商的神经着色器拓宽了能够交付这类技术的群体,而完整神经渲染器这一前沿仍在数年之外。面向消费者的下一步是 DLSS 5,已宣布于 2026 年秋季推出,它通过产出游戏从未计算过的光照和材质细节,而不仅仅是在已渲染帧之间插值,从而推进至生成式神经渲染。NVIDIA 已在 RTX 50 系列的语境中展示了该技术,但在 NVIDIA 公布明确的兼容列表之前,其面向消费者的最终硬件要求应被视为尚未确认。
前瞻分为两半。在近端,最要紧的举措并非任何单一技术,而是标准化。Microsoft 的 DirectX 路径正从 Cooperative Vectors 转向更广泛的着色器级线性代数,这可能让引擎得以面向神经风格的工作负载,而无需押注某一个 GPU 品牌。在远端,NVIDIA 的研究人员描述了一个遥远未来的终点,有时被设想为一个假想中的“DLSS 10”,届时渲染器将完全神经化,经典管线不复存在(系从一场 Digital Foundry 圆桌讨论中间接获悉;应将其视为一种表态的方向,而非路线图)。这道阶梯的终点,是一个生成出一个连贯世界而非绘制出一个世界的系统。
不过,保留一份怀疑仍属应当。生成的细节可能偏离艺术意图,网络也可能臆造出看似合理实则错误、且没有传统对应物可供调试的画面:这是 GDC 2026 上被点名的一个 QA 问题,也是许多“AI 废料”反应背后的实质所在。为图形的走向而构建,并不意味着假装当前的输出已经完善。它意味着关注接下来哪些阶段会从计算转向预测,并依据每一项对图像所产生的实际效果来评判它,而非依据贴在它身上的那个词。
常见问题
DLSS 是神经渲染吗?
是,但它只是其中一种。DLSS 是神经渲染的一个应用:具体而言是实时的、管线内的那一层,涵盖 AI 超分辨率和帧生成。这个更宽泛的术语早于 DLSS,还包括像 NeRF 和 Gaussian Splatting 这样的场景重建方法,以及凭空创造新图像细节的生成式方法。所以每一项 DLSS 特性都是神经渲染,但大量的神经渲染并不是 DLSS。
神经渲染与光线追踪有何区别?
光线追踪 模拟 光,靠的是计算光线如何在场景中弹射;神经渲染则 预测 用一个训练好的网络预测结果,而非去计算它们。二者并非对手。它们彼此结合。例如,Ray Reconstruction 用一个神经网络对带噪的光线追踪输出进行降噪,而神经辐射缓存预测弹射光,使光线追踪器能够提前停止。神经技术让光线追踪在实时条件下变得负担得起。
DLSS 帧生成会增加延迟吗?
会。帧生成在一帧被渲染之后运行,并在已渲染帧之间插入预测帧,这会增加延迟而非消除延迟:NVIDIA 的 Reflex 2 正是为弥补这一点而存在。它提升了感知上的流畅度(显示更多帧),却并未提升游戏更新和响应输入的速度。对竞技对战而言这是一项取舍;对单人游戏的流畅度而言,它通常是一项净收益。
NeRF 是实时的吗?
这取决于你指的是哪种技术。最初的 NeRF 不是实时的。3D Gaussian Splatting 作为一种较晚出现的方法,对静态场景接近实时。用单个网络绘制整帧的完整神经渲染器仅限研究,远未达到交互式速度。“NeRF”常被宽泛地用来指代性能差异极大的好几种方法,这正是大部分混淆的来源。
神经渲染会取代光栅化吗?
不会很快。如今的系统是混合式的:神经组件运行在一条光栅化与光线追踪管线之内,而非取而代之。用单个生成式渲染器彻底取代经典管线是一个长远的研究目标,而非近期的产品。现实的方向是,随着时间推移,越来越多的管线阶段从计算转向预测,而光栅化在未来许多年里仍将承担实实在在的工作。
什么是神经纹理压缩?
神经纹理压缩(NTC)是一种神经方法,它把一个材质的所有纹理通道一并压缩(颜色、法线、粗糙度等等),据 NVIDIA 称,在相近的视觉质量下,相比传统块压缩可达到最高 8 倍的显存节省。它的原理是学习各通道之间的相关性,而块压缩独立地压缩每个通道,恰恰丢弃了这种相关性。压缩后的材质会在渲染时即时解码。


