GPU监控软件能够将"我的GPU感觉不对劲"这样的模糊表述转变为直接明确的诊断,比如"热点温度飙升、时钟频率下降、VRAM占满"。
在本指南中,我将为你介绍用于 AI 任务、游戏叠加层和长时间工作站会话的工具,并展示 GPU 指标,帮助你诊断性能下降、卡顿和崩溃问题。
最后,你会有一个符合你工作方式的 GPU 监控软件配置。我们还会提供四个常见场景的现成堆栈代码,这样你就不用再翻文档了。
快速答案:Top GPU 监控软件按使用场景分类
如果你只需要一个实用的短清单,就从这些开始。实际上,最好的 GPU 监控方案通常是组合使用:一个工具用来快速检查,一个用来处理数据覆盖或日志,一个用来查看历史记录或告警。
快速导航:
| 使用场景 | 完美的起手配置 | 您将获得 |
| AI 训练、推理、高性能计算任务 | nvidia-smi (NVIDIA) 或 AMD SMI (AMD) + 日志记录/导出器 | 快速检测、可编程日志、轻松告警 |
| Windows 上的游戏 | MSI Afterburner + RTSS + 帧时间捕捉工具 | 叠加层加证明:卡顿对比低帧率 |
| Linux 上的游戏 | MangoHud + 一个终端监控工具(nvtop) | 轻量级覆盖层,加上按进程的完整性检查 |
| 工作站(3D/视频/CAD) | HWiNFO 日志记录 + 简单压力测试 | 详细日志可分享,便于重现问题 |
| 共享 GPU 机器 | nvtop (Linux) + 导出器/仪表板 | 按进程 VRAM 可见性 |
接下来的工作就是让 GPU 监控软件适配你的数据查看方式:在屏幕上实时显示、写入日志,或在仪表板中展示。
本指南适合谁
我会像调试过真实机器的人一样来写这个。因为根据经验,我知道不同的读者需要不同的工具,即使他们面对的是同一个GPU。
以下是我要针对的四种配置:
- 模型构建工具(AI/ML): 关心 VRAM 的余量、持续时钟速度、降频现象,以及「任务能否整夜运行而不中断?」
- 竞技游戏玩家/主播: 关心帧时间、叠加层稳定性,以及驱动更新后的性能回退检测。
- 工作站用户(3D/视频/CAD): 关注日志、可重现的崩溃,以及精确定位热量、功耗和驱动程序行为的差异。
- 运行 GPU 机器的管理员: 关心告警、趋势图表、容量规划和及早发现故障。
确定了你所在的配置等级后,就能轻松选择适合你的 GPU 监控软件。
如何选择 GPU 监控软件
很多性能监控应用看起来差不多,用一周就能看出区别。真正的差异在于输出准确度和可靠性,而不是那些应用费力宣传的花哨功能。
我来帮你用三个问题快速选择 GPU 监控软件:
- 你需要叠加层、日志还是两者都需要?
游戏玩家需要覆盖层。AI 和工作站应用通常需要日志记录。管理员需要日志加告警。 - 需要查看每个进程的详细信息吗?
如果你与他人共享一台服务器(实验室、工作室、远程服务器),per-process VRAM 通常是你首先要检查的。 - 需要历史记录和告警吗?
如果任务在夜里运行,光说「我等会儿查」是不够的。你需要图表和告警。
为了保持实用性,本指南的其余部分按 GPU 指标分类,然后按每个使用场景配套的技术栈分类。
GPU 应该优先关注的指标
Good GPU 监控软件会给你大量数据。真正有用的 GPU 监控软件只提供那些能解释系统行为的关键指标。我按照这些指标帮助你做出的决策来分组。
温度和降频指标
这些是 GPU 指标,解释了「前10分钟很快,之后就不行了」的原因:
- GPU温度
- 热点温度 (通常最先出现瓶颈)
- 内存温度/结点温度 (在长时间 AI 运算和长时间渲染时更为重要)
- 风扇速度 (帮助识别笔记本电脑配置文件或风扇曲线问题)
如果要提高稳定性,记录这些指标。单次快照通常提供的信息不足。
性能、频率和限制
这些 GPU 指标说明了降频和性能不稳定的原因:
- 主板功耗
- 核心时钟和内存时钟
- 功率限制/性能状态 (如果你的工具支持的话)
在很多实际调试场景中,功耗和时钟频率所呈现的信息,远比基础的"GPU 使用率 %"更直观清晰。
VRAM 和内存压力
这些 GPU 指标能够解释卡顿、内存溢出错误以及常见的"莫名其妙"性能下降问题:
- VRAM 已用 vs 总量
- 内存控制器活动 (帮助识别带宽瓶颈)
- 系统 RAM 压力 (因为 VRAM 泄漏也会拖累系统性能)
对于 AI,VRAM 往往是硬瓶颈。对于游戏,VRAM 压力通常先表现为帧时间尖峰。
帧时间和帧速率指标
对于游戏和直播来说,仅看 FPS 是不够的。帧时间才是真正应该关注的指标,它能反映画面的流畅程度:
- 帧时间 (ms)
- 1% 低 / 0.1% 低 (便于对比)
- GPU 繁忙 vs CPU 繁忙 (帮助区分 GPU 瓶颈和 CPU 瓶颈)
这就是为什么面向游戏的性能监控应用通常包含帧时间捕捉功能。掌握了基本指标后,我们可以讨论各种工作流最适合的 GPU 监控软件栈。
GPU AI、训练和服务器监控软件

AI 监控设置简单,在终端中快速检查,长时间运行时可输出日志和告警。为此,你需要 GPU 监控软件,它支持 CLI 命令行界面并能导出指标。
NVIDIA: 用 nvidia-smi 快速查看和脚本化日志
在NVIDIA系统上, nvidia-smi 通常是人们运行的第一个命令,因为它随驱动程序一起提供,专为通过 NVML 进行监控和管理而设计。
官方文档在这里: NVIDIA 系统管理界面 (nvidia-smi).
如果你想要简单粗暴的方法(先记录日志,之后再查看,这样的做法出乎意料地有效),这个模式很可靠:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
这是基础的 GPU 监控软件行为,包含时间戳、核心 GPU 指标,以及易于与脚本集成的输出。
AMD: 用于 ROCm 和 HPC 节点的 AMD SMI
在 AMD 和 Linux 计算节点上,AMD SMI 是现代化的监控和管理界面。AMD 将其定位为高性能计算环境中的统一监控和控制工具集。
官方文档在这里: AMD SMI 文档.
如果你的环境大量使用 AMD,AMD SMI 就是其他监控工具建立的基础。
按进程显示:用 nvtop 监控共享 GPU
如果你曾在共享服务器上遇到 VRAM「莫名其妙」满载的情况,按进程查看资源使用情况能节省不少时间。在 Linux 上, nvtop 正因为这个原因而受欢迎,因为它能立即明确显示"谁在使用VRAM?"。在AMD/Intel上,您可能需要最新的内核才能获取每个进程的统计数据。
在混合团队中,我经常看到人们使用 nvtop 并肩 nvidia-smi 或者 AMD SMI。这个组合很简单,能省去很多猜测,我强烈推荐。
别忽视硬件的选择!
监控无法提升 VRAM 的性能上限,它只是让这个上限变得可见。如果你还在手动将工作负载分配到 GPU 层级,我们的指南可以帮助你 2025 年最适合机器学习的 GPU 很有帮助,因为它以与你后来在日志和控制面板中阅读时相同的方式呈现 VRAM 和带宽。
一旦掌握了服务器级 GPU 监控软件,下一步就是处理叠加层和帧时间,因为 交互式工作负载的表现不同.
GPU 游戏和直播监控软件

游戏玩家对 GPU 工具的要求最高,主要原因是叠加层在关键时刻掉线。游戏需要简洁可靠的叠加层和稳定的帧时间捕获。
MSI Afterburner + RTSS 在 Windows 上的叠加层显示
这个组合很受欢迎,因为你可以用 GPU 指标构建一个干净的叠加层,只显示你关心的数据,比如使用率、时钟速度、VRAM、温度、帧时间,以及风扇转速。
社区讨论中反复出现一个严重警告:假冒下载网站。MSI 官方 Afterburner 页面明确指出,正版下载应该来自 msi.com 和 Guru3D,同时也列出了当前发行版本(4.6.6 final,发布于 2025 年 10 月)。
界面覆盖问题是另一个需要注意的事项。例如,RTSS 在某些游戏中能正常工作,但在其他游戏中会失效,特别是在现代渲染管线中。用户报告过覆盖层 在 Vulkan 中显示,但在 DX12 中不显示 同一标题下找不到,或在更新后消失。
不过这不是你的错,只是当叠加层连接到不断变化的游戏和驱动程序栈时会发生的情况。
如果你想要一个稳定的基础覆盖层,保持简洁:
- 帧时间
- GPU 使用率
- VRAM 已用
- GPU温度
仅在你正在主动调试节流问题时,才添加电源和频率项。
帧时间捕获以检测"卡顿"
这就是性能监控应用派上用场的地方,它们能捕捉帧时间图表。平均帧率看起来不错,但帧间距可能糟糕透顶。帧时间图表能快速解决这个问题。
许多游戏基准测试工作流在底层依赖 PresentMon,而且 NVIDIA 文档 其 FrameView 分析工具使用 PresentMon 来捕获帧率和帧时间数据。
你不需要对每个游戏都进行基准测试。帧时间捕获最适合用于对比,比如驱动更新前后、改变限制器前后、调整画质设置前后等情况。
Linux 的 MangoHud 叠层显示
在 Linux 上,MangoHud 经常被推荐,因为它轻量级且与 Steam/Proton 集成得很好。最常见的问题是在混合笔记本电脑配置上缺少传感器或读数异常。
实际上,你可以轻松搭配 MangoHud 和终端检查工具,比如 nvtop。这也很好地说明了 GPU 监控软件为什么作为小型堆栈工作效果更好,而不是一个庞大的单体应用。
从游戏开始,自然而然的下一步是工作站监控,因为那里日志和可复现的故障排查才是最重要的。
借助高速 NVMe VPS 托管,运行无延迟的游戏服务器。
游戏 VPS
GPU 工作站和专业应用监控软件
工作站监控和安全监控不同——它不是盯着实时画面的那种工作,而是要回答一个问题:「过去一段时间里发生了什么,我能复现吗?」
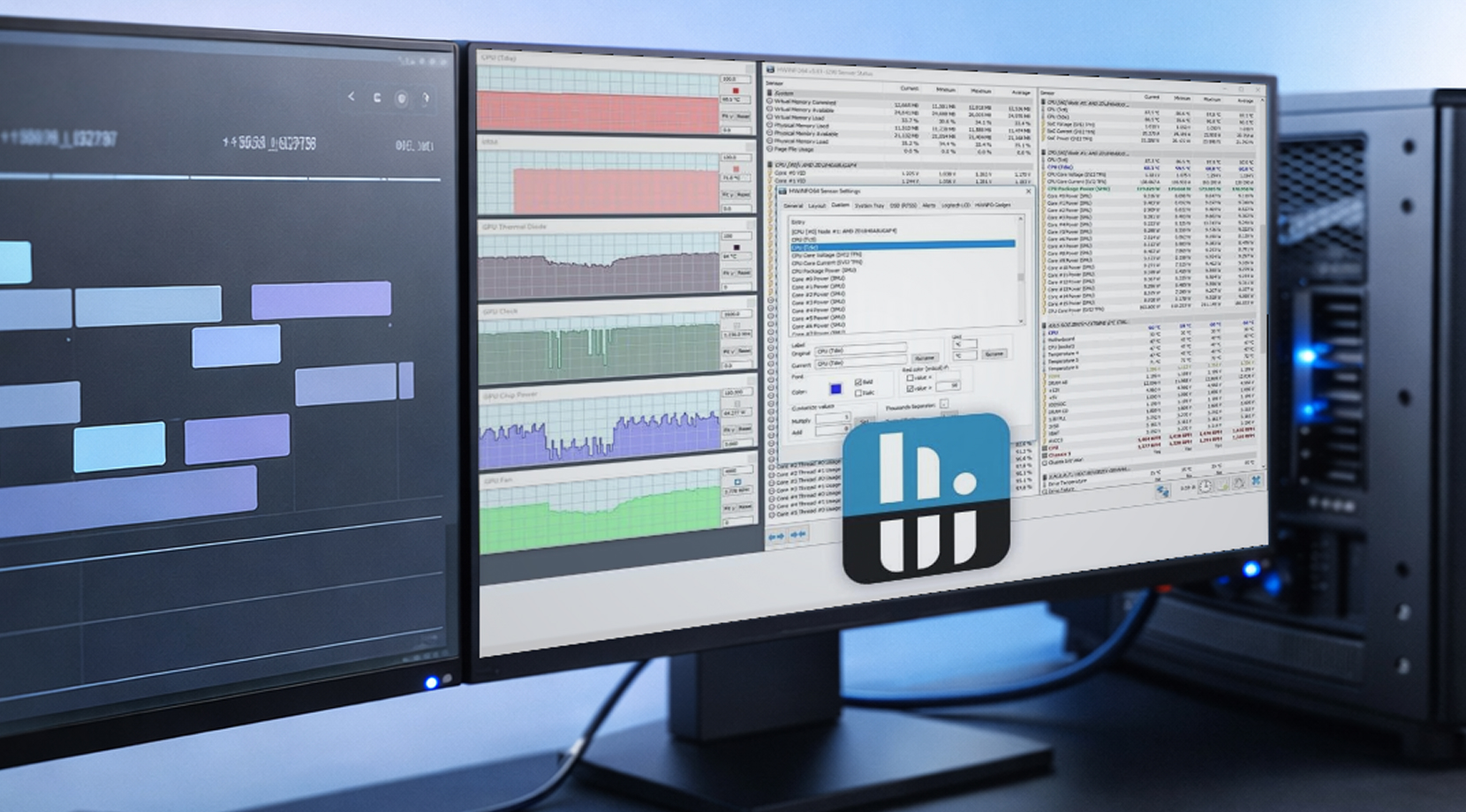
HWiNFO for Windows 日志记录
HWiNFO 在工作站用户中很受欢迎,因为它提供深度的硬件监控和易于分享的日志功能。简单的 CSV 日志加上时间戳,可以把模糊的问题报告变成你能实际用来排查和修复问题的数据。
如果你要为 GPU 构建工作站日志以确保稳定性,从这些 GPU 指标开始:
- GPU 温度和热点
- VRAM 已用
- 主板电源
- 核心时钟
- CPU 套餐功率(平台功率限制会成为瓶颈)
这是「数据足够说明问题」的集合。原因很简单,记录每个传感器只会让文件更难读懂。
GPU-Z 用于快速"这是什么 GPU?"检查
GPU-Z 仍然很有用,因为它速度快、功能专注。在硬件配置不一的团队中,它是验证 GPU 模型、驱动程序基础和实时传感器的最快方式,无需在菜单中费力查找。
压力测试:需要日志记录才有意义
压力测试可以帮助复现崩溃问题,但前提是在运行测试的同时,GPU 监控软件要保持记录日志。没有这些日志,你能得到的信息就只有"又崩溃了",完全没有任何时间线可循。
到了这一步,大多数人都会遇到同样的问题,比如覆盖层不显示、功率读数错误,以及日志变得难以阅读。我们来逐一解决这些问题。
GPU 监控软件的常见问题与快速修复方法

大多数问题都遵循几种常见模式。我优先尝试这些解决方案,因为它们能快速解决那些重复出现的问题。
游戏中缺少覆盖层
现代游戏中如果悬浮窗消失,通常是游戏特定的钩子问题,或者与反作弊和反篡改层产生了冲突。
通常有帮助的做法:
- 更新 RTSS 并重置每个游戏的配置文件
- 为游戏配置文件设置更高的"应用检测级别"
- 如果游戏支持,可以尝试使用不同的 API
- 当标题阻止第三方覆盖层时,回退到内置覆盖层
并非每款游戏都能完美运行,花几个小时死磕一款不配合的游戏实在得不偿失。
异常功率读数(0W、平线、传感器缺失)
在笔记本电脑和混合配置中经常遇到这种情况,因为活跃的 GPU 可能会变化。在这些情况下,建议用其他工具(比如 nvidia-smi (NVIDIA) 或 AMD SMI (AMD),因为它们是检查「GPU 是否真正在运行」的好工具。
日志噪音太多
通常是因为过度采样。在大多数故障排查场景中,1 到 5 秒的间隔就足够了。对于长时间运行的 AI 任务,5 秒也没问题。更短的间隔会增加文件大小,让图表难以阅读。
基础工作就绪后,远程监控就成了自然而然的下一步,因为很多 GPU 工作流现在都在云端运行。
GPU 远程监控和实用的云方案
远程办公改变了"良好的监控软件"的定义。你不会一直盯着机器看,所以你需要能够快速运行的检查,以及之后可以查看的历史记录。
一个干净的远程服务器通常是这样的:
- CLI 检查 (nvidia-smi 或 AMD SMI)
- 一个日志文件,您可以稍后下载查看
- 如果需要告警功能,可配置导出器和仪表板
如果本地硬件已经成为瓶颈(VRAM 限制、多个项目共享单台 GPU、每个项目需要独立环境),在 GPU VPS 上运行工作负载可能是最直接的解决办法。
Cloudzy GPU VPS

如果你需要远程 GPU 时间来适配 AI、游戏和渲染工作流,我们的 Cloudzy GPU VPS 包括 NVIDIA 选项如 RTX 5090、A100 和 RTX 4090,加上 NVMe 存储、完整 root 访问权限、高达 40 Gbps 连接、DDoS 保护,以及承诺的 99.95% 正常运行时间。
从监控的角度看,它就像一台普通机器。你可以在 SSH 上运行 GPU 监控软件,为长期任务记录 GPU 指标,还可以添加仪表板来查看历史数据和告警。
如果你还在考虑选择 GPU 实例还是单独的 CPU 配置,我们的文章可以帮你了解 什么是 GPU VPS? 和 GPU 与 CPU VPS 按工作负载类型展示实际差异。
远程监控已经搞定,最后一步是把这些配置整合成可以直接复用的堆栈。
针对每个角色的可复制堆栈
下面是一些开箱即用的技术栈,你可以直接采用,无需重写现有工作流。这些都是不错的起点,之后可以根据具体需求进行调整。
- 模型构建器 (AI/ML): GPU 监控软件通过 nvidia-smi 或 AMD SMI,加上简单的 CSV 日志,以及在任务无人值守时运行的导出程序/仪表板。
- 竞技游戏玩家/主播: GPU 监控软件叠加层,通过 Afterburner + RTSS 实现,包括帧时间捕获工具用于对比,以及最小化的屏幕指标显示。
- 工作站用户 通过 HWiNFO 日志记录使用 GPU 监控软件,加上用于快速身份验证的 GPU-Z,以及仅在能够记录运行时的压力测试。
- 正在运行 GPU 机器的管理员: GPU 监控软件即服务:导出器 + 仪表板 + 告警,加上逐进程可见性(nvtop)用于共享服务器。
如果你只能从本指南中记住一件事,那就是这个:根据你需要数据的位置(覆盖层、日志、仪表板)选择 GPU 监控软件,然后保持指标集足够小,这样你才能真正用上它。