
Swap GPT-5 for Claude inside a working agent and, most of the time, the thing barely changes. Change how it handles retries, or what you feed into its context window, or when it decides to stop, and the whole agent behaves differently. That gap is the tell: the model is the smallest, most swappable part of a working agent. The interesting engineering lives in everything wrapped around it.
That wrapper has a name now. Practitioners landed on "harness" for the layer that turns a text generator into something that takes actions over time rather than running a fixed script. The term spread fast across Twitter and engineering blogs in early 2026, which means it also got used loosely, with the same word doing slightly different work in every post you read. This article pins it down: what a harness is, what it's made of, how it differs from a "framework" and a "scaffold," and why most of your agent's quality is hiding in the harness, not the model.
The Short Version
- An agent harness is the software around an LLM that manages the execution loop, tools, memory, context, state, error handling, and guardrails. The model generates text; the harness decides what the model sees, what it can do, when to stop, and what happens when something breaks.
- In production, the model call is often the smallest visible part of the system surface area. A weaker model in a well-built harness can beat a stronger model in a sloppy one, especially on long-running, tool-heavy tasks.
- A harness has roughly nine to eleven recurring components. Most of them are things the model never touches directly.
- "Harness" is not the same as "framework." A framework (LangGraph, an agents SDK) is the library you build with; the harness is the running layer that library helps you assemble.
What Is an Agent Harness?
An agent harness is the software infrastructure surrounding a language model that manages the execution loop, tool access, memory, context, state persistence, error handling, and guardrails. The model generates text. The harness decides what the model sees on each turn, what actions it can take, when it stops, and what happens when a step fails.
The cleanest framing comes from LangChain, who reduce it to an equation: Agent = Model + Harness. The model contributes the intelligence. The harness is what makes that intelligence do anything in the world.
"A harness is every piece of code, configuration, and execution logic that isn't the model itself."
— LangChain, The Anatomy of an Agent Harness
I find the boundary easiest to feel through one question: when your agent does the wrong thing, was the model's own reasoning wrong, or did the system around it hand the model the wrong context, the wrong tools, or no way to recover? Most of the time, on a real system, it's the second one. The model reasoned fine over garbage inputs. The harness is what controls the inputs.
Key takeaway: The model generates; the harness governs. That split is the whole concept.
What Are the Components of an Agent Harness?
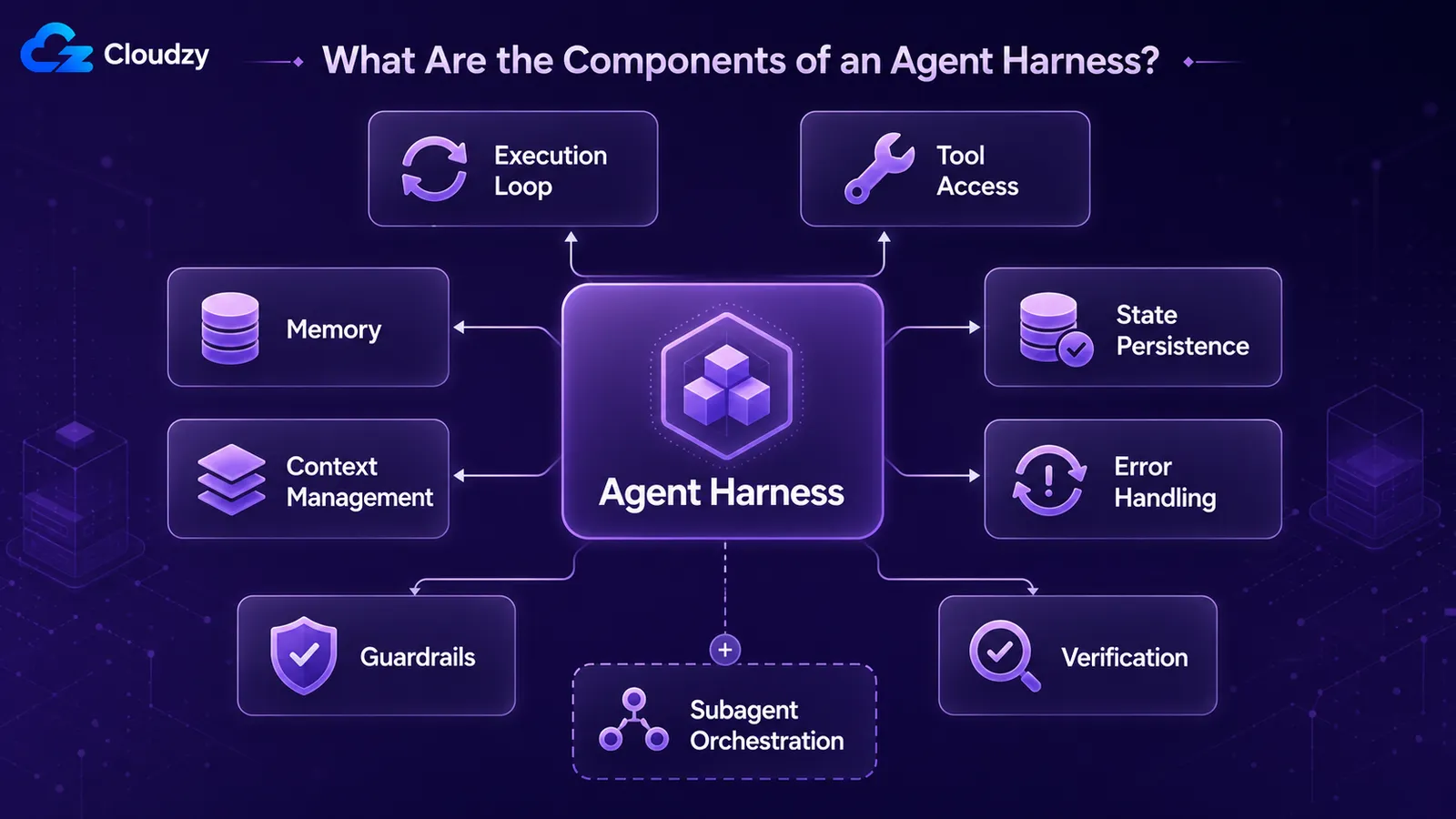
Every production harness assembles the same recurring parts: an execution loop that drives the model turn by turn, tool access that lets it act, memory across turns, context management for what it sees right now, state persistence so work survives across sessions, error handling for failed steps, and guardrails that constrain what it can do. Production systems add verification loops and subagent orchestration.
A useful inventory, drawn from how practitioners describe real systems:
- Execution / control loop: the thing that drives the agent turn by turn. Call the model, read its output, run any tool it asked for, feed the result back, repeat until a stop condition.
- Tool access: the functions, APIs, code execution, and filesystem the model can reach.
- Memory: what the agent retains across turns and across sessions.
- Context management: what gets packed into the model's window on each turn, and what gets compacted out when it overflows.
- State persistence / checkpointing: saving the agent's state so a crashed or paused run can resume.
- Error handling: retries, fallbacks, and recovery when a tool call or a model call fails.
- Guardrails: limits on what the agent can do, such as allowed tools, step caps, and output validation.
- Verification loops: having the agent (or the harness) check its own work before calling it done.
- Subagent orchestration: spawning, delegating to, and collecting from sub-agents on bigger tasks.
Not all of these are universal. The execution loop, tools, context handling, and error handling show up in even a weekend prototype. State persistence, verification, and subagent orchestration are where prototypes and production systems split. A prototype can skip them; a long-running production agent cannot. Anthropic's writeup on long-running agents is a tour of the production-only parts: how an agent rebuilds its understanding from a progress file after its context window resets, and how testing gets wired into the loop.
For anyone who wants the academic bridge, a recent survey of agent architectures folds this same machinery into a smaller formal tuple of core components. The practitioner list and the survey's framing are two zoom levels on the same structure: the survey compresses, the inventory above expands. Treat the nine-to-eleven count as the components most production harnesses share, not a ratified standard; the field hasn't ratified anything yet.
Key takeaway: Most of an agent's moving parts live in the harness, not the model. The model is one component among many.
Why Does the Harness Matter More Than the Model?
A weaker model inside a well-engineered harness frequently outperforms a stronger model in a poorly designed one. The reason is mechanical, not magical: end-to-end agent reliability is the product of every step's reliability, and most of those steps (tool selection, context assembly, error recovery) are the harness's job, not the model's. Improve them and the whole chain gets more reliable, regardless of which model sits inside.
The arithmetic makes it concrete. Suppose each step in a ten-step task succeeds 99% of the time. End-to-end success isn't 99%. It's 0.99 to the tenth power, about 90%. Push each step to 99.9% and end-to-end jumps to roughly 99%. Per-step reliability compounds, and per-step reliability is overwhelmingly a harness property. That is why squeezing error handling and context management pays off more than swapping in a model half a point better on some benchmark.
There's production signal pointing the same way. MongoDB, citing Vercel's case study, reports that Vercel cut the bulk of their agent's tools and watched its success rate climb sharply on the same model, with a smaller and cleaner harness. Read it as convergent evidence rather than proof: it's one production case, not a controlled experiment, but it points the same direction as the compounding arithmetic and the survey work above.
This is the heuristic I keep coming back to as a platform engineer: context is the bottleneck, not raw model capability, and scaffolding built to paper over today's model gaps tends to get eaten as models improve. Build the durable parts of the harness (the loop, the state, the recovery) and let the model underneath get better on its own schedule.
Key takeaway: When your agent fails, suspect the harness before the model. The odds favor it.
What's the Difference Between a Harness, a Scaffold, and a Framework?
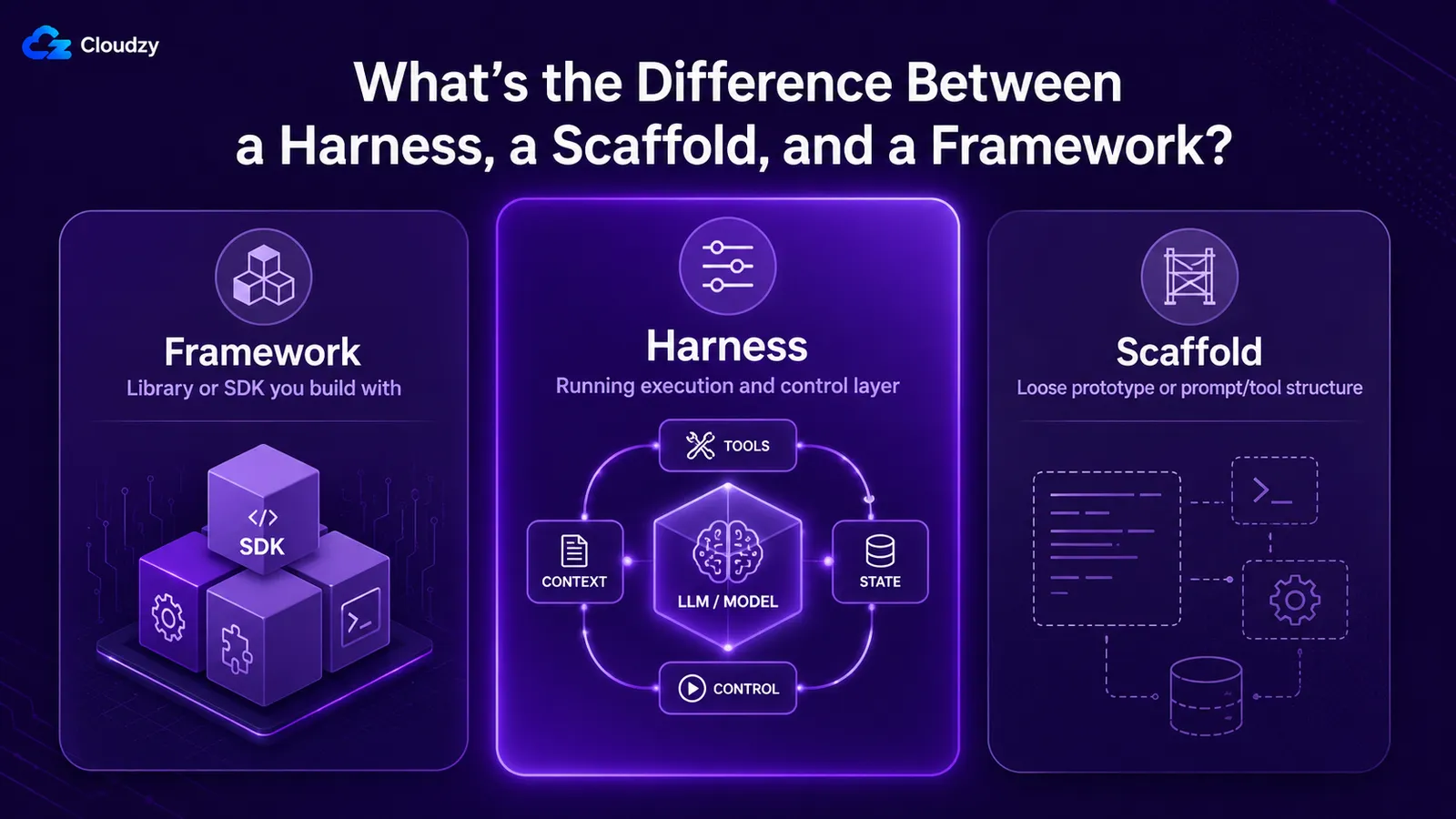
These three get used interchangeably, and they shouldn't be. A framework is the library or SDK you build with, such as LangGraph or an agents SDK. A harness is the running execution-and-governance layer around the model, which a framework helps you assemble. A scaffold is the loosest of the three: sometimes a near-synonym for the harness, sometimes the prototype-grade version of one, sometimes the prompt-and-tool-description layer specifically.
The vocabulary is genuinely unsettled, and the cleanest thing to do is map the usages rather than legislate one. HuggingFace's Agent Glossary says so directly:
"Many of these terms don't have universally accepted definitions yet, and different frameworks use the same word differently."
— HuggingFace, Agent Glossary
| Term | What it refers to | Relationship |
|---|---|---|
| Framework | The library or SDK you build with (LangGraph, an agents SDK) | A tool for assembling a harness |
| Harness | The running layer around the model: loop, tools, context, state, guardrails | What you ship and run |
| Scaffold | Loosely used: a near-synonym for harness, or the prototype-grade / prompt-layer version | Overlaps with harness; less precise |
| Loop | The execution cycle inside the harness | A component of the harness |
The practical upshot for reasoning about your own system: when someone says "framework," ask whether they mean the library or the running thing. When someone says "scaffold," ask whether they mean the whole harness or just the prompt-and-tool layer. The disambiguation is the value here, not a claim to the final word.
How Does LangGraph Implement the Harness Pattern?
LangGraph is a popular open-source Python implementation of the harness pattern. It models agent execution as a directed graph of nodes and edges, with typed state flowing between them and every transition checkpointable. If the abstract components above feel slippery, LangGraph is a place to see them take concrete shape in a real tool.
The mapping is close to one-to-one. The nodes and edges are the execution loop: each node does work, each edge decides where control goes next. The typed state object passed between nodes is the context-and-state component made explicit. Checkpointing (LangGraph persists state through savers like its Postgres-backed one) is the state-persistence component. A configurable step limit is a stop-condition guardrail, keeping a misbehaving agent from looping forever. Same components, named and wired by a specific library.
If you want to run a LangGraph agent on your own server, around the clock, that's a deployment question rather than a conceptual one. See our Linux VPS guide for that path. Here, LangGraph is just the worked example: proof that "execution loop," "state persistence," and "guardrail" aren't abstractions, they're things you can point at in real code.
Frequently Asked Questions
What Is an Agent Harness?
An agent harness is the software around a language model that turns it into an agent. It manages the execution loop, tool access, memory, context, state persistence, error handling, and guardrails. The model generates text; the harness decides what the model sees, what it can do, when to stop, and what happens when something fails.
Is an Agent Harness the Same as an Agent Framework?
No. A framework is the library or SDK you build with, such as LangGraph or an agents SDK. The harness is the running execution-and-governance layer around the model (the loop, tools, context, state, and guardrails) that a framework helps you assemble. You use a framework to build a harness.
What Components Does Every Agent Harness Have?
Most harnesses share a recurring core: an execution loop, tool access, memory, context management, state persistence, error handling, and guardrails. Production harnesses add verification loops and subagent orchestration. Prototypes can skip the production-only parts, but the loop, tools, context handling, and error handling show up almost everywhere.
What Does "The LLM Is the Smallest Part of Your Agent System" Mean?
It means most of an agent's behavior and reliability come from the harness, not the model. End-to-end reliability is the product of every step's success rate, and most steps are harness work. MongoDB, citing Vercel's case study, reports a success-rate jump from harness changes alone, on the same model. That is evidence that fixing the harness outperforms fixing the model.
Where Your Agent's Quality Lives
The harness is where most of an agent's quality lives, and you now have the vocabulary to locate problems in your own system. You can define a harness, name its components, tell it apart from a framework and a scaffold, and reason about whether a given failure is a model problem or a harness problem.
So the next time your agent misbehaves, audit the harness layer first: the context you're feeding it, the tools you've exposed, the stop conditions you've set, the way it recovers from a failed step. Reach for a bigger model only after that layer checks out. Most of the time, it won't.


