
When NVIDIA showed DLSS 4 generating fifteen of every sixteen pixels with AI, a large slice of the audience didn't see progress. They saw "fake frames" and "AI slop": generated detail that looks right until it doesn't, and that you can't debug the way you'd debug a misplaced polygon. A PCGuide report on a community poll found that 54% of responses were a plain "No" on DLSS 5's look, with much of the criticism aimed at facial features and the "AI slop" reaction. That reaction is worth taking seriously, and we'll come back to it.
But the bigger problem in every one of those arguments is that "neural rendering" gets used for at least five different things: upscaling, AI-generated frames, scene reconstruction from photos, the NeRF and Gaussian Splatting demos you've seen on social media, and the research systems that render a whole image with a single network. People argue past each other because they're each pointing at a different layer and using the same word. NVIDIA's Jensen Huang has called this shift a "GPT moment for graphics." That's the claim. The useful question is what's happening underneath it.
Here's the throughline that makes the whole thing legible: the GPU is increasingly predicting the image instead of computing it. Traditionally, the GPU computes every pixel by simulating geometry, lighting, and materials (rasterization, and more recently ray tracing on top of it). Neural rendering changes what gets computed versus what gets predicted by a trained network. That single distinction is the spine of this article. By the end you'll be able to place any technique on a spectrum, know which ones run in real time and on what hardware, and tell what's shipping in a game today from what's a research paper or a GTC demo. This is a map, not a how-to. The deep mechanics of any single technique are their own articles.
The Short Version
- Neural rendering is a spectrum, not a synonym for DLSS. It spans scene-reconstruction research (NeRF, Gaussian Splatting), real-time components that sit inside the rendering pipeline (DLSS, Ray Reconstruction, neural radiance cache), and generative methods that invent detail the frame never had.
- The throughline is "predict instead of compute." Each technique replaces an expensive computed stage of the pipeline with a network that predicts the result it was trained on.
- Most of what ships today is hybrid. Upscaling, frame generation, and AI denoising run in real-time games now, while neural texture compression and neural shaders are emerging through developer toolkits. Full neural renderers that draw the entire image with a network are still research-stage.
- It's becoming cross-vendor, not just an NVIDIA story. Microsoft's DirectX work on shader-level ML started with Cooperative Vectors in Shader Model 6.9 and is moving toward broader linear-algebra support in Shader Model 6.10, giving engines a path to target neural-style shader workloads beyond one vendor's stack.
Why "Neural Rendering" Means Five Different Things
Neural rendering is a class of methods that use neural networks to predict parts of an image (pixels, lighting, materials, even whole frames) that the GPU would otherwise compute from scratch. The Tewari et al. survey defines it as combining classic computer graphics with deep generative models for photorealistic output. The term spans a wide spectrum, and "DLSS" is one point on it.
The reason the conversation is a mess is that the spectrum has at least three distinct layers, and the public uses one word for all of them.
The first layer is academic / reconstruction neural rendering: NeRF, 3D Gaussian Splatting, and differentiable rendering. These take photographs or measurements of a real scene and learn a representation you can render from new camera angles. The original NeRF paper (Mildenhall et al., 2020) trains a small network to map a 3D coordinate and viewing direction to color and density, then renders novel views by querying it. This layer is mostly offline. It reconstructs scenes; it doesn't power your game's frame loop.
The second layer is real-time pipeline neural rendering: networks that run inside or alongside a normal rasterized frame. DLSS upscaling, Ray Reconstruction, and the neural radiance cache live here. The pipeline still rasterizes and ray-traces; a network handles one expensive stage of it. This is the layer shipping in games today.
The third layer is generative neural rendering: the network produces image content the frame never computed at all. DLSS 4's generated frames sit at the edge of this, and DLSS 5 (which NVIDIA has announced for Fall 2026) pushes further into it by generating lighting and material detail rather than only interpolating between rendered frames.
These three layers behave differently, run at different speeds, and need different hardware. Treating them as one thing is why two people can both say "neural rendering is overhyped" and "neural rendering is the future" and both be partly right.
Section takeaway: The term predates DLSS and is not a synonym for it. DLSS is one application (real-time, in-pipeline) inside a much broader spectrum that runs from offline scene reconstruction to fully generated frames.
How Neural Rendering Is Replacing Parts of the Brute-Force Pipeline
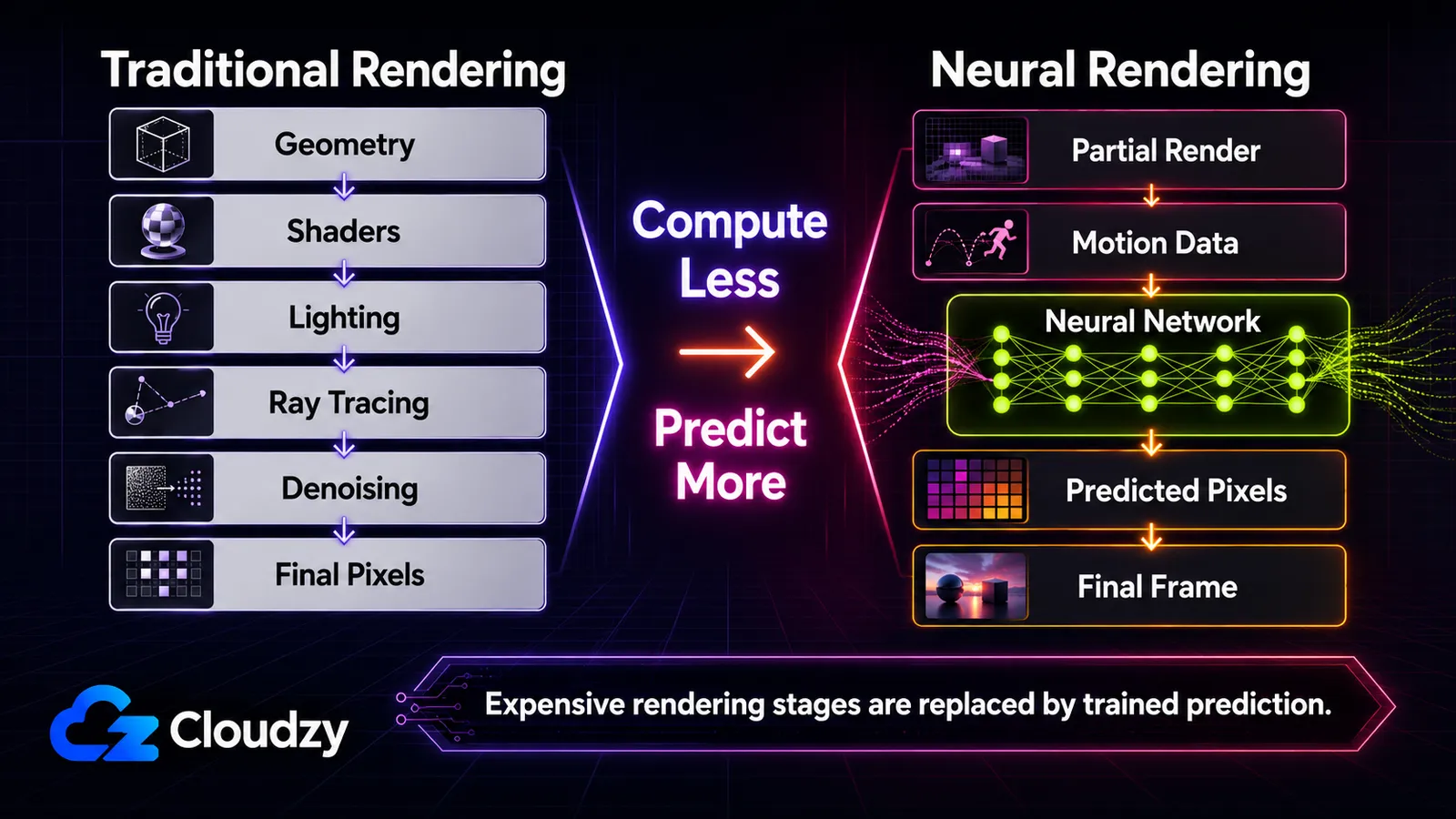
With full DLSS 4 multi-frame generation, roughly fifteen of every sixteen pixels on screen are AI-produced rather than traditionally rendered (per NVIDIA's DLSS 4 figures). That number is the whole shift compressed into one statistic: the renderer computes a fraction of the image and predicts the rest.
Traditional rendering earns every pixel. The GPU rasterizes geometry, runs shaders to compute lighting and materials, and (with ray tracing) simulates light bouncing around the scene. Ray tracing in particular is brutally expensive, because realistic light needs many bounces and many samples per pixel, and the noise from under-sampling has to be cleaned up afterward. As scenes got more ambitious, the most expensive stages became the obvious targets: instead of computing them, train a network to predict their output.
The progression has been steady rather than sudden:
- 2018, DLSS 1.0. The first commercial step: render at low resolution, predict the high-resolution image. Move the upscale from "compute more pixels" to "predict more pixels."
- 2020, NeRF. Scene reconstruction from images via a learned radiance field. Predict novel views instead of modeling and rendering geometry.
- 2021, Neural Radiance Cache. Predict bounced light during path tracing so the renderer can stop tracing early.
- 2022, DLSS 3 Frame Generation. Generate whole intermediate frames instead of rendering them.
- 2023, 3D Gaussian Splatting. A faster, real-time-leaning alternative to NeRF for reconstructed scenes.
- 2025, DLSS 4 + RTX Kit. Multi-frame generation plus a toolkit of neural components (texture compression, radiance cache, neural shaders).
- 2025, DirectX Cooperative Vectors (preview). A cross-vendor API for the matrix math neural shaders need (introduced in preview as part of Shader Model 6.9).
- 2026, DLSS 4.5. Incremental quality and Ray Reconstruction improvements (described by NVIDIA at Computex).
- Fall 2026, DLSS 5 (announced). The next push toward generative neural rendering.
Read top to bottom, each row is the same move applied to a different stage: take something the pipeline used to compute and have a network predict it instead.
The Six Layers: What AI Replaces at Each Stage of the Pipeline
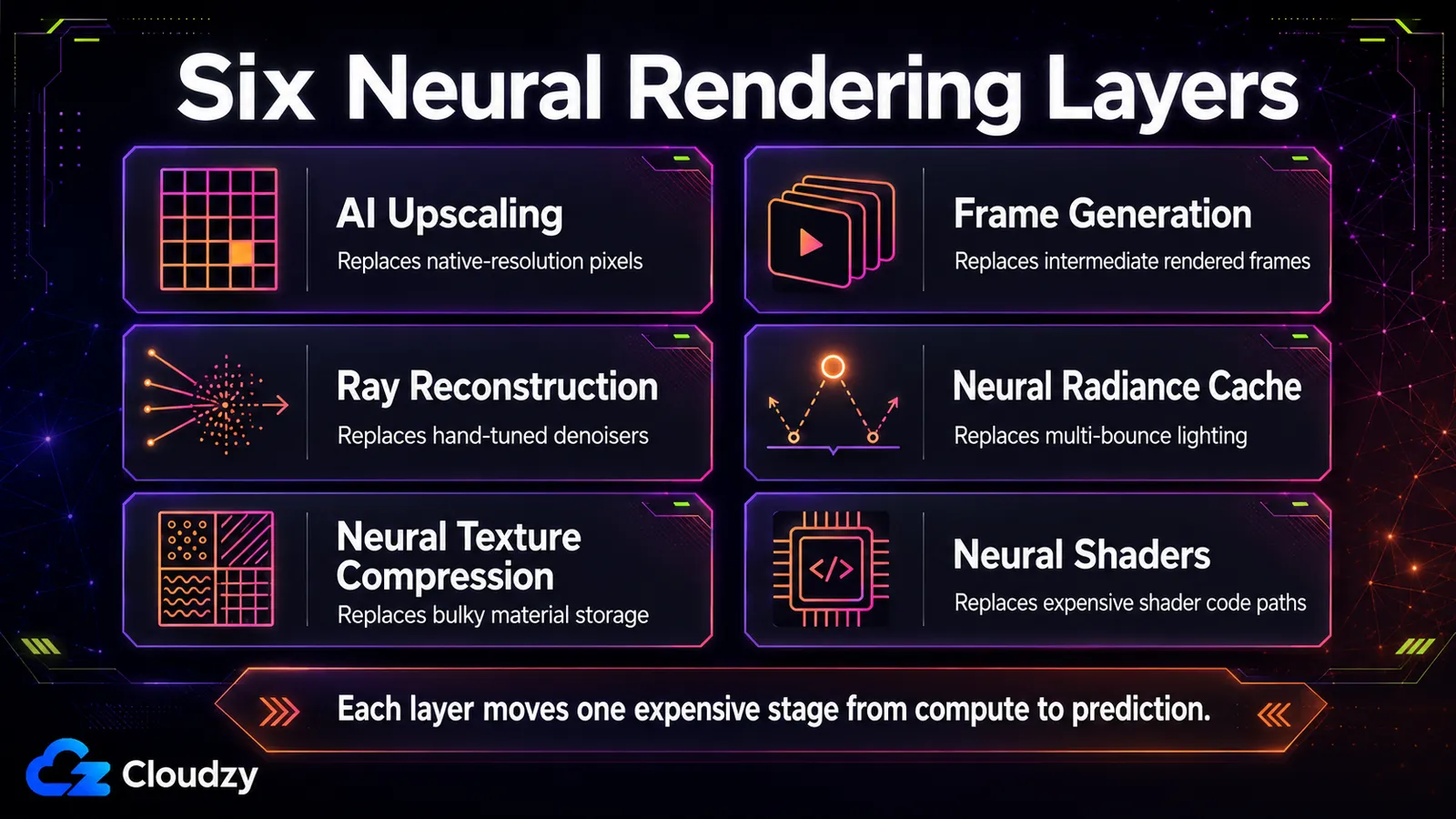
Six techniques carry most of today's real-time neural rendering, and each one replaces a specific computed stage: upscaling (resolution), frame generation (frame count), ray reconstruction (denoising), neural radiance cache (global illumination), neural texture compression (material storage), and neural shaders (in-shader computation). Knowing which stage each one touches is most of the battle.
These split along where in the pipeline the network runs. Some operate at the very end as a post-process on a finished frame; some run mid-pipeline alongside ray tracing; some live inside the shader itself. That location is not a detail. It determines how fast the technique can run and what hardware it needs. The table maps those six techniques; the subsections below explain the mechanism that would not fit cleanly into each cell.
| Technique | What it replaces | Real-time viability | Hardware required | Cross-vendor? |
|---|---|---|---|---|
| AI upscaling (super resolution) | Computing native-resolution pixels | Real-time, low overhead | Tensor / matrix cores (RTX 20+, RDNA 4, Intel XMX) | Yes as a category; implementations remain vendor-specific (DLSS, FSR / FSR Upscaling, XeSS) |
| Frame generation | Rendering intermediate frames | Real-time; adds latency | RTX 40+ (DLSS 3), RTX 50 for multi-frame | Partly; vendor-specific |
| Ray reconstruction | The hand-tuned denoiser stack | Real-time | RTX 20+ | NVIDIA today |
| Neural radiance cache | Computing multi-bounce indirect light | Real-time (~2.6 ms reported) | RTX-class matrix cores | NVIDIA today (RTX Kit) |
| Neural texture compression | Block-compressed material storage | Real-time decode | RTX-class matrix cores | NVIDIA SDK/tooling today; broader shader-level ML support is being standardized separately |
| Neural shaders | Computed shader code paths | Real-time | Shader-level ML / matrix-capable GPUs | Emerging via DirectX SM 6.9 / SM 6.10 path |
AI Upscaling (Super Resolution)
AI upscaling renders the frame at a lower resolution and predicts the high-resolution result, so the GPU draws far fewer pixels and a network fills in the structure. DLSS, AMD's FSR 4, and Intel's XeSS all do this through temporal upsampling: they sample different pixels across consecutive frames and combine that history with motion vectors to reconstruct detail a single low-res frame doesn't contain.
This is the most mature and most widely deployed layer, and it's where the cross-vendor reality is clearest. DLSS 4 moved its upscaler from a convolutional network to a transformer for better detail stability. FSR 4 is AMD's first ML-based upscaler, running on RDNA 4 with FP8 inference rather than the hand-written heuristics of earlier FSR versions. XeSS uses Intel's XMX matrix units. Three vendors, the same underlying idea: predict the pixels you didn't render.
Frame Generation and Multi-Frame Generation
Frame generation predicts entire frames between the ones the GPU actually renders by combining game data such as motion vectors with optical-flow estimation and AI. DLSS 3 used the RTX 40-series Optical Flow Accelerator to insert one generated frame between rendered frames; DLSS 4 Multi Frame Generation on RTX 50-series hardware can generate up to three additional frames per traditionally rendered frame, and NVIDIA says DLSS 4 replaces the hardware optical-flow step with a more efficient AI model.
This is the layer the "fake frames" argument is really about, and the framing matters here. A generated frame is a plausible interpolation of where the scene was going: it shows you usable visual content. But it is predicted, not rendered from the game's actual state, and it doesn't carry fresh game logic or input. Crucially, frame generation runs after a frame is rendered, which adds latency rather than removing it; NVIDIA's Reflex 2 exists specifically to claw that latency back. So "frame generation makes the game faster" is a partial truth: it raises perceived smoothness (more frames displayed) without raising the rate at which the game actually updates and responds. That gap between what you see and what the game knows is the entire debate, and for competitive play, where input latency decides outcomes, it's a trade-off worth weighing.
Ray Reconstruction (AI Denoising)
Ray Reconstruction replaces the stack of hand-tuned denoising filters that ray-traced rendering relies on with a single neural network trained to reconstruct a clean image from noisy, under-sampled ray-traced input. Path tracing can only afford a few light samples per pixel in real time, which leaves the raw output noisy; something has to clean it up before you see it.
The traditional approach was a chain of specialized denoisers, each tuned by hand for a specific effect. Swapping that for one trained network tends to preserve detail the hand-tuned filters smeared, especially on reflections and fine lighting, and it's one network to maintain instead of a brittle pipeline of them. This is a clean example of the throughline: the denoise stage moved from "compute with hand-written heuristics" to "predict with a trained model."
Neural Radiance Cache (Global Illumination)
The neural radiance cache (NRC) predicts how light bounces around a scene so the path tracer can stop tracing most rays early instead of following every bounce to completion. Global illumination (the soft, indirect light that bounces off walls and floors) is one of the most expensive things in real-time graphics, and the mechanism that makes NRC work is rarely explained in plain language, so it's worth slowing down for.
Here's the mechanism. A path tracer normally follows each light ray through many bounces, which is where the cost explodes. NRC trains a small network during rendering (not ahead of time) to predict the light arriving at a point after further bounces. So the path tracer traces a ray for a bounce or two, then asks the network "what's the rest of the light here?" and terminates the path early; the real-time neural radiance caching paper (Müller et al., 2021) reports terminating the large majority of paths this way. Think of it as a cache that doesn't store exact answers it has seen before, but learns the pattern of the scene's lighting well enough to answer queries it hasn't, and keeps re-learning as the scene changes. NVIDIA reports NRC running with roughly 2.6 ms of overhead, which is what makes it real-time-viable rather than a research curiosity.
Neural Texture Compression
Neural texture compression (NTC) compresses all of a material's texture channels together with a network, reaching up to 8x VRAM savings versus traditional block compression at similar visual quality (per NVIDIA's RTX Kit documentation). A modern material isn't one texture. It's a stack of them (color, normals, roughness, metalness, and more), and those channels are correlated in ways block compression, which squeezes each channel independently, throws away.
NTC exploits that correlation. By learning the joint structure across all of a material's channels at once, it stores the same material in far less memory and decodes it on the fly at render time. VRAM is a persistent constraint as games push texture detail, so "fit 8x more material in the same memory" is a direct, practical win rather than a visual gimmick.
Neural Shaders and DirectX Cooperative Vectors
Neural shaders run small neural networks inside a programmable shader (the per-pixel/per-vertex programs the GPU already executes) so a network can approximate an expensive computed effect right where that effect is needed. Instead of bolting AI on as a separate pass, the MLP runs as part of the shader on the GPU's matrix units (Tensor Cores on NVIDIA hardware).
Tensor Cores handle the matrix math these networks run on, distinct from the general-purpose cores that handle the rest of the work. The thing that changes neural shaders from a single-vendor feature into a broader industry capability is the API layer underneath them. Microsoft introduced DirectX Cooperative Vectors in preview with Shader Model 6.9 in 2025 to expose vector/matrix operations inside HLSL shaders. By 2026, Shader Model 6.9 had moved to retail, and Microsoft said Cooperative Vector was being deprecated in favor of a broader linear-algebra design planned for Shader Model 6.10. The safe takeaway is not that Cooperative Vectors are the final API, but that DirectX is moving toward cross-vendor shader-level ML support.
Section takeaway: The six techniques sort by where the network runs: post-process at the end of the frame, mid-pipeline alongside ray tracing, or inside the shader itself. That location is what determines whether a technique can run in real time and which hardware it needs.
What Runs in Real Time, and on What Hardware
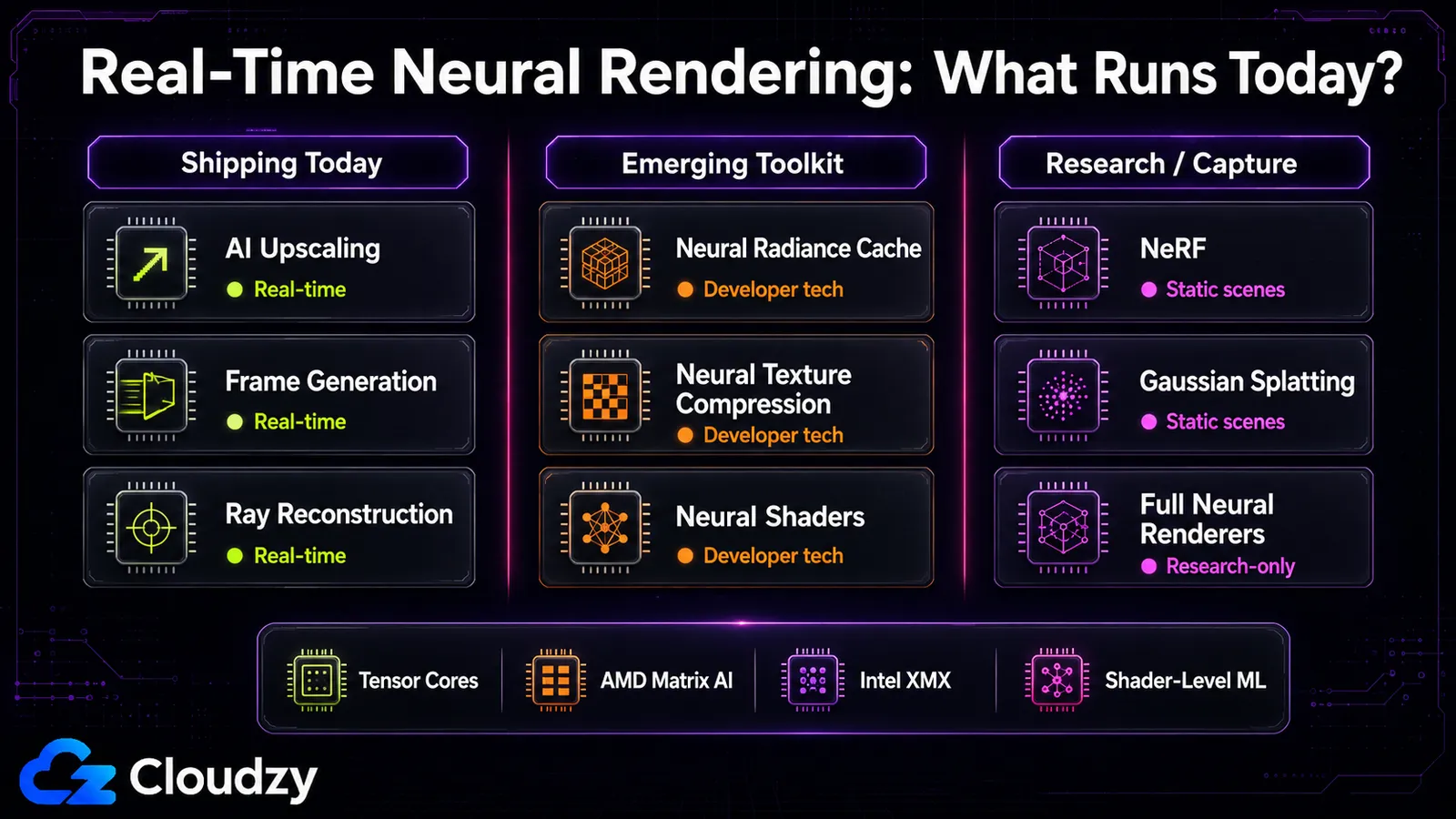
The real-time line is sharper than the hype suggests: AI upscaling usually runs with low overhead, NRC adds roughly 2.6 ms, and 3D Gaussian Splatting approaches real time for static scenes. Original NeRF and full neural renderers like RenderFormer are firmly research-only, taking far too long per frame for interactive use. "Neural rendering is real-time" is true for the in-pipeline layer and false for the reconstruction and full-renderer layers.
That split tracks the spectrum exactly. Some in-pipeline components, especially upscaling, frame generation, and Ray Reconstruction, already run in shipping games. Others, such as NRC, NTC, and neural shaders, are better described as developer technologies and emerging toolkit features rather than common production features. The reconstruction layer is a mixed bag: original NeRF is slow, but 3D Gaussian Splatting was a deliberate push toward real-time and gets there for static scenes. The full-neural-renderer layer (a single network producing the whole image) is where the research lives and the frame times are nowhere near interactive.
Hardware is the other half of the answer, and this is where the cross-vendor story lands. Every technique here runs on the matrix-math units modern GPUs ship for AI inference:
- NVIDIA has Tensor Cores on every RTX card from the 20-series onward, which is why most of these techniques debuted there.
- AMD's ML-based FSR Upscaling currently targets RDNA 4 / Radeon RX 9000-series GPUs for the ML path; on earlier hardware, AMD's SDK falls back to analytical FSR 3.1.5 paths. Treat broader older-GPU support as a moving roadmap item, not a guaranteed FSR 4 feature unless you cite a specific AMD announcement.
- Intel uses XMX matrix engines on Arc GPUs for XeSS.
DLSS itself is feature-gated by generation: upscaling works back to the RTX 20-series, the original frame generation needs RTX 40-series, and multi-frame generation is RTX 50-series only. If you're trying to reason about what a given card can do, that generation gating is the practical answer, not the marketing tier.
What you can use today vs. what's coming: Upscaling, frame generation, and Ray Reconstruction are available in games today. RTX Kit components such as NRC, NTC, and neural shaders are available as developer technologies and tooling, but you should not imply that all of them are already common in shipping games. Gaussian Splatting has usable open tooling for scene capture. What's not here yet: full neural renderers that draw an entire frame with one network, mature cross-vendor neural shaders (AMD support is early), and DLSS 5's generative features (announced for Fall 2026). If you want to experiment with the reconstruction side (running NeRF or inference workloads yourself), that's a GPU compute job, not something your game does for you.
What Neural Rendering Is Not: Five Misconceptions

Most neural-rendering arguments become easier once you identify which layer of the spectrum the claim is about. Five misconceptions come up again and again.
1. "DLSS upscaling is neural rendering." DLSS is an application of neural rendering, the in-pipeline real-time layer, not the whole field. The term predates DLSS and includes NeRF, Gaussian Splatting, and the generative methods. Equating the two is like calling "databases" a synonym for one product you happen to use.
2. "Frame generation makes games faster." It raises the frame count you see, which makes motion look smoother, but it runs after rendering and adds latency. The rate at which the game updates and responds to your input does not increase. For competitive play that latency is a real trade-off; for visual smoothness it's a genuine win. "Faster" conflates the two.
3. "DLSS 5 is 3D-aware / reads the 3D scene." This is the one most worth getting right, because tech coverage keeps mischaracterizing it. As NVIDIA describes it, DLSS 5 takes each frame's color data and motion vectors as inputs, then uses its trained model to infer scene semantics such as characters, hair, fabric, skin, and lighting conditions. It is grounded in the game's content, but NVIDIA does not describe it as reading the game's full 3D scene file directly. "3D-guided" means the inference is geometry-consistent (it respects how surfaces move and relate), not that the network reads scene geometry directly. The distinction matters because it bounds what the technique can and can't know.
4. "NeRF is real-time now." Depends which technique you mean, which is exactly the spectrum problem. Original NeRF is not real-time. 3D Gaussian Splatting approaches real-time for static scenes. Research systems that render a full frame with one network (RenderFormer and similar) are not real-time at all. "NeRF" has become a catch-all for a half-dozen methods with wildly different speeds.
5. "Neural rendering will replace rasterization soon." Today's systems are hybrid: neural components sit inside a rasterization-and-ray-tracing pipeline, not in place of it. Fully replacing the classic pipeline with a single generative renderer is a long-horizon research goal, not a near-term product direction. Take "the future is fully neural" as a direction of travel, not a dated prediction.
Section takeaway: The single root cause of nearly every neural-rendering disagreement is people using the same word for different layers of the spectrum. Locate the claim on the spectrum first, and most of the argument disappears.
Where This Is Going
The trajectory is consistent with everything above: hybrid pipelines today, more stages moving from compute to predict, cross-vendor neural shaders broadening who can ship this, and the full-neural-renderer frontier still years out. The next consumer step is DLSS 5, announced for Fall 2026, which pushes into generative neural rendering by producing lighting and material detail the game never computed, rather than only interpolating between rendered frames. NVIDIA has shown the technology in RTX 50-series contexts, but its final consumer hardware requirements should be treated as unconfirmed until NVIDIA publishes a clear compatibility list.
The forward-look has two halves. On the near side, the move that matters most isn't any single technique. It's the standardization. Microsoft's DirectX path is moving from Cooperative Vectors toward broader shader-level linear algebra, which could let engines target neural-style workloads without betting on one GPU brand. On the far side, NVIDIA researchers have described a far-future endpoint, sometimes floated as a hypothetical "DLSS 10," where the renderer is fully neural and the classic pipeline is gone (reported secondhand from a Digital Foundry roundtable; treat it as a stated direction, not a roadmap). The endpoint of the ladder is a system that generates a coherent world rather than drawing one.
Worth keeping the skepticism, though. Generated detail can diverge from artistic intent, and a network can hallucinate plausible-but-wrong visuals that have no traditional equivalent to debug: a QA problem flagged at GDC 2026, and the substance behind a lot of the "AI slop" reaction. Building for where graphics are going doesn't mean pretending the current output is finished. It means watching which stages move from compute to predict next, and judging each one on what it does to the image rather than on the word attached to it.
Frequently Asked Questions
Is DLSS Neural Rendering?
Yes, but it's only one kind. DLSS is an application of neural rendering: specifically the real-time, in-pipeline layer, covering AI upscaling and frame generation. The broader term predates DLSS and also includes scene-reconstruction methods like NeRF and Gaussian Splatting and generative methods that invent new image detail. So every DLSS feature is neural rendering, but plenty of neural rendering isn't DLSS.
What Is the Difference Between Neural Rendering and Ray Tracing?
Ray tracing simulates light by computing how rays bounce through a scene; neural rendering predicts results from a trained network instead of computing them. They aren't rivals. They combine. Ray Reconstruction, for example, uses a neural network to denoise noisy ray-traced output, and the neural radiance cache predicts bounced light so the ray tracer can stop early. Neural techniques make ray tracing affordable in real time.
Does DLSS Frame Generation Add Latency?
Yes. Frame generation runs after a frame is rendered and inserts predicted frames between rendered ones, which adds latency rather than removing it: NVIDIA's Reflex 2 exists specifically to compensate. It increases perceived smoothness (more frames displayed) without increasing how fast the game updates and responds to input. For competitive play that's a trade-off; for single-player smoothness it's usually a net win.
Is NeRF Real-Time?
It depends which technique you mean. The original NeRF is not real-time. 3D Gaussian Splatting, a later method, approaches real-time for static scenes. Full neural renderers that draw an entire frame with one network are research-only and far from interactive speeds. "NeRF" is often used loosely to cover several methods with very different performance, which is the source of most of the confusion.
Will Neural Rendering Replace Rasterization?
Not soon. Today's systems are hybrid: neural components run inside a rasterization-and-ray-tracing pipeline, not instead of it. Replacing the classic pipeline entirely with a single generative renderer is a long-horizon research goal, not a near-term product. The realistic direction is more pipeline stages moving from computed to predicted over time, with rasterization still doing real work for years.
What Is Neural Texture Compression?
Neural texture compression (NTC) is a neural method that compresses all of a material's texture channels together (color, normals, roughness, and the rest), reaching up to 8x VRAM savings versus traditional block compression at similar visual quality, per NVIDIA. It works by learning the correlations across channels that block compression, which squeezes each channel separately, discards. The compressed material is decoded on the fly at render time.


